
Improving your statistical inferences第四周:效应量
注:Improving your statistical inference是荷兰 Eindhoven University of Technology心理学研究者Danial Lakens在coursera上开设的一门公开课,目的是为了增加心理学研究者对心理学研究中常用统计的理解。本次更新第四周的内容。
这一周的内容对于我而言比较熟悉,因为之前已经阅读过Lakens (2013)的这篇论文,而在我们自己论文里,也花了不少笔墨来讲效应。但是这一周的课程也让我学习到了新东西。
首先,效应量是什么? 目前来说,心理学界对于效应量(effect size,又译为效果量)的定义是比较宽松的。凡是研究者感兴趣的量都是效应量。下图是从我们论文(胡传鹏, 王非, 过继成思, 宋梦迪, 隋洁, 彭凯平. 2016)中的表1,列举了各种常见的效应量。举个栗子,一个对自己体重比较关心的人,自己的真实体重就是一个效应量。当TA开始关心体重的变化时(比如我),这个体重变化的量也是效应量。当然,Lakens在课堂上讲的例子是不一样的,大家应该看看这个视频。


在心理学研究中,我们知道都是用p值来进行统计的,一般报告p值即可,但为什么要计算和报告效应量?Lakens提到了三个原因。第一、效应量比p值更具有实际意义:知道某个效应有多大比是否知道这个效应是否存在更有意义。在这里,Lakens把功劳归了Jacob Cohen,这位从上世纪60年代初就开始在心理学界推荐使用效应量的心理学家。

在后面的课程中,Lakens举了一个2014年发表在PNAS上的研究。这个研究发现当人为地给人们的facebook新消息中呈现更多的负面消息时,人们的自身表达负面情绪的词汇也会增加: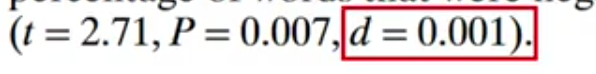

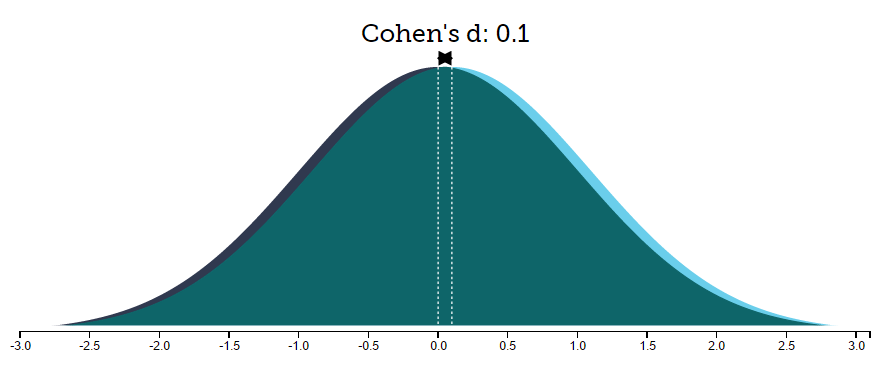

当d = 0.001的时候,这两个分布是这样的:

幸亏这个网站上告诉了我们d = 0.001意味着什么:... in order to have one more favorable outcome in the treatment group compared to the control group we need to treat 3570.4 people...
(当然这个PNAS上2014的文章还有其他的问题,比如参加研究的facebook用户并不知道自己的主页上呈现的信息是被操纵的)
上面的这个例子是讲 p < 0.05但是效应量非常小,还有一些例子是表示效应量虽然小但是实际的意义很大。比如,使用干预减少青少年再犯的:




第二个使用效应量的意义在于,它可以帮助其他研究者进行元分析(meta-analysis)。当研究者通过元分析综合了多个研究的效应量之后,可以得到对真值更加准确的估计,这对于增进人类知识而言是非常好的,也是科研的真正的目的。下图是元分析的一个示意图。每个研究测量到的效应量会因为误差而变来变去,而元分析可以得到一个相对更加稳定的值。
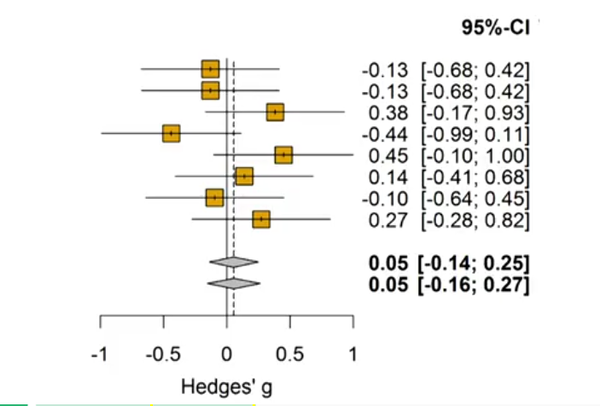

报告效应的第三个原因是可以让研究者进行统计检验力(statistic power)分析。这个原因与上一个比较相似,也是出于对整个科学界的贡献。在我们目前的虚无假设检验的理论框架之后,效应量、统计检验力、alpha水平和样本量这四个变量相互关联,知道其中三个就可以推导出第四个,由于在心理学研究中alpha水平通常被定为0.05,而对于统计检验力,正如上一课中所提到的,理论上讲是越高越好,80%是不错,90%更好,95%的话,那就再好不过了。所以在这种情况下,alpha与统计检验力都可以设定,如果知道了效应量,那么就可以对研究所需要的样本量进行估计了。
后面的课程中,主要是分别介绍了两个应用最广泛的效应量: Cohen'd family和r family。这两类效应量是我们最常用的,尤其是前者。而ANOVA中常用到的eta squared,则被归入到r family。对于这两类效应量的介绍,最重要的是要使用unbiased的指标。我们在论文的补充材料中,也对这两类效应量进行过专门的说明,当然,其实还是来自Lakens (2013):


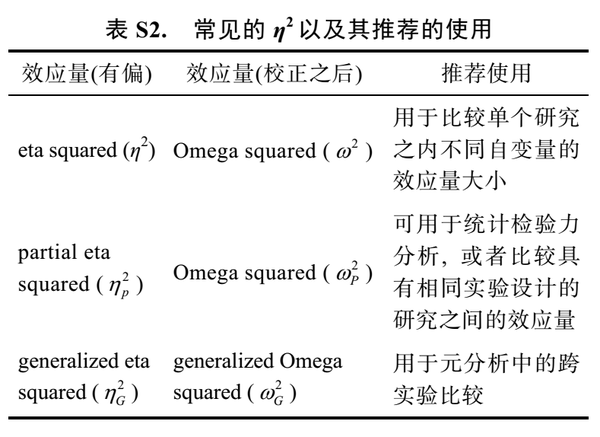

在课后练习中,提供了两非常有用的excel表格,一个用来计算unbiased eta squared :
Calculate Partial Eta Omega Epsilon Squared.xlsx,一个用来计算效应量的(适用各种常用的心理学实验设计):
Calculate Partial Eta Omega Epsilon Squared.xlsx。
对于我而言,这一课最重要的意义在于:效应量不仅仅是一个统计的指标,它是有相应的意义的。Lakens举了实际的意义,而有的时候,它可能还意味着理论的意义、或者效果/成本权衡。
最后,我想说的是,效应量只是对真实效应的点估计(point estimate),而这个估计往往是有误差的,于是需要一个置信区间,这正是下一周的内容。
参考文献:
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: a practical primer for t-tests and ANOVAs. Frontiers in Psychology, 4, 863. doi:10.3389/fpsyg.2013.00863
胡传鹏, 王非, 过继成思, 宋梦迪, 隋洁, 彭凯平. (2016). 心理学研究的可重复性问题:从危机到契机. 心理科学进展, 24(9), 1504–1518 doi:10.3724/SP.J.1042.2016.01504
