
《小王爱迁移》系列之四:深度迁移网络

在这篇专栏文章里,我们介绍三篇连贯式的深度迁移学习的研究成果,管中窥豹,一睹深度网络进行迁移的奥秘。这三篇代表性论文分别是:
- PRICAI 2014的DaNN(Domain Adaptive Neural Network)[1]
- arXiv 2014的DDC(Deep Domain Confusion)[2]
- ICML 2015上的深度适配网络(Deep Adaptation Network, DAN) [3]
三篇文章由浅入深,针对迁移学习和机器学习中经典的domain adaptation问题给出了连贯式的解决方案。
背景
继Jason Yosinski在2014年的NIPS上的《How transferable are features in deep neural networks?》探讨了深度神经网络的可迁移性以后,有一大批工作就开始实际地进行深度迁移学习。我们简要回顾一下Jason工作的重要结论:对于一个深度网络,随着网络层数的加深,网络越来越依赖于特定任务;而浅层相对来说只是学习一个大概的特征。不同任务的网络中,浅层的特征基本是通用的。这就启发我们,如果要适配一个网络,重点是要适配高层——那些task-specific的层。
DaNN
在DDC出现之前,已有研究者在2014年环太平洋人工智能大会(PRICAI)上提出了一个叫做DaNN(Domain Adaptive Neural Network)的神经网络。DaNN的结构异常简单,它仅由两层神经元组成:特征层和分类器层。作者的创新工作在于,在特征层后加入了一项MMD适配层,用来计算源域和目标域的距离,并将其加入网络的损失中进行训练。所以,整个网络的优化目标也相应地由两部分构成:在有label的源域数据上的分类误差( \ell_C ),以及对两个领域数据的判别误差( \ell_D )。优化目标由下式形象地表示:
\ell=\ell_C + \lambda \ell_D
式中的这个 \lambda 是权衡网络适配的权重的一个参数,可以人工给定。 \ell_C 很好理解,就是网络的分类误差; \ell_D 表示两个领域的距离。
但是,由于网络太浅,表征能力有限,故无法很有效地解决domain adaptation问题(通俗点说就是精度不高)。因此,后续的研究者大多数都基于其思想进行扩充,如将浅层网络改为更深层的AlexNet、ResNet、VGG等;如将MMD换为多核的MMD等。
DDC
DDC针对预训练的AlexNet(8层)网络,在第7层(也就是feature层,softmax的上一层)加入了MMD距离来减小source和target之间的差异。这个方法简称为DDC。下图是DDC的算法插图。
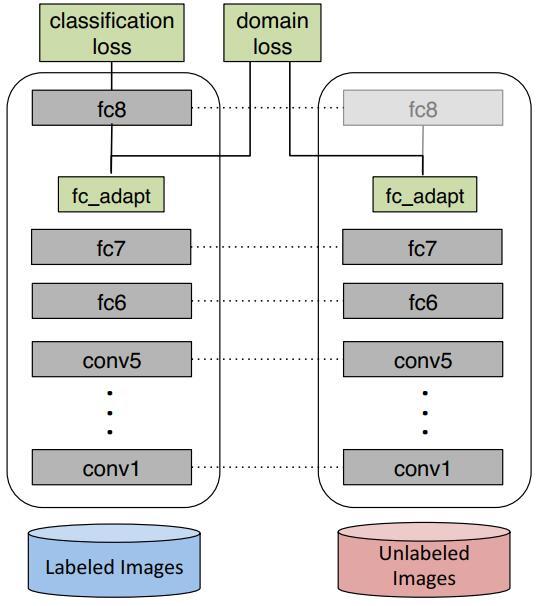

从上图我们可以很明显地看出,DDC的思想非常简单:在原有的AlexNet网络的基础上,对网络的fc7层(分类器前一层)后加一层适配层(adaptation layer)。适配层的作用是,单独考察网络对源域和目标域的判别能力。如果这个判别能力很差,那么我们就认为,网络学到的特征不足以将两个领域数据区分开,因而有助于学习到对领域不敏感的特征表示。
DDC的思想十分简单,但是却成为了深度网络应用于迁移学习领域的经典文章。
DAN
DAN相比DDC加了2点改进:
- 一是多适配了几层特征;
- 二是采用了之前Arthur Gretton提出的多核MMD替换掉原有的单核MMD。
这个MK-MMD是基于原来的MMD发展而来的,它并不是这个文章提出来的,是由Gretton这位核方法大牛在2012年提出来的[3]。原来的MMD呢,是说我们要把source和target用一个相同的映射映射在一个再生核希尔伯特空间(RKHS)中,然后求映射后两部分数据的均值差异,就当作是两部分数据的差异。最重要的一个概念是核k,在MMD中这个k是固定的,我们在实现的时候可以选择是高斯核还是线性核。这样的缺点是明显的:我怎么知道哪个核一定好?
MK-MMD就是为了解决这个问题。它提出用多个核去构造这个总的核,这样效果肯定会比一个核好呀!对于两个概率分布p,q,它们的MK-MMD距离就是
d^2_k(p,q) \triangleq ||E_p[\phi(\mathbf{x}_s)]-E[\phi(\mathbf{x}_t)]||^2_{\mathcal{H}}
这个多个核一起定义的kernel就是
\mathcal{K} \triangleq \left\{k= \sum_{u=1}^{m}\beta_u k_u : \beta_u \ge 0, \forall u \right\}
这个式子很好理解。原来我们的k就是一个固定的函数嘛,现在我们把它用m个不同kernel进行加权,权重就是\beta_u。
其他计算部分不变。
结论
DDC和DAN作为深度迁移学习的代表性方法,充分利用了深度网络的可迁移特性,然后又把统计学习中的MK-MMD距离引入,取得了很好的效果。DAN的作者在2017年又进一步对其进行了延伸,做出了Joint Adaptation Network (JAN),也发在了ICML 2017上。在JAN中,作者进一步把feature和label的联合概率分布考虑了进来,可以视作之前JDA(joint distribution adaptation)的深度版。
启发
数学很重要!我们可以看到最重要的MK-MMD是搞数据的提出来的!好好学数学!
代码
代码可以在这里找到:jindongwang/transferlearning。
References
[1] DaNN文章:Ghifary M, Kleijn W B, Zhang M. Domain adaptive neural networks for object recognition[C]//Pacific Rim International Conference on Artificial Intelligence. Springer, Cham, 2014: 898-904.
[2] DDC文章:Tzeng E, Hoffman J, Zhang N, et al. Deep domain confusion: Maximizing for domain invariance[J]. arXiv preprint arXiv:1412.3474, 2014.
[3] DAN文章:Long M, Cao Y, Wang J, et al. Learning transferable features with deep adaptation networks[C]//International Conference on Machine Learning. 2015: 97-105.
[4] MK-MMD文章:Gretton A, Borgwardt K M, Rasch M J, et al. A kernel two-sample test[J]. Journal of Machine Learning Research, 2012, 13(Mar): 723-773.
[作者简介]王晋东(不在家),中国科学院计算技术研究所博士生,目前研究方向为机器学习、迁移学习、人工智能等。作者联系方式:微博@秦汉日记 ,个人网站Jindong Wang is Here。
=================
更多《小王爱迁移》系列文章:小王爱迁移》系列文章汇总
