
线程安全

线程安全简介
线程安全是Rust语言的又一杀手级特性。本文是Rust中多线程、并行开发相关的系列文章第一篇。
什么是线程
线程是操作系统能够进行调度的最小单位,它是进程中的实际运作单位,每个进程至少包含一个线程。在多核处理器越来越普及的今天,多线程编程也用得越来越广泛。多线程的优势有:
- 容易利用多核优势
- 相比单线程,反应更敏捷,相比多进程,资源共享更容易
多线程编程在许多领域是不可或缺的。但是,多线程并行,非常容易引发数据竞争,而且还非常不容易被发现和debug。下面,我们用C++语言来演示一下,什么是数据竞争:
#include <iostream>
#include <stdlib.h>
#include <thread>
#include <string>
#define COUNT 1000000
volatile int g_num = 0;
void thread1()
{
for (int i=0; i<COUNT; i++){
g_num++;
}
}
void thread2()
{
for (int i=0; i<COUNT; i++){
g_num--;
}
}
int main(int argc, char* argv[])
{
std::thread t1(thread1);
std::thread t2(thread2);
t1.join();
t2.join();
std::cout << "final value:" << g_num << std::endl;
return 0;
}
我们可以使用g++ -pthread -std=c++11 temp.cpp命令编译这段代码。
在这段代码中,我们创建了两个线程。一个线程去修改全局变量global,循环1000000次加1。另外一个线程也去修改全局变量global,循环1000000次减1。如果说没有数据竞争的话,这两个线程执行完毕后,数据最后一定是回到初始值0。然而,我们尝试运行后发现,事与愿违,每次执行的结果都不是0,而且每次的结果都不一样。
为什么会发生这样的现象呢?因为为普通变量加1减1这样的操作并非“原子”操作。我们简化一下这个过程,它可以分为三个步骤,读数据,执行计算,写数据。理想情况下,我们期望的执行流程应该是这样的:
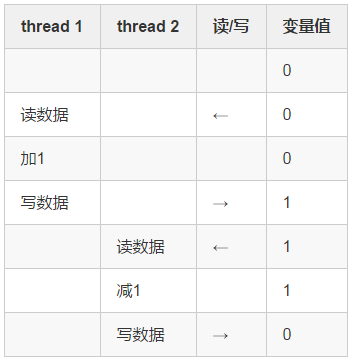
然而,线程的调度是不受我们控制的,即便线程1和线程2内部的执行流程不变,只要调度时机发生了变化,结果也会不同,比如说,实际的执行过程中,有可能是这样的情况:
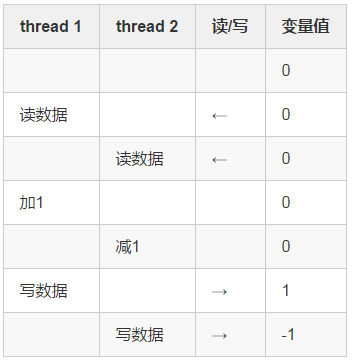
随着调度情况的不同,最终的结果也会有所差异,所以我们可以看到,这个程序的执行结果不是0,而且循环次数越多,发生数据竞争的机会也越大。
在传统的系统级编程语言中,写多线程代码很容易出错。在Mozilla公司,有一位幽默的程序员以这样的一副图片说明了他的心声,(墙纸上贴着:Must be this tall to write multi-threaded code.):
而Rust的一大特点就是,消除了数据竞争,保证了线程安全。下面开始介绍Rust中的线程。
启动线程
Rust标准库中与线程相关的内容在std::thread模块中。Rust中的线程,是对操作系统线程的直接封装。创建线程的方法为:
use std::thread;
thread::spawn(move || {
// 这里是新建线程的执行逻辑
});
默认情况下,新创建的子线程与原先的父线程是分离的关系。也就是说,子线程可以在父线程结束后继续存在,除非父线程是主线程。因为我们知道,如果一个进程的主线程也退出了,这个进程就会终止,其它所有线程都会随之结束。
如果我们需要等待子线程执行结束,那么可以使用join方法:
use std::thread;
// child 的类型是 JoinHandle<T>,这个T是什么呢,当然是闭包的返回类型了
let child = thread::spawn(move || {
// 子线程的逻辑
});
// 父线程等待子线程结束
let res = child.join();
如果我们需要为子线程指定更多的参数信息,那么在创建的时候,可以使用Builder模式:
use std::thread;
thread::Builder::new().name("child1".to_string()).spawn(move || {
println!("Hello, world!");
});
thread模块还提供了几个工具函数:
- thread::sleep(dur: Duration)
使得当前线程等待一段时间继续执行。在等待的时间内,线程调度器会调度其它的线程来执行。 - thread::yield_now()
放弃当前线程的执行,要求线程调度器执行线程切换。 - thread::current()
获得当前的线程。 - thread::park()
暂停当前线程,进入等待状态。当thread::Thread::unpark(&self)方法被调用的时候,这个线程可以被恢复执行。 - thread::Thread::unpark(&self)
恢复一个线程的执行。
以上函数的综合使用可见如下示例:
use std::thread;
use std::time::Duration;
fn main() {
let t = thread::Builder::new()
.name("child1".to_string())
.spawn(move || {
println!("enter child thread.");
thread::park();
println!("resume child thread");
}).unwrap();
println!("spawn a thread");
thread::sleep(Duration::new(5,0));
t.thread().unpark();
t.join();
println!("child thread finished");
}
免数据竞争
粗看起来,Rust的多线程的api很简单。但其实,表面的简洁之下,隐藏着关键的创新设计。正可谓:
胸有激雷而面如平湖者,可拜上将军! ————《孙子兵法》
为了说明Rust在多线程方面的威力,我们来做几个实验,试试如果用多个线程读写同一个变量会发生什么情况。
我们创建一个子线程,用它修改一个外部变量:
use std::thread;
fn main() {
let mut health = 12;
thread::spawn( || {
health *= 2;
});
println!("{}", health);
}
编译,发生错误,错误信息为:
error: closure may outlive the current function, but it borrows health, which is owned by the current function
根据我们前面的知识可知道,spawn函数接受的参数是一个闭包,我们在闭包里面引用了函数体内的局部变量,而这个闭包是运行在另外一个线程上,编译器无法肯定局部变量health的生命周期一定大于闭包的生命周期,于是发生了错误。
那我们对这个程序做一个修改,把闭包加上move修饰。再次编译,可见编译错误已经消失,但是执行发现,变量health的值并未发生改变。为什么呢?因为health是Copy类型,在碰到move型闭包的时候,闭包内的那个health实质上是一份新的拷贝,外面的变量没有被真正修改。
如果我们使用的是非Copy类型,又会怎样呢?
use std::thread;
fn main() {
let mut v : Vec<i32> = vec![];
thread::spawn( || {
v.push(1);
});
println!("{:?}", v);
}
编译,发现同样的错误。再次尝试给闭包加上move试试,还是编译错误:
error: use of moved value: v
这个错误也好理解,我们既然已经把v移动到了闭包里面,那它在本函数内就不能再继续使用了,因为所有权已经移走了。
以上这几个试验全部失败了,那么我们究竟怎么做,才能让一个变量在不同线程中共享呢?
答案是 我们没有办法在多线程中直接读写普通的共享变量,除非使用Rust提供的线程安全相关的设施。
也就是说,Rust给我们提供了一个重要的安全保证:
The compiler prevents all data races.
所谓的“data race(数据竞争)”的意思是,在多线程程序中,不同线程的在没有使用同步的条件下并行访问同一块数据,且其中至少有一个是写操作的情况。
在笔者看来,这是一项 革命性 的进步,非常值得关注。
在许多传统(非函数式)编程语言中,并行程序设计是困难的,困难的原因就在于,代码中存在大量的共享状态,很多隐藏的数据依赖。程序员必须非常清楚代码的流程,使用合适的策略正确实现并发控制。而万一某人在某个地方犯了一个小错误,那么这个程序就成了不安全的,而且没有什么静态检查工具可以保证完整无遗漏地将此类问题检查出来。对于一份规模比较大的C/C++源代码,我们没有什么好办法 “证明” 一个程序是不是“线程安全”的。况且,人非圣贤,孰能无过,就像墨菲定律说的那样:
Anything that can go wrong, will go wrong. ———— Murphey’s Law
因此,有许多人推崇“不可变(immutable)”数据类型的设计。不可变数据类型,在并行环境下,比较容易确保正确性,这是一个巨大优势。但是,所有的代码都围绕“不可变”数据类型来设计,在许多场景下,其实是不方便的。当然,这个世界上有许多聪明人,他们总结出来了一套设计方法,基于“不可变”数据类型,依然可以完成对这个世界的建模(虽然未必是最简洁合理的写法)。这也是许多函数式编程语言的精髓。
然而,Rust并没有盲目跟随传统语言的脚步设计。 它既没走封闭僵化的老路,也没有走改旗易帜的邪路 。Rust允许存在可变变量,允许存在状态共享,同时也做到了 完整无遗漏的 线程安全检查。
Send & Sync
Rust在线程安全方面的背后的功臣是两个特殊的trait:
std::marker::Sync
如果类型T实现了Sync类型,那说明在不同的线程中使用&T访问同一个变量是安全的。std::marker::Send
如果类型T实现了Send类型,那说明这个类型的变量在不同线程中传递所有权是安全的。
在Rust中,有一些trait是在std::marker模块中的特殊的trait。它们有一个共同的特点,就是内部都没有任何的方法,它们只是用于给类型做“标记”。每一种标记,都将类型严格切分成了两个组。
我们可以从源码中的src/libcore/marker.rs中看到:
unsafe impl Send for .. { }
这是一个特殊的语法,它的含义是,针对所有类型,默认实现了Send。要使用这样的语法,trait 必须满足两个条件:
- impl和trait必须处于同一个模块;
- 这个trait内部不能有任何方法。
然后,我们可以针对某些类型,将它们排除出去。,比如:
unsafe impl<T: ?Sized> !Send for *const T { }
unsafe impl<T: ?Sized> !Send for *mut T { }
unsafe impl<'a, T: Sync + ?Sized> Send for &'a T {}
unsafe impl<'a, T: Send + ?Sized> Send for &'a mut T {}
// 等等
Rust把这部分写在了标准库中。所以我们也可以为我们的自定义类型指定它就是是不是Send或者Sync。但是需要注意的是,这两个trait是unsafe的,这意味着我们在impl的时候必须使用unsafe impl来实现。原因在于,指定一个类型是否是Send或者Sync对程序的正确性有关键性的影响,编译器会根据类型成员自动推导该类型是否是Send或者Sync,程序员也可以强制指定,如果指定得不对,是会影响内存安全和线程安全的。
那么,究竟具备什么样特点的类型是 Send 什么样特点的类型是 Sync?
如果一个类型可以安全地从一个线程 move 进入另一个线程,那它就是 Send 类型。比如说,显然的,普通的数字类型肯定是 Send。稍微复杂一点的,Vec<T>这种,只要我们能保证 T: Send,那么Vec<T>肯定也是 Send,把它 move 进其它线程是没什么问题的。那么什么样的类型是 !Send 呢?比如 Rc 类型。我们知道,Rc是引用计数指针,把Rc类型的变量move 进入另外一个线程,只是其中一个引用计数指针 move 到了其它线程,这样会导致不同的线程中的Rc变量引用同一块数据,Rc内部实现没有做任何线程同步处理,这是肯定有问题的。所以标准库中早已指定Rc是!Send。当我们试图在线程边界传递这个类型的时候,就会出现编译错误。
但是相对的是, Arc 类型是符合 Send 的(当然需要T:Send)。为什么呢?因为 Arc 类型内部的引用计数用的是“原子计数”,对它进行增减操作,不会出现多线程数据竞争。所以,多个线程拥有指向同一个变量的 Arc 指针是可以接受的。
对应的,Sync代表的含义是,如果类型&T是线程安全的,那么我们就说T是Sync的。这句话不好理解。其实意思是,如果我们在不同线程中持有只读引用&T类型而不产生问题的话,那么T就是Sync的。它代表这个类型可以被多个线程安全共享。
显然,基本数字类型肯定是Sync。假如不同线程都拥有指向同一个i32类型的只读引用&i32变量,这是没什么问题的。因为这个类型引用只能读,不能写。多个线程读同一个整数,是安全的。像Box<T>和Vec<T>这种也是Sync的,只要其中的参数T是Sync的。
那什么样的类型是 !Sync 呢?所有具有“内部可变性”而又没有多线程同步考虑的类型,都不是 Sync 的。比如,Cell和RefCell就不能是 Sync 的。按照定义,如果我们多个线程中都持有指向同一个变量的 &Cell 型指针,那么在多个线程中,都可以执行 Cell::set 方法来修改它里面的数据,而我们知道,这个类型在修改内部数据的时候,是没有考虑多线程同步的问题的。所以,我们必须把它标记为 !Sync。
那么,当我们需要在多线程中共享,又需要内部可变性的时候,怎么办呢?我们可以使用 Mutex 或者 RwLock 这样的类型。这俩类型的使用方式其实和 RefCell 非常相似,都提供了内部可变性。区别在于,它们在内部实现中,调用了操作系统的多线程同步机制,可以保证线程安全。因此,这两个类型被标记为了 Sync。
Rust把类型根据Sync和Send做了分类,起什么作用呢? 当然是用在“泛型约束”中。Rust中所有跟多线程有关的api,会根据情况,要求类型必须满足Sync或者Send的约束。这样一来,孙猴子就永远逃不出如来佛的手掌心了。你不可能随意在多线程之间共享变量,你不可能在使用多线程共享的时候忘记了加锁。除非你使用unsafe,否则不可能写出存在“数据竞争”的代码来。
比如说,我们最常见的创建线程的函数spawn,它的完整函数签名是这样:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static
我们需要注意到的是,对于参数类型F,它有重要的约束条件 F: Send + 'static, T: Send + 'static。这样,编译器就完成了完整的线程安全检查。
在Rust中,线程安全是默认行为,大部分类型,在单线程中是可以随意共享的,但是没办法直接在多线程中共享。也就是说,只要程序员不要滥用 unsafe,Rust编译器可以检查出所有的具有“数据竞争”潜在风险的代码。凡是通过了编译检查的代码,可以保证,绝对不会出现“线程不安全”的行为。如此一来,多线程代码和单线程代码就有了严格的分野,在一般情况下,我们不需要考虑多线程的问题。即便是万一不小心在多线程中访问了原本只设计为单线程使用的代码,编译器也会给我们报错。
下一篇我们讲解如何正确的在线程之间共享状态。
本文同步发布在微信公众号:Rust编程,欢迎关注。
