書體與漢字的區別

子曰:「君子於其所不知,蓋闕如也。名不正,則言不順;言不順,則事不成。」
說的是凡做事比先正名(名分)。名分定了,其言論才通順合理,事情才能辦成,法理也才能深入人心。
借用至聖先師的思想,我們可以進一步引申:但凡做學問的,必須先把各種名詞定義淸楚妥當,以免他人混淆或者偷換概念。
而我們研究漢字的,必須弄淸楚兩个概念——書體和漢字。
前者(書體)是書法裏頭的概念,是指同一个漢字由不同的手書所形成的書寫風格。
後者(漢字)是文字學概念,是指有其獨立的字音、字形(主要看構字部件及其佈局)、字義的文字,竝且區別於其他字。
簡單來說,漢字是一个抽象的稱謂,表達的是由構字部件組成的含有獨立音形義的文字;而書體則是漢字字形的具體表現形式,同一个漢字可以寫成不同的書體,但是仍然認定爲同一个字(在文字學意義上)。


(引用自
简化字 - 汉字 - 知乎专栏)
如上圖所示,這裏所列出來的都是「請」字的不同書體,但是表示的都是「請」這个字。
@波斯基曰:
我们甚至可以认为「說」、「説」、「说」是同一个字的不同书体写法,是同一个字的三种不同书写风格,是同一个字的三种不同字形风格;但从字形、字构的角度看,这就是同一个字。
其說甚是。
做一个簡單的類比:
漢字 ↔ 水(抽象的物質概念)
書體 ↔ 水(具體存在形式,如水蒸汽、液態水、冰等)
※※※※※※※※※※※※※※※※※※※※※※※※※※※
可惜的是,這麼一个簡單的道理,很多人仍然不明白。他們往往混淆把書體區別誤認爲是漢字的區別,然後覺得「說」和「説」是兩个不同的漢字。
我覺得造成這種誤會,Unicode 組織負有不可推卸的責任。
Unicode 是致力於對世界上大部分的文字系統進行整理、編碼的業界標準。他們在整理中日韓越共同使用的漢字( CJKV 統一表意文字)的初期,發現各地字形有微妙的差異(如日本的「戸」,大陸、香港的「户」,臺灣的「戶」),於是便提出了字源分離原則。字源分離原則是指,在中(含港臺)日韓越等字源裏,若有任何字集同時收了兩種以上的文字字形,則在 Unicode 中日韓統一表意文字中,也同時收錄這些字。
但是這麼做,破壞了「只對字,而不對字形」編碼的原則,竝且在實際實施起來十分困難。
例如同一部件,有分有合,原則不一致。
「値」「值」分開編碼,而「直」則共用一个編碼(日本字體把「直」顯示成「値」右)。
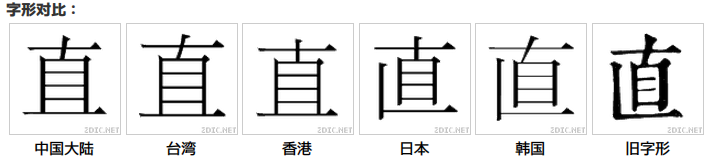



總而言之, Unicode 在哪些字形該對應同一个 Unicode 碼位,哪些字形該分開編碼上,表現得十分糟糕。
但是爲了版本向下兼容,這種已經編碼的部分是不能更改的,所以這種 bug 被保留了下來。當然有文件整理這種 bug :未統一漢字列表。
後來 Unicode 學聰明了,創造性地發明了兼容表意文字區。這樣,把各國提交上來的本是同一个漢字,但是表現爲不同字形的 Glyph ,都統統塞入兼容區,只在基本區裏面留一个通用。(關於這部份的實例可參攷梁海的這篇回答为什么 Unicode 中会存在「凉」和「凉」这样两个极其相像的字符?)
喜歡用奇葩字的日本國,總共提交了三个「逸」字。他們分別是:
逸(U+9038),逸(U+FA25),逸(U+FA67)。
他們用日本字體(明瞭體)是這麼顯示的:
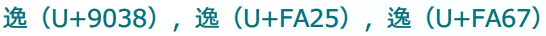

※※※※※※※※※※※※※※※※※※※※※※※※※※※
由此我們可以看出,對於區分兩个字形是不是同一个漢字的問題,我們通過 Unicode 是否分開收入來作爲評判標準,顯然是不合適的。
有人提出這樣的問題汉字的数量有多少?
下頭的回答是「汉字的数量并没有准确数字,大约将近十万个(北京国安咨讯设备公司汉字字库收入有出处汉字91251个),日常所使用的汉字只有几千字。」
這顯然是受到 Unicode 字符集影響的。事實上漢字數量沒有這麼虛髙。
通過一些由國家和地區而不是 Unicode 制定的字符集(這些字符集不攷慮其他國家和地區的字形,也就不會收入冗餘字)。我們可以看到:
JIS X 0208(日本標準)收入漢字數量6355个
GB2312(中國大陸標準)收入漢字數量6763个
Big5(臺灣標準)收入漢字數量13060个
再加上中國大陸2013年推出的《通用規笵漢字表》收入字數8105个(含地名、人名僻字)
我們可以保守估計應用於現代漢語、日語的漢字數量,大約是1.5萬左右。(此処我們不攷慮地區字形、簡繁帶來的差異。這種差異我們視爲書體差異而不是漢字差異。)
若是加上康熙字典的49030个字。所有出現過的漢字數量應該是6~7萬,不會超過十萬。(大致數量略小於這篇文章所統計的,因爲對於生僻字 Unicode 的收入標準比較嚴格。而在常用字字符集,Unicode 的字數才明顯虛髙。)
以上內容節選自筆者(@趙瑾昀) 的回答印刷體(宋體、明朝體)是如何產生的?片段,作爲筆者的第一篇專欄文章,稍有增改。
