
使用表型筛选发现全新的抗体药物及靶点:能否摘下挂的最高的抗体药物果实?

这篇文章被一个叫“求实药社”的公众号抄了,我的公众号是who言药语
两种新药发现的方式
全新药物(First-in-class)药物发现有两种主要的方式,一种是以靶点为基础的药物研发(Target-based drug discovery,TDD)。这种方法是基于对疾病和靶点机理的理解,针对某一个和疾病机理高度相关的特定的靶点,从而有针对性的设计大分子或小分子药物的研发方式。在过去的三十年间,这是最常用的新药发现方式。另外一种是基于表型筛选的药物发现(Phenotypic drug discovery, PDD), 这种药物发现方式不依赖于对靶点和机理的理解。它的起点是一个化合物库或者抗体库,用一个和疾病高度相关的临床前模型或者实验来筛选库中的药效,找到达到期望药效的分子再进一步优化和开发。同时,尝试寻找这个分子的靶点和机理到底是什么。当然这不是必须的,阿司匹林到现在还不知道靶点是什么呢。简单来说,表型筛选的药物发现方法就是制药里面的神农尝百草。图一总结了TDD和PDD的基本研发流程的差异。一个是靶点----筛选----确认功能----疾病模型进一步验证;一个是筛选-----确认功能-----疾病模型进一步验证----靶点研究。
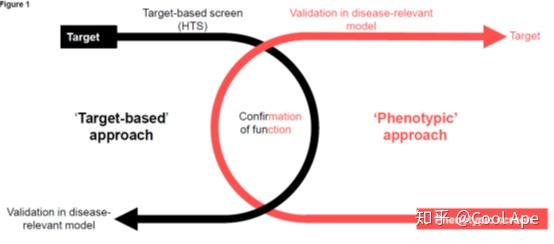

TDD和PDD各有优缺点,基于靶点的药物发现TDD优点在于因为靶点和机理已知,所以很容易设计高通量的筛选试验,而且过去三十年间,有大量成功的案例,而缺点在于由于靶点一般来自于理想模型的机理研究,所以真的回到人体环境的疾病中,这个靶点可能根本不相关; 很多报道的靶点无法在实验室中重复出来;一般这样的靶点都是单一、简单的原理,在复杂的疾病中很容易被代偿绕过去。像NASH或者肿瘤微环境这样多细胞多通路参与的,有无数文献看起来极其有潜力的靶点,死在药物开发的各个阶段。还有一点就是已验证的好靶点数目是非常有限的,所以会造成很多家公司在竞争同样的靶点。就像Nextcure报道一个Siglec15几例患者的阳性数据,全国多少家药企闻风而动?
而基于表型筛选的药物发现,优势在于筛选出来的药物靶点直接和疾病生物学模型相关(因为就是拿疾病生物学模型筛到的),而且一次筛选筛到的几个药物可能针对多个靶点,多种机制。这些靶点很可能是全新的,所以潜在的竞争要少很多。但它也有自己的问题,比如靶点和机理未知在后面进一步开发的时候可能会有困难,尤其找到已经筛选到的药物作用的靶点实际是个非常有挑战性的工作,即使找到了靶点,进一步的靶点验证可能还是必须的。

PDD的“库”与筛选实验模型
表型筛选的核心在“筛”,为了“筛”到一个有效的分子,你需要有一个多样性很大的分子库,从而提供足够多的候选分子;你还需要一个良好设计的筛选试验,它需要和疾病高度相关,可以高通量进行;并且筛选敏感度适中,筛孔既不太大导致太多的假阳性候选分子,也不太小让你晒不到东西。简单点说就是你既需要“百草”,也需要足够能吃足够敏感的“神农”。
先说百草,对于小分子来说,化合物库已经非常成熟了。比如动植物毒素库,天然产物库,药物类似化合物库等等等等。而抗体库从哪儿来,一直是业界没有解决的问题,这样制约了使用PDD策略发现抗体药物的研究进展,一直到近几年才有了一些可喜的尝试,这些后面都会说到。
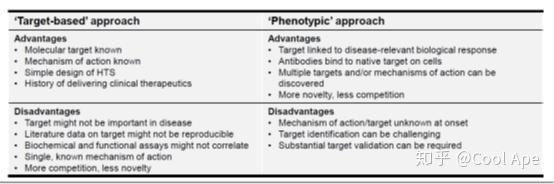
再说神农,什么样的assay才是最relevant的assay? 每一种疾病可能都不太一样,和疾病生物学更相关assay可能通量不够大,敏感度不够高。所以一个好的初筛assay,需要平衡的方面很多:生物学相关性,敏感度,成本,可重复性等等。一个可以考虑的策略是使用基于靶点的药物开发中使用过的,证明高度相关的assay。比如说免疫调节功能的表型筛选,就用外周血PBMC混合淋巴细胞的细胞因子释放试验来筛。这个实验的相关性和有效性毋庸置疑,唯一一点就是不同的PBMC donor, 效果可能不太一样。作者和同事曾经捐献自己的PBMC来做CAR-T的药效试验,后来发现某位刘博士T细胞激活后猛的很,哐哐分裂。后续就是我们羊毛逮着一个薅。这也是个策略。图二讲了什么样的筛选试验和疾病生物学最为相关。但用作表型筛选,需要考虑的方面远远不止疾病生物学相关性。

使用表型筛选策略发现抗体新药:抗体库的构建
刚才提到了抗体库构建的难度。其实噬菌体展示库,酵母展示库都是容量很大的抗体库,而且技术也成熟了,但这两个抗体库用于表型筛选有个大问题,它们都不是一个个单独存在的成熟的抗体,没办法扔到assay里面去过筛子。现在的抗体库构建,很多人采用的是针对某种特定的细胞类型,建立抗体库。比如拿多发性骨髓瘤细胞去免疫小鼠,从而得到的多发性骨髓瘤高度相关的抗体库;比如拿人的PBMC去免疫小鼠得到人免疫相关抗体库。另外一个新的策略是用自然界天然存在的各种多肽序列片段,来大量免疫小鼠,从而得到一个针对大量不同表位的抗体库,这种抗体库理论上比细胞特异抗体库具有更广的应用空间。还有一个例子是从病人尤其是细菌、病毒感染后康复的病人身上分离B细胞,从而构建针对某种病菌的抗体库,这就和我们对抗最近面对的最大敌人:COVID-19,息息相关。
使用表型筛选发现抗体新药和靶点的例子
其实在上世纪70、80年代,单克隆抗体技术刚被开发出来的时候,有很多人在做类似表型筛选的尝试,比如用疾病组织和健康组织去免疫小鼠,免出几十个抗体,然后就用这些抗体去染疾病组织和健康组织,找到那些能够特异识别疾病组织的抗体。当时发现的一系列肿瘤特异抗体识别的靶点,慢慢的被鉴定或命名。像黑色素瘤的相关抗原GD3, 前列腺癌的相关抗原PSMA都是用这种方式发现的。当然那时候的抗体库都极小,而且没有和制药挂钩,很难称得上是PDD。
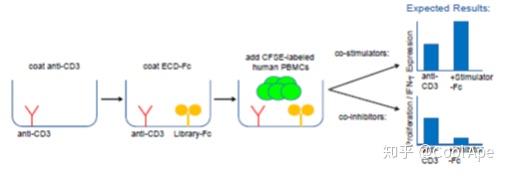
2015年的时候,我看到了Five-Prime公司的一个很有趣的Poster。当时业界还沉浸在PD-1成功的余波里,所有人都希望能够找到下一个PD1。于是他们设计了一个非常聪明的表型筛选模型:他们把人类的膜蛋白都做成了Fc融合蛋白,然后在孔板里每孔都包被了anti-CD3抗体,来作为一级刺激信号激活T细胞,然后每一孔里也包被上不同的Fc融合膜蛋白。然后他们把人或鼠的PBMC标上CFSE用以观测增殖。把标好的PBMC培养在包被了CD3抗体和重组蛋白的孔板里几天,最后和对照比较PBMC的增殖。如果增殖增加了,说明这个膜蛋白可能是个共刺激信号靶点,类似41BB,如果增殖降低了,那说明可能是个共抑制信号靶点,搞不好是下个PDL1。流程具体见图三。15年那个Poster里面,他们找到了一个全新的共抑制靶点,但没有透露靶点身份,也不知道后续是否推进下去了。因为找到了靶点,功能也确认了,重组蛋白免疫原也有了,理论上可以直接进入抗体开发了。

如果说上面这个例子是使用蛋白库来进行表型筛选,只能选到靶点,那下面的例子就是标准的用抗体库进行表型筛选,同时找到了靶点和抗体。这是2017年的一篇Nature Medicine (. 2017 Dec;23(12):1436-1443),作者想找一个除了BCMA外的多发性骨髓瘤的CAR-T靶点。CAR-T靶点的要求简单来说就是健康组织低表达,癌组织高表达的膜蛋白。他们的方法是第一步,先用好几种不同的多发性骨髓瘤细胞系免疫出来>10000个单抗克隆。后面他们加了两个筛子,第一个是检测这些单抗识别不识别健康人的PBMC,如果识别,扔掉这个抗体;不识别,进入下一轮筛选。就这样,在这第一个表型筛选assay里面,他们筛掉了9500个克隆,还剩下500个进入了下一轮。下一个筛子他们分离了多发性骨髓瘤病人的骨髓,看这500个克隆是否可以特异性结合病人的骨髓瘤细胞,而不结合病人骨髓中的正常CD45+白细胞。这一轮下来,他们只找到了一个克隆:MMG49(图四,左)。后面他们又做了一系列的验证,确认了MMG49识别的是一个好的CAR-T靶点,然后鉴定出来这个靶点是激活的integrin β7。在多发性骨髓瘤细胞中,Integrinβ7 是激活构象;而在正常白细胞中,这个蛋白是失活构象 (图四,右),使得这个抗体可以特异的识别多发性骨髓瘤细胞,而不结合正常白细胞。这就很好的说明了抗体表型筛选的优势,如果你按部就班的去用重组蛋白免疫小鼠,是不可能找到这样的全新构象表位靶点的。他们怎么鉴定出来靶点的也是这篇文章的一个亮点,不是用的传统的IP加质谱手段,而是把多发性骨髓瘤细胞系的cDNA文库构建成慢病毒库,然后用慢病毒库又感染细胞做成了过表达细胞库,然后用MMG49去富集分选阳性细胞,阳性细胞去测序鉴定到底过表达了哪个蛋白。当时看得我啧啧称奇,感兴趣的朋友可以自己下载研究下这篇论文。


下一个例子来自近期发表在Science Advances上的一个研究研究者使用了400多种物种的3000多种蛋白质的15000个线性表位,合成了多肽,通过30000+万只小鼠的免疫、骨髓瘤细胞融合和筛选,最终形成了一个具有高度多样性、经过亲和力成熟的抗体库(图五)。而这个抗体库与其说识别的是各种各样的蛋白,不如说识别的是各种各样的表位。研究者把这6万多个抗体点制成了抗体芯片,这样可以实现针对某种特定的蛋白组,一次筛选6万多个抗体的结合。约翰霍普金斯大学的朱衡教授对这篇文章进行了点评,认为这个芯片代表了目前抗体芯片的最高水平。
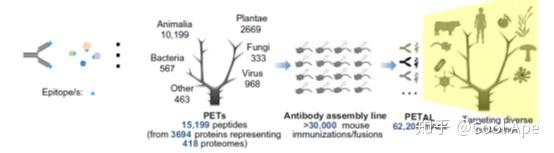

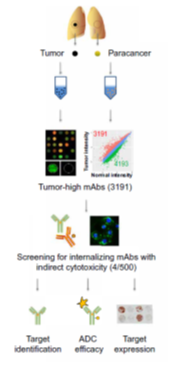
文中研究者开发了一个使用这个抗体芯片筛选肿瘤ADC靶点的技术流程,ADC靶点的要求是1肿瘤高表达,2健康组织低表达,3抗体结合靶点后可以内吞并进入晚期溶酶体。针对这几个特点,作者设了两个筛子。实验的大体思路是把肺癌病人的癌组织和健康癌旁组织提取蛋白,标记荧光和抗体芯片孵育。这样就能找到一些抗体只在癌组织里有荧光信号,这些抗体识别的靶点可能是癌组织特异表达的抗原。这一道筛子过完,候选抗体从60000个,减到了3000多个。第二道筛子使用的是内吞相关的assay。用偶联了毒素的二抗,和上一轮筛选出来的每个候选抗体分别加到肿瘤细胞培养基中,如果这个候选抗体可以被内吞,并且进入了晚期溶酶体,那么连毒二抗就会跟着进去,释放毒素,杀死肿瘤细胞(图六)。通过这种方式,作者筛到了一个针对CD44v9的单抗,具有很干净的表达谱,快速内吞,并且显示了很好的ADC体外体内药效。
总结和展望
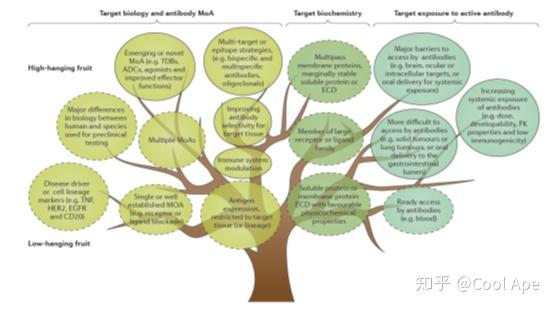
2018年Nature Review杂志发了一篇药物研发的综述,题目叫做“Next generation antibody drugs: pursuit of the ‘high-hanging fruit’”在这篇文章中,他们画了一棵“抗体树”(图七),越高的地方挂的果实(抗体药),越难以开发但也越有意义。这里面包括这么几个:全新的MOA, 特殊表位,多次跨膜蛋白靶点。这几个都是基于靶点开发抗体极端困难,或根本无处下手。使用表型筛选策略,则有可能解决这些问题。上面提到的这些成功抗体库开发策略,如果能够结合这几年高度发展的单B细胞测序和高通量的抗体表达技术,很有可能在未来的几年,把大规模抗体库构建的成本降下来。从而真正的实现基于表型筛选的抗体新药发现。摘下抗体新药研发中挂的最高的果实。

引文
图(一)表(一):Drug Discov Today. 2016 Jan;21(1):150-156
图(二):Nat Rev Drug Discov. 2017 Aug;16(8):531-543
图(三)https://www.fiveprime.com/file.cfm/16/docs/IO_2015_11_SITC_Poster_TCR_Sallee.pdf
图(四):Nat Med. 2017 Dec;23(12):1436-1443
图(五)图(六):Science Advances 11 Mar 2020: Vol. 6, no. 11, eaax2271
图(七):Nat Rev Drug Discov. 2018 Mar;17(3):197-223
