
【数学】一只兔子帮你理解 kNN


导语:商业哲学家 Jim Rohn 说过一句话,“你,就是你最常接触的五个人的平均。”那么,在分析一个人时,我们不妨观察和他最亲密的几个人。同理的,在判定一个未知事物时,可以观察离它最近的几个样本,这就是 kNN(k最近邻)的方法。
作者:肖睿
编辑:宏观经济算命师
本文由JoinQuant量化课堂推出,本文的难度属于进阶(上),深度为 level-1简介
kNN(k-Nearest Neighbours)是机器学习中最简单易懂的算法,它的适用面很广,并且在样本量足够大的情况下准确度很高,多年来得到了很多的关注和研究。kNN 可以用来进行分类或者回归,大致方法基本相同,本篇文章将主要介绍使用 kNN 进行分类。
举个例子跟你讲
kNN还真是直接讲例子最好懂。大家都喜欢兔子,所以就来说一说兔子的事情吧。
有一种兔子叫作悲伤(Grief),它们的平均身高是 50厘米,平均体重 5公斤。我们拿来一百个悲伤,分别测量它们的身高和体重,画在坐标图上,用绿色方块表示。
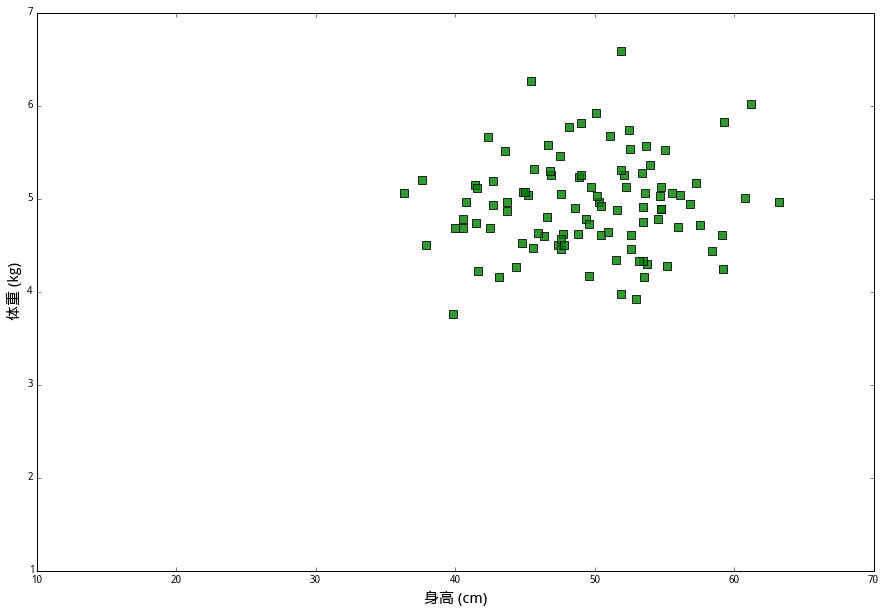

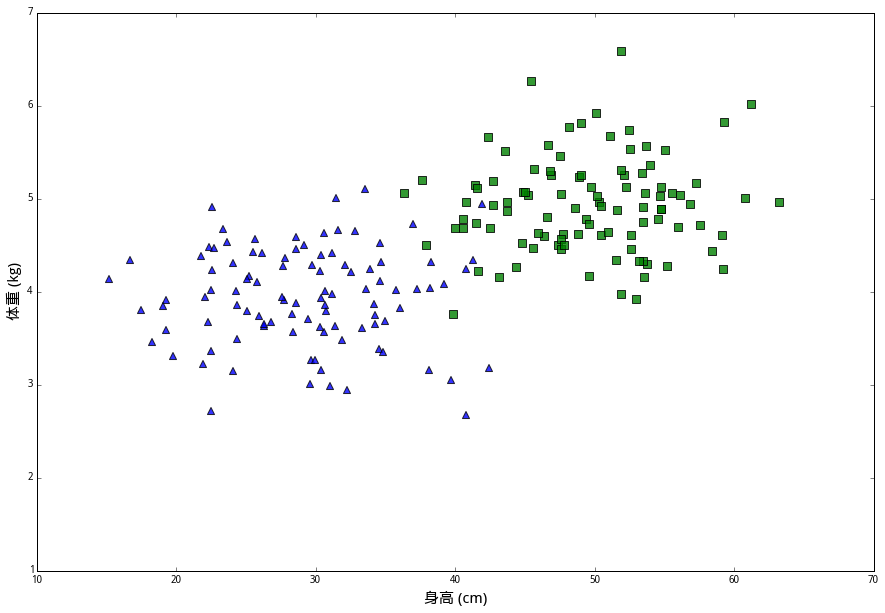


在这些数据中,(身高,体重)(身高,体重) 的二元组叫做特征(features),兔子的品种则是分类标签(class label)。我们想解决的问题是,给定一个未知分类的新样本的所有特征,通过已知数据来判断它的类别。
北京十八环外有一个小树林里经常出现这三种兔子。为了了解它们的生态环境,某研究团队想知道三种兔子的数量比例;可是这些兔子又太过危险,不能让人 亲自去做,所以要设计一个全自动的机器人,让它自己去树林里识别它遇到的每一个兔子的种类。啊,为了把故事讲圆,还要假设他们经费不足,所以机器只有测量 兔子的身高和体重的能力。
那么现在有一迷之兔子,我们想判断它的类别,要怎么做呢?按照最普通的直觉,应该在已知数据里找出几个和我们想探究的兔子最相似的几个点,然后看看那些兔子都是什么个情况;如果它们当中大多数都属于某一类别,那么迷之兔子大概率也就是那个类别了。
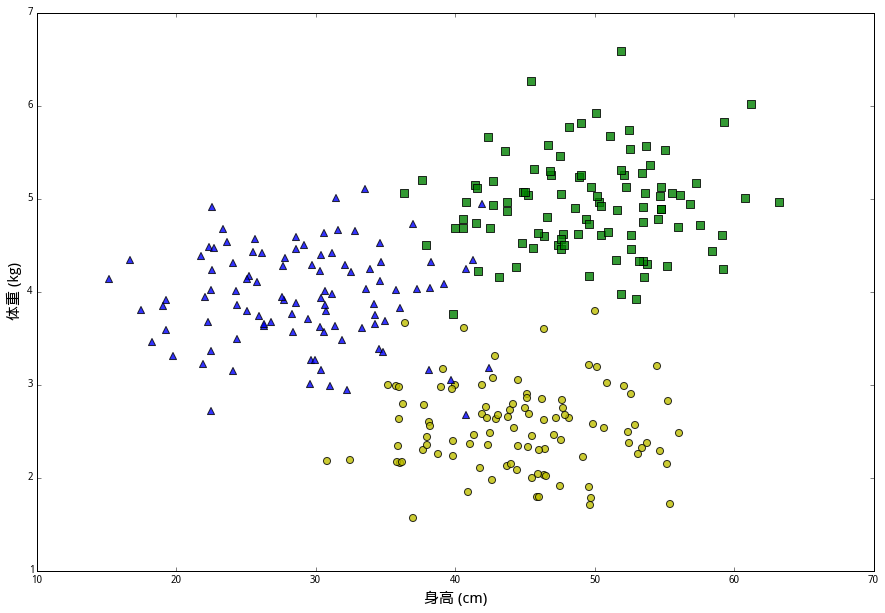
于是乎,我们给机器人预设一个整数 k,让它去寻找距离最近的k个数据样本进行分析。好,机器发现了一只兔子,它长着八条腿,三十二只眼睛,毛茸茸的小尾巴,齐刷刷的八十六颗獠牙,面相狰狞,散发着噩梦般的腐臭,发出来自地狱底处的咆哮… 差不多就是这个样子(作者手绘):



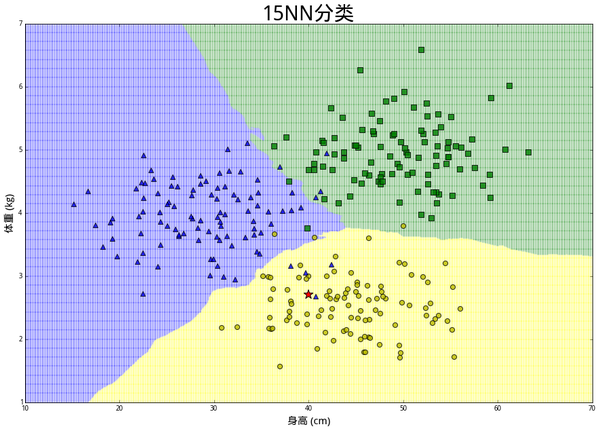
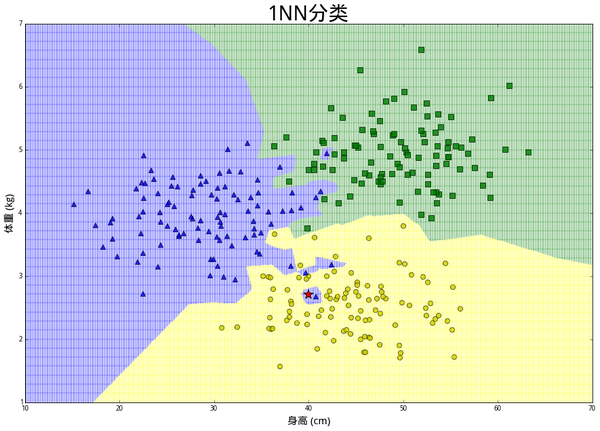
kNN 算法如何对这次观测进行分类要取决于k的大小。直觉告诉我们迷之兔像是一只绝望,因为除了最近的蓝色三角外,附近其他都是黄色圆圈。的确,如果设 k=15,算法会判断这只兔子是一只绝望。但是如果设 k=1,那么由于距离最近的是蓝色三角,会判断迷之兔子是一只痛苦。
如果按照15NN和1NN的方法对这个二维空间上的每一个点进行分类,会形成以下的分割


距离函数
我们在上面的例子中把一个很重要的概念隐藏了起来,在
选择一个数量k还只是小问题,更重要的是距离的计算方法。毕竟,当我们说“最近的k个点”时,这个“近”是怎么衡量的?
在数学中,一个空间上距离的严格定义如下:
设M 为一个空间,M上的一个距离函数是一个函数d:M \times M \rightarrow R,满足:
我们一般最常用的距离函数是欧氏距离,也称作L_2距离。如果x=(x_1,x_2,...,x_n)和y=(y_1,y_2,...,y_n)是n维欧式空间R^n上的两个点,那它们之间的L_2距离是
d_2(x,y)=\sqrt{\sum_{i=1}^{n}{(x_i-y_i)^2}}L_2是更普遍的L_P距离在P=2时的特列。L_P距离的函数d_P定义如下:对于1 \leq P < \infty ,有:
d_P(x,y)=(\sum_{i=1}^{n}{|x_i-y_i|^P})^{1/P}还有L_\infty距离:
d_\infty(x,y)=\mathop{max} \limits_{i=1,...n} |x_i-y_i|在实际应用中,距离函数的选择应该根据数据的特性和分析的需要而定,本篇就不进行更深入的探讨,一般情况下使用最常用的L_2函数即可。
但是!注意!使用 kNN 时需要根据特征数据的取值区间来调整坐标轴的比例,这个做法叫作标准化或者归一化。为什么要这么做呢?拿上面的例子来说,一只兔子的身长(cm)数值平均是它的体重(kg)的10 倍左右,如果我们在这组数值上直接使用L_2距离函数的话就会导致横轴的距离比重明显放大,分类结果也不合理,如下图所示:
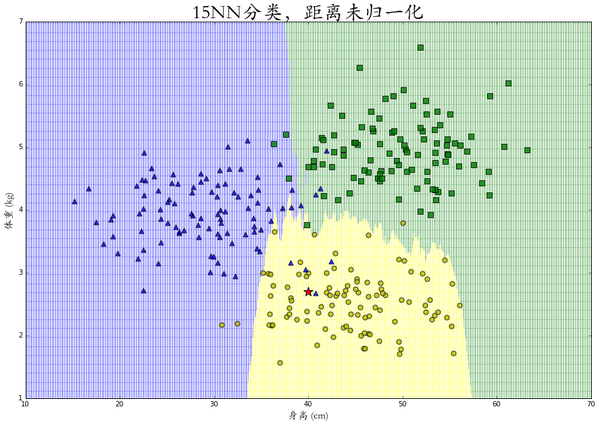

在之前的例子中,由于横轴数值大约是竖轴的10倍左右,所以我们将横轴(身高)的数值压缩 10倍,即计算距离时使用
d((x_1,y_1),(x_2,y_2))=\sqrt{\frac{1}{10}(x_1-y_1)^2+(x_2-y_2)^2}就可以得出合理的 kNN 分类。
一般来说,假设进行 kNN 分类使用的样本的特征是 \left\{ (x_{i1},x_{i2},...x_{in}) \right\} _{i=1}^{m},取每一轴上的最大值减最小值:
M_j= \mathop{max}\limits_{i=1,...,M} x_{ij} - \mathop{min}\limits_{i=1,...,M} x_{ij}并且在计算距离时将每一个坐标轴除以相应的M_j以进行归一化,即:
便可以规避坐标轴比例失衡的问题。
概率 kNN
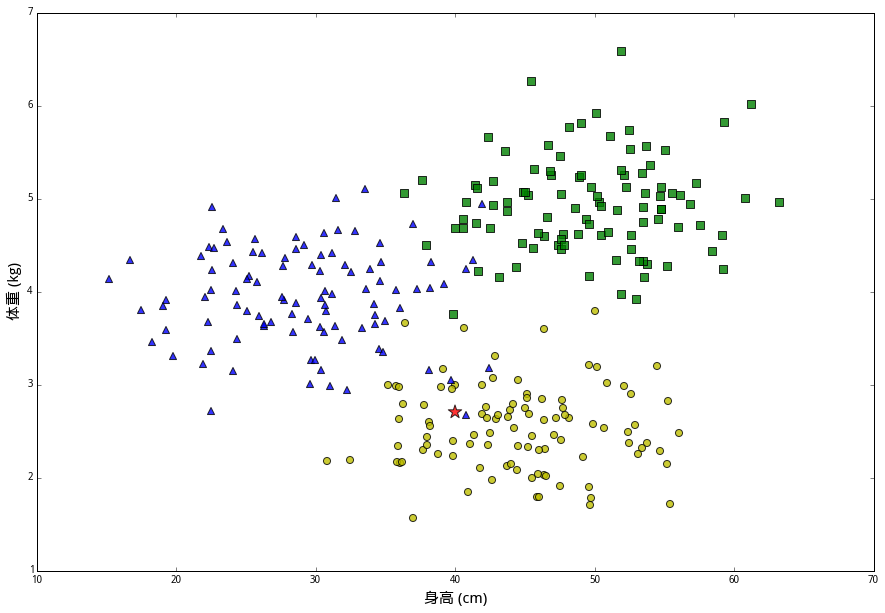
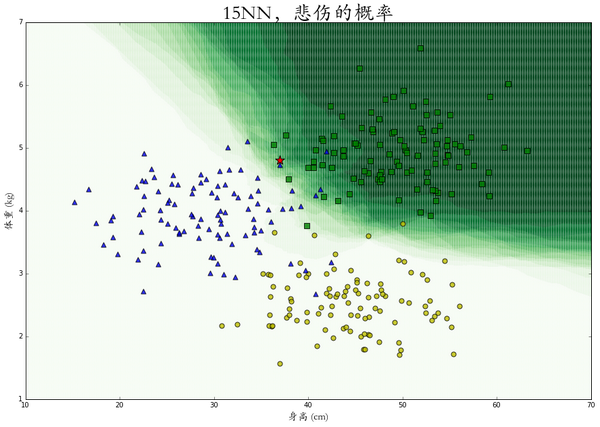
上面的kNN算法返回的是对一组特征的绝对分类,告诉我们这只兔子被判断为哪一个类别。可有时我们并不想知道一个确切地分类,而想知道它属于某个分类的概率是多大。比如我们发现一只身长37体重4.8的小兔兔,在下图五角星的位置。
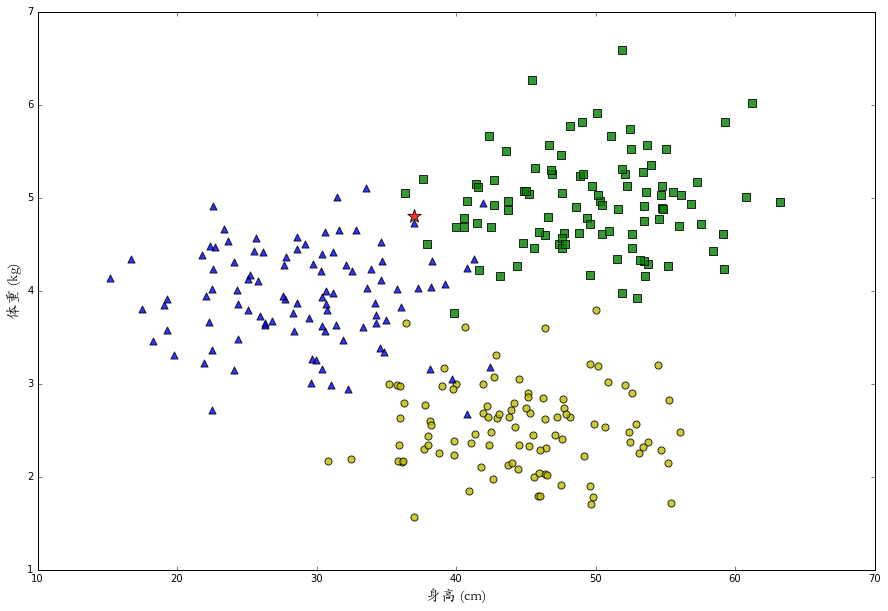

这只兔子的特征数据在悲伤和痛苦的分界处,机器不论判断它属于哪个类别都很有可能是错的。这时,类似“它有一半可能性是痛苦,一半可能性是悲伤”的反馈会更有意义。
为了这个目的,我们同样找找出距离问题特征最近的k个样本,但与其寻找数量最多的分类,我们统计其中每个类别的分别有多少个,再除以k 得到一个属于每一个类别概率值。比如在上面的图里,距离五角星最近的15 个样本中,有8只悲伤和7只痛苦,由此判断:它有53%的可能性是悲伤,47%的可能性是痛苦,0%的可能性是绝望。
在整个二维空间中的每一个点上进行概率 kNN 算法,可以得到每个特征点是属于某个类别的概率热力图,图中颜色越深代表概率越大。






倒不是因为别的,我们就是觉得这种粘液很恶心,清洗起来也很麻烦,所以我们想让机器人在测量并发现是悲伤之后马上掉头逃跑。但是如果机器发现了一只
体型接近痛苦的悲伤,并且普通的 kNN 算法发生误判,没有马上逃跑,那么最后就会被喷了。所以我们使用概率 kNN
的算法并且使用以下风控原则:只要发现兔子有30%以上的概率是悲伤,就马上逃跑。从此之后,机器人就再也没被喷过。
结语
不知你有没有发现,我跟你讲了这么多关于兔子的事,却丝毫没有提及如何用代码计算 kNN。这是因为 kNN 虽然思路简单,但实现起来有一个问题,那就是计算量很大;当数据量很多时,拿一组特征来和所有样本依次计算距离并选取最近的k个,是非常耗费时间的。所以,在量化课堂接下来的文章中,我们将讲解 kNN 的一个高效算法—kd树。
wa ~~~~! 终于搞定了!这个是一个系列的第一篇哦!原文见这里【量化课堂】一只兔子帮你理解 kNN
本文由JoinQuant量化课堂推出,版权归JoinQuant所有,商业转载请联系我们获得授权,非商业
转载请注明出处。
文章迭代记录
v1.1,2016-08-17,添加研究模块
v1.0,2016-08-16,文章上线