
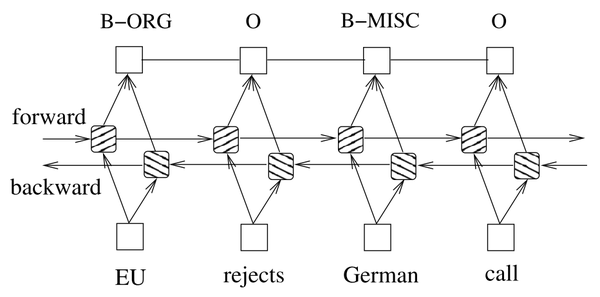
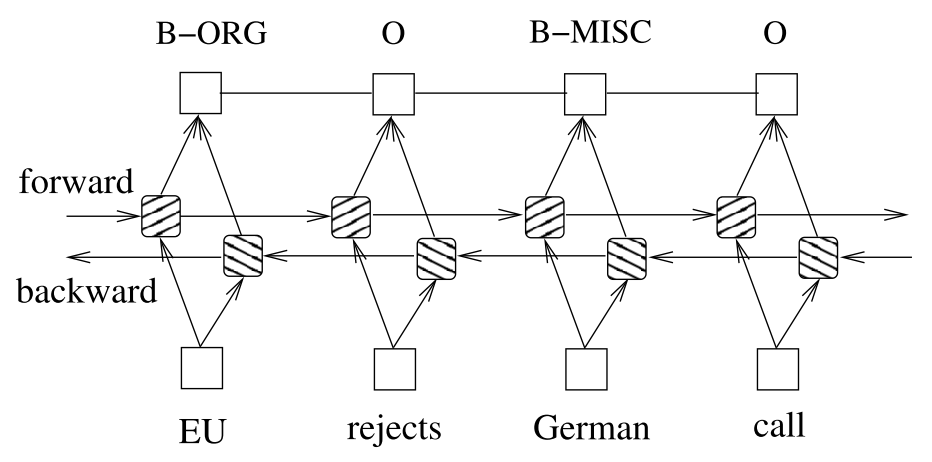
Bi-LSTM-CRF for Sequence Labeling

做了一段时间的Sequence Labeling的工作,发现在NER任务上面,很多论文都采用LSTM-CRFs的结构。CRF在最后一层应用进来可以考虑到概率最大的最优label路径,可以提高指标。
一般的深度学习框架是没有CRF layer的,需要手动实现。最近在学习PyTorch,里面有一个Bi-LSTM-CRF的tutorial实现。不得不说PyTorch的tutorial真是太良心了,基本涵盖了NLP领域各个流行的model实现。在这里从头梳理一遍,也记录下学习过程中的一些问题。
对于输入序列X对应的输出tag序列y,定义分数为
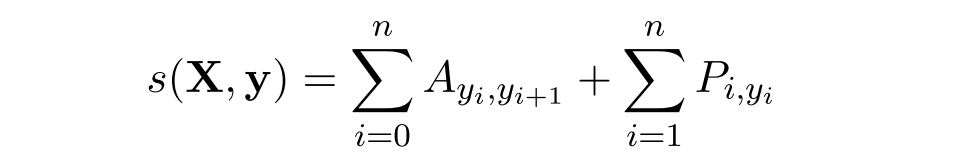
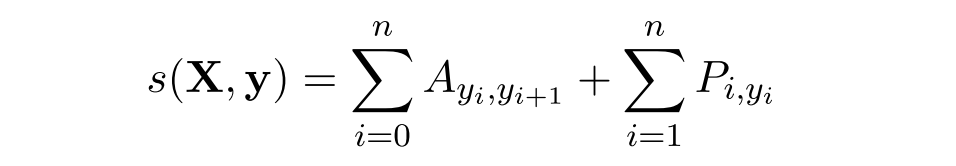

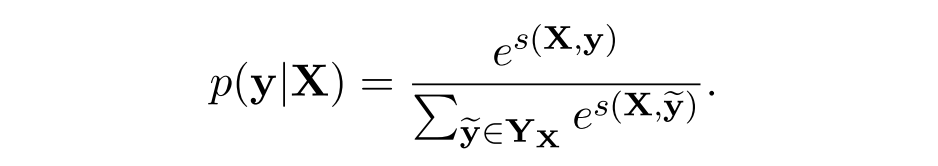
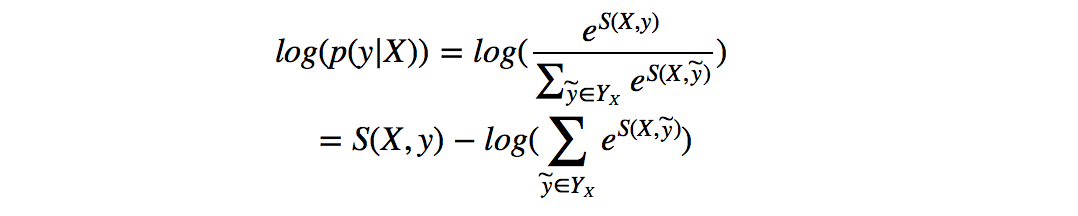
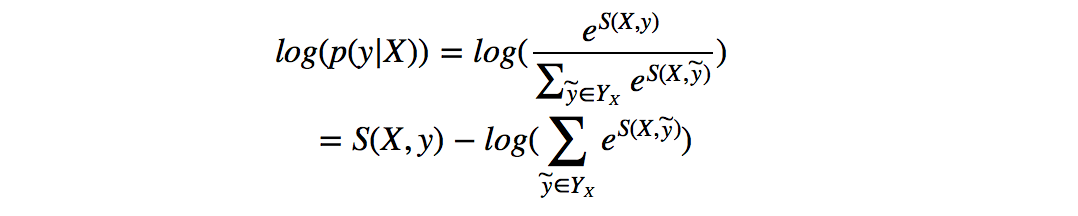
所以我们将损失函数定义为-log(p(y|X)),就可以利用梯度下降法来进行网络的学习了。
在对损失函数进行计算的时候,S(X,y)的计算很简单,而log(\sum_{\widetilde{y}\in Y_X} e^{S(X, \widetilde{y})})(下面记作logsumexp)的计算稍微复杂一些,因为需要计算每一条可能路径的分数。这里用一种简便的方法,对于到词w_{i+1}的路径,可以先把到词w_i的logsumexp计算出来,因为
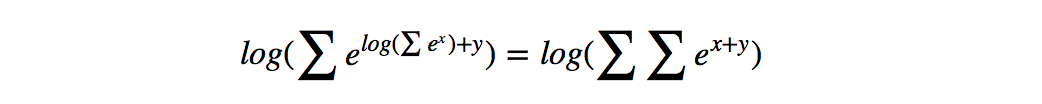
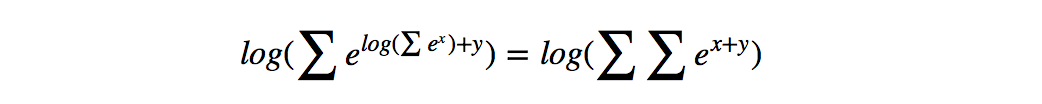
def _forward_alg(self, feats):
# Do the forward algorithm to compute the partition function
init_alphas = torch.Tensor(1, self.tagset_size).fill_(-10000.)
# START_TAG has all of the score.
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# Wrap in a variable so that we will get automatic backprop
forward_var = autograd.Variable(init_alphas)
# Iterate through the sentence
for feat in feats:
alphas_t = [] # The forward variables at this timestep
for next_tag in range(self.tagset_size):
# broadcast the emission score: it is the same regardless of
# the previous tag
emit_score = feat[next_tag].view(
1, -1).expand(1, self.tagset_size)
# the ith entry of trans_score is the score of transitioning to
# next_tag from i
trans_score = self.transitions[next_tag].view(1, -1)
# The ith entry of next_tag_var is the value for the
# edge (i -> next_tag) before we do log-sum-exp
next_tag_var = forward_var + trans_score + emit_score
# The forward variable for this tag is log-sum-exp of all the
# scores.
alphas_t.append(log_sum_exp(next_tag_var))
forward_var = torch.cat(alphas_t).view(1, -1)
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
在解码时,采用Viterbi算法
def _viterbi_decode(self, feats):
backpointers = []
# Initialize the viterbi variables in log space
init_vvars = torch.Tensor(1, self.tagset_size).fill_(-10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var at step i holds the viterbi variables for step i-1
forward_var = autograd.Variable(init_vvars)
for feat in feats:
bptrs_t = [] # holds the backpointers for this step
viterbivars_t = [] # holds the viterbi variables for this step
for next_tag in range(self.tagset_size):
# next_tag_var[i] holds the viterbi variable for tag i at the
# previous step, plus the score of transitioning
# from tag i to next_tag.
# We don't include the emission scores here because the max
# does not depend on them (we add them in below)
next_tag_var = forward_var + self.transitions[next_tag]
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id])
# Now add in the emission scores, and assign forward_var to the set
# of viterbi variables we just computed
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)
# Transition to STOP_TAG
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# Follow the back pointers to decode the best path.
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path全部代码实现可以移步Bi-LSTM-CRF。
参考
Bidirectional LSTM-CRF Models for Sequence TaggingNeural Architectures for Named Entity Recognition
Advanced: Making Dynamic Decisions and the Bi-LSTM CRF
