
Improving your statistical inferences第五周:置信区间、样本量以及p-curve
注:Improving your statistical inference是荷兰 Eindhoven University of Technology心理学研究者Danial Lakens在coursera上开设的一门公开课,目的是为了增加心理学研究者对心理学研究中常用统计的理解。本次更新第五周的内容。
本周的内容主要是接着上周的效应量。既然我们报告了效应量(以及解读TA的理论和实际的意义),接下来,我们需要报告效应量的误差,也就是置信区间。为什么要报告置信区间呢?原因是:我们的研究一般是从总体中抽出一个样本,想要根据这个样本来对总体的情况进行推断,既然是一次抽样,就可能有误差。有个名人说过:只报告点估计不报告相应的误差就是耍流氓。


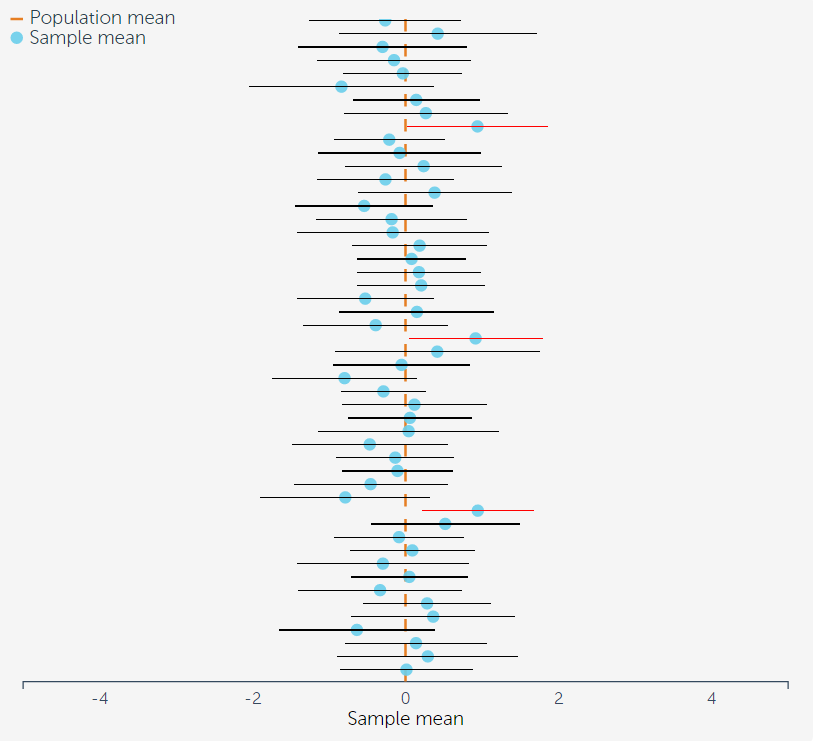
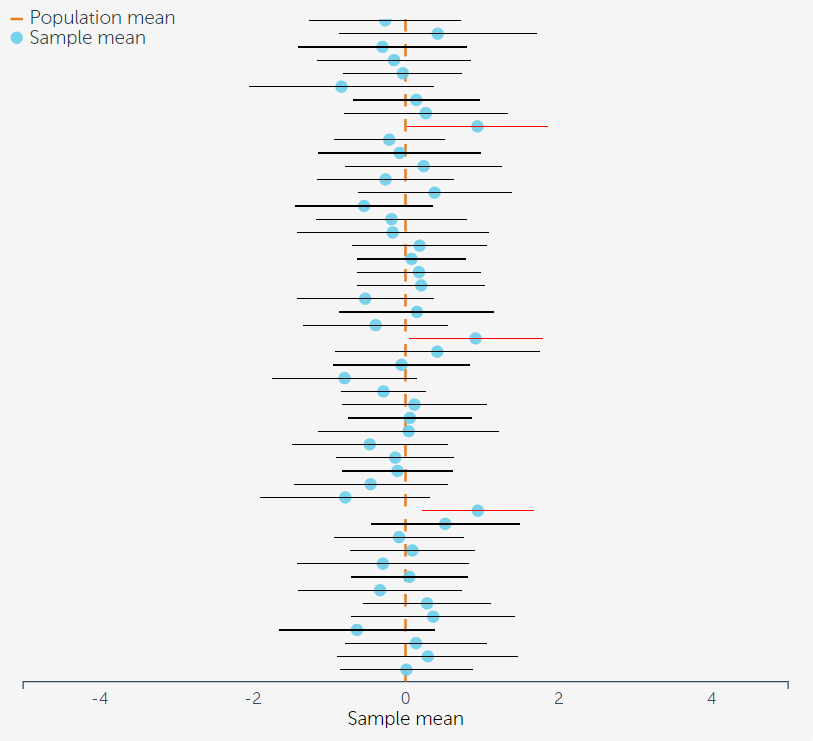
CI的一个特点是,随着样本量的增加,会越来越稳定地接近真值(废话,样本量越多,从总体中抽出来的个体越多,当然会越接近真值)。
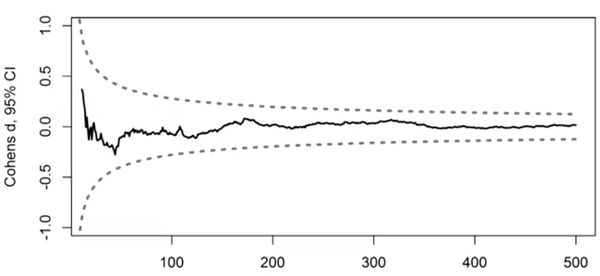

不过95%的CI是否意味着你重复一次实验,有95%的可能就包含真值?不是的。这个比值叫做捕获百分比(Capture Percentage),具体的原理就不讲了,有兴趣的同学参考这个文献:[http://psych.colorado.edu/~willcutt/pdfs/Cumming_2006.pdf]。但记住一点:95%的CI的捕获百分比大约为84.3%。这个错误出现在Science的一篇评论中,至今没有纠正[见我们的中文介绍:胡传鹏, 王非, 过继成思, 宋梦迪, 隋洁, 彭凯平. (2016)]。
CI的作用是什么?对于单个的实验室来说,可能没有那么重要,但是对于整个科学界来说,即是非常重要的,因为它可以帮我们对多个研究进行整合的元分析,从而得到对真值更加准确的估计,体现科学的累积的效果。
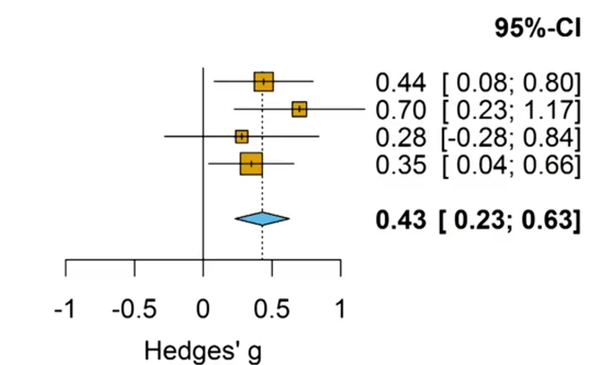

当然,提到置信区间就不会不提贝叶斯的credible intervals,这个概念更接近我们的直觉:在95% credible intervals中间的是我们认为最有可能的值。这个概念也可以搜索一下相关的文献。
本周第二课讲的是统计检验力分析(Power analysis)和样本量的估计。这个对于研究者来说很实用,但也是非常难搞定的一个。
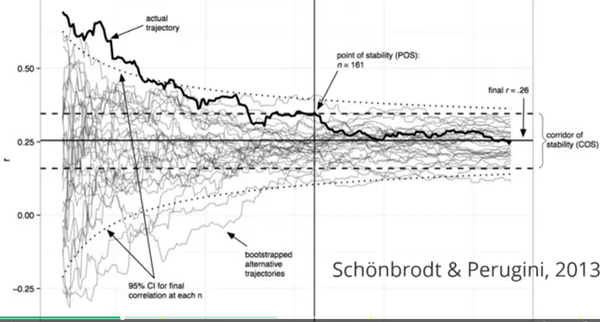

前面提到,样本量越小,CI越大,所以小样本量估计出来的CI,其实很不靠谱。但研究者的时间和金钱是有限的,如何在大样本与有有限的资源之间进行平衡?以前主要靠直觉,比如说前面的人用了30个人,我们也用30个。现在大部分人仍然是这么做的。但是这样做已经不行了,因为大部分的好期刊已经开始要求你明确说明你为什么要采用这个样本量。以下是最近JEP:G一个文章方法部分的截图:


正是由于我们之前是用的直觉,导致心理学研究整体的统计检验力严重不足。2013年,Nature Neuroscience专门刊登了篇文章,标题就是叫做Power failure。
上周提到过统计检验力、效应量、alpha水平与样本量四者有密切关系,确定三者可以得到剩下的一个。一般实验前想要知道需要多少样本量能够达到令人满意的检验力(比如说90%),那么这时候效应量的值就显得很关键。一般来讲,我们可能需要从前人的研究中来得到对效应量的估计,但是由于出版偏见的原因,前人已经发表的研究极有可能高估了效应量。所以,采用无偏的效应量对前人研究进行元分析之后,得到的效应量可能会比较靠谱一些。
在课后的作业中,Lakens提供了使用G*power以及其他一些软件来计算样本量的操作,非常实用。但也有一个问题,对于认知实验中常用的2*2被试内设计,计算交互作用的90%检验力需要多少样本量时,在G*power中如何填写Number of measure仍然不知道,我在课程的论坛上问了这个问题,Lakens直接说:我也不知道。所以这个问题比较tricky。
跳出这个课程,关于样本量上,还有一些经验的做法。比如Simonsohn他们在一篇文章[Small Telescopes]中指出,如何需要重复一个研究,可能需要原研究样本的2.5倍。在另外一个演讲中[life after p-hacking]。他也指出,要想检验出一个类似于男性身高大于女性这样一个效应量的假设,至少需要每组50人的被试间设计。所以,也许,50可能是我们以后进行探索性研究时的一个经验值。当然,在第三周时也提到了optional sampling的方法,可以使用这个,让我们在样本量和有限的资源之间进行平衡。
最后,讲的是P-curve,这个方法已经有了不少文章,比较靠谱(我们在19届全国心理学大会前的工作坊中,由@沉默的马大爷 讲过这个方法)。在第二周时,Lakens讲到,当H0为真时,p 值应该是在0-1之间均匀分布的。而当H1为真时,一个统计检验力比较强的实验中,p值的分布是靠近0这一端,而且是在小于0.01这一端比较多(见下图)。
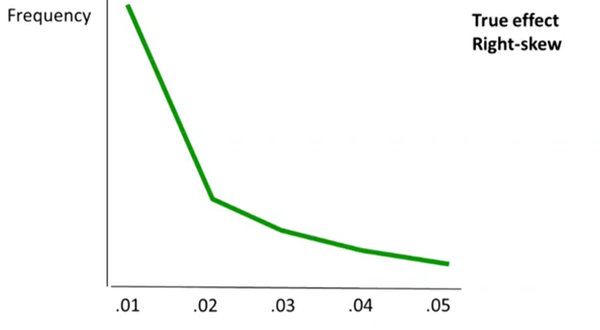

基于这一个理论假设,假如一个研究的效应是真实的(H1为真),那么它的P值应该更多分布在小的一端(0.01),而不是0.05这一端。所以如果我们找出一系列关于这个效应的研究,把他们的阳性结果(p< 0.05)的p值拿过来做一个分布,看看是更多地靠近0.05,还是0.01。如果靠近0.01,则更有可能是在H1为真的情况下的数据(比如下图的教授启动效应)(补一句:最近APS正在组织重复Professor priming的实验,结果可能明年出来)。
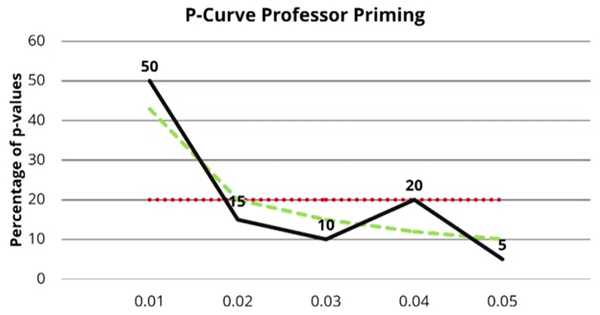

如果是靠近0.05,则H1更有可能效应不存在,H0为真,比如下图的老年启动效应。
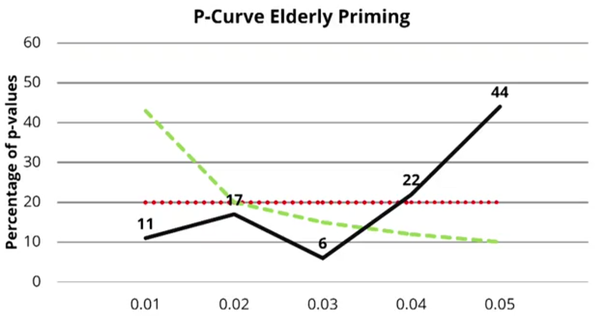

非常遗憾的是p-curve没有练习题,所以我还没有练习。估计以后抽时间自己练习一下。相信理解原理之后,操作起来不难。
小结:只报告效应量不报告置信区间就是耍流氓;样本量估计不容易;p-curve是检验以前关于某个效应是否可靠的好方法。
参考文献
胡传鹏, 王非, 过继成思, 宋梦迪, 隋洁, & 彭凯平. (2016). 心理学研究的可重复性问题:从危机到契机. 心理科学进展, 24(9), 1504–1518 doi:10.3724/SP.J.1042.2016.01504
