
《小王爱迁移》系列之五:测地线流式核方法(GFK)

一直以来都想讲一下GFK方法,但是一直不敢轻易尝试,因为这个方法涉及到了许多方面的知识,以我的能力怕说不好。GFK作为子空间变换方面最为经典的迁移学习方法,从2012年发表在CVPR上以后就一直被许多人引用,也是很多新方法着重对比的对象。其实GFK这个形式不是原创的,它建立在2011年发表在ICCV上的另一篇开创性质的文章(SGF)。我们今天的文章就以GFK方法为主体,简要谈谈这种流形学习方法在迁移学习上的应用。【作者的官网对GFK也有介绍】
背景和动机
GFK方法提出的目的也是为了解决迁移学习中的unsupervised domain adaptation问题:源域数据(source)和目标域数据(target)类别一样,但是特征服从不同的分布。源域数据全部有标注,目标域数据全部无标注。那么如何利用这些有标注的源域数据来给目标域数据打标签呢?
已有的方法大多都集中在特征变换上。就是说,通过一个特征映射,把source和target变换到一个公共空间上,在这个空间里,它们的距离是最小的(相似度最高)。这样就能用传统的机器学习方法进行分类了。
要讲GFK,先从SGF说起。SGF是怎么想的呢?它就想了,我从增量学习中得到启发:人类从一个点想到达另一个点,需要从这个点一步一步走到那一个点。那么,如果我们把source和target都分别看成是高维空间中的两个点,由source变换到target的过程不就完成了domain adaptation?也就是说,路是一步一步走出来的。
于是SGF就做了这个事情。它是怎么做的呢?我来简要叙述一下:把source和target分别看成高维空间(Grassmann流形)中的两个点,在这两个点的测地线距离上取d个中间点,然后依次连接起来。这样,由source和target就构成了一条测地线的路径。我们只需要找到合适的每一步的变换,就能从source变换到target了。
SGF方法的主要贡献在于:提出了这种变换的计算及实现了相应的算法。但是它有很明显的缺点:我到底需要找几个中间点?SGF也没能给出答案,就是说这个参数d是没法估计的,没有一个好的方法。这个问题在GFK中被回答了。
简介
GFK(Geodesic flow kernel)方法首先解决SGF的问题:如何确定source和target路径上中间点的个数。它通过提出一种kernel方法,利用路径上的所有点的积分,把这个问题解决了。这是第一个贡献。然后,它又解决了第二个问题:当有多个source的时候,我们如何决定使用哪个source跟target进行迁移?GFK通过提出Rank of Domain度量,度量出跟target最近的source,来解决这个问题。我们首先介绍一些基础知识,然后介绍GFK的核心方法。

流形学习
流形学习自从2000年在Science上被提出来以后,就成为了机器学习和数据挖掘领域的热门问题。它的基本假设是,现有的数据是从一个高维空间中采样出来的,所以,它具有高维空间中的低维流形结构。流形就是是一种几何对象(就是我们能想像能观测到的)。通俗点说就是,现在的数据表达形式我不太能看出来它是个啥,那我把它想像成是处在一个高维空间,在这个高维空间里它是有个形状的。一个很好的例子就是星座。满天星星怎么描述?我们想像它们在一个更高维的宇宙空间里是有形状的,这就有了各自星座,比如织女座、猎户座。流形学习的经典方法有Isomap、locally linear embedding、laplacian eigenmap等。
格拉斯曼流形Grassmann manifold
SGF和GFK都用了格拉斯曼流形。首先它是一个流形,就具有流形的结构。它是什么呢?我们现在有一个n维的向量空间W,W中任意取k维子空间,就构成了Grassmann流形。更多的理解就是数学了,我们再看下去就要看不懂了。只需要知道:Grassmann流形就是一个由很多维向量空间组成的,就够了。为什么它有用?因为我们的数据本身就是向量嘛,有了向量的空间不就能进行投影变换?
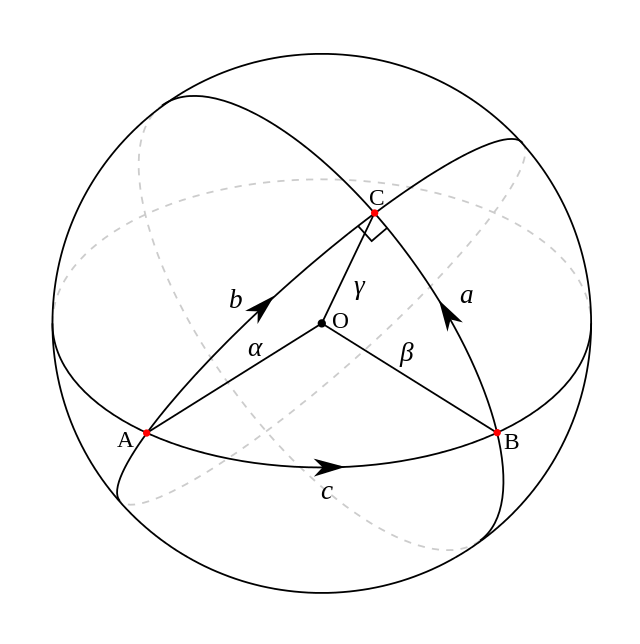
测地线
两点之间什么最短?在二维上是直线(线段),可在三维呢?地球上的两个点的最短距离可不是直线,它是把地球展开成二维平面后画的那条直线。那条线在三维的地球上就是一条曲线。这条曲线就表示了两个点之间的最短距离,我们叫它测地线。更通俗一点,两点之间,测地线最短。在流形学习中,我们遇到测量距离的时候,更多的时候用的就是这个测地线。在我们要介绍的GFK方法中,也是利用了这个测地线距离。比如在下面的图中,从A到C最短的距离在就是展开后的线段,但是在三维球体上看,它却是一条曲线。

方法
GFK方法有以下几个步骤:选择最优的子空间维度进行变换;构建测地线;计算测地线流式核;以及构建分类器。每个步骤都是精心设计的,下面我们一一分析一下。
选择最优的子空间维度
大多数迁移学习方法都涉及到降维:原来我有D维数据,怎么样降低到d维?这个d怎么选择?作者在这里提出了一个计算准则,叫做subspace disagreement measure(SDM),翻译过来就是子空间不一致度量。这个度量可以反映出两个domain在多少维的子空间下能够保持最大一致性。计算方法是:
- 首先针对给定的两个数据集S,T,对它们进行PCA,得到P_S,P_T。PCA操作的目的就是把它们变换到相应的子空间。同时,把S和T合并成一个数据集S+T并计算PCA得到P_{S+T}。【此时有三个数据集了。非常直观地想:如果两个domain相似度高的话,那么它们距离S+T的距离应该都会很小。这一点很重要】接下来就计算彼此的距离。
- 分别计算两个domain和S+T的空间的夹角:记\alpha_d和\beta_d分别为source和target与S+T的夹角。用D(d)=0.5[\sin \alpha_d + sin \beta_d]来表示两个夹角的总度量。【这两个角度如果很小的话,表示两个domain距离很小。两个sin的值最大时,表示两个空间垂直,此时,domain距离是最大的】
- 这时,为了确定这个最优的d,采用了一种贪心算法:尽可能地取最大的d,因为可以保证取更多的子空间个数。但是,当两个domain是直角时就不要取了,否则会给domain adaptation带来困难。此时,这个d就是我们要找的。
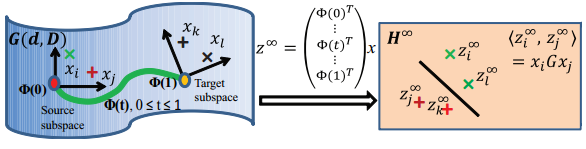
P^\top_S P_T构建测地线流
我们知道,对一个矩阵做完PCA以后的结果中,所有的方向两两都是正交的。也就是说,P_S和P_T中,两两的向量都是正交的。我们假设在流形空间中,source和target通过一个测地线映射函数\Phi映射以后,分别处于0和1两个极点之中,也就是说:\Phi(0)=P_S,\Phi(1)=P_T。对于定义域在[0,1]之间的一个点t,\Phi(t) \in G(d,D)。这里的G(d,D)就是一个D维向量空间中所有d个向量构成的Grassmann流形。这时,测地线函数在点t处的函数值就为
\Phi(t)=P_S U_1 \Gamma(t)-R_S U_2 \Sigma(t)
上面这个式子好复杂,看起来难以理解,符号一下子多了很多。它是什么意思呢,我们一项一项来看。首先看这个R_S,这定义为P_S的补:经过PCA,提取了d维数据,那么R_S就是剩下的D-d维数据,满足R^\top_S P_S=0。这里的U_1,U_2,\Gamma,\Sigma由以下的SVD得到:
P^\top_S P_T=U_1 \Gamma V^\top, R^\top_S P_T=-U_2 \Sigma V^\top
我们都知道经过SVD后的\Gamma,\Sigma都是对角矩阵。在这里,被SVD的矩阵是两个矩阵的乘积(P^\top_S P_T)。这时候,我们把对角矩阵的每个元素叫做这两个矩阵之间的principal angle,表示它们的距离。特别地,\Gamma(t)=cos(t \theta_i)。
这样,我们就构造出了测地线流,下一步可以计算kernel了。
测地线流kernel
为了从\Phi(0)走到\Phi(1),我们应该用几个t呢?GFK的答案是:所有的!其实这也是符合我们认知的,用积分的思想来想一想就觉得是对的。这个变换就应该是无缝的。对于两个向量\mathbf{x}_i,\mathbf{x}_j,我们计算它们在\Phi(t)上的投影,投影到了一个无穷维的向量。这两个无穷维投影的内积就定义了一个测地线流kernel:(知乎编辑器不支持\infinity我只能截图)
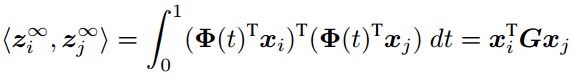

这里的\mathbf{G}是一个半正定矩阵。作者给出了\mathbf{G}的表达形式:
\mathbf{G}=\begin{bmatrix} P_S U_1&R_S U_2 \end{bmatrix} \begin{bmatrix} \Lambda_1& \Lambda_2\\ \Lambda_2 & \Lambda_3 \end{bmatrix} \left[\begin{matrix} U^\top_1 P^\top_S\\ U^\top_2 R^\top_S \end{matrix}\right]
其中\Lambda_{1i}=1+\frac{\sin(2\theta_i)}{2\theta_i},\Lambda_{2i}=\frac{\cos(2\theta_i)-1}{2\theta_i},\Lambda_{3i}=1-\frac{\sin(2\theta_i)}{2\theta_i}都是对角矩阵。
别看复杂,但是GFK实现起来相当简单!
Rank of Domain
GFK另一个贡献就是提出了度量domain之间相似度的Rank of Domain指标,这个很简单,就是用了一个KL散度,我们不做介绍了。
实验
GFK工作在实验上的一大贡献就是提供了Office+Caltech这一迁移学习领域经久不衰的数据集。到目前为止,几乎所有有名的迁移学习方法,都直接或间接地利用了这一数据集作为benchmark。我也对此进行了整理,放在了github上,请直接参考我的github就行了。在这里不过多介绍。
总结
SGF方法创造性地把Grassmann流形引入了迁移学习中,GFK将其发扬广大,成为经典的方法之一。我们学习什么呢?我认为有两点:一是GFK中提到的SDM测度我们可以利用一下,二是principal angle这一度量我们也可以在以后的工作中尝试。GFK的代码已经开源,地址是这里:jindongwang/transferlearning
References
[1] GFK方法原文:Gong, Boqing, et al. "Geodesic flow kernel for unsupervised domain adaptation." Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012.
[2] SGF方法原文:Gopalan, Raghuraman, Ruonan Li, and Rama Chellappa. "Domain adaptation for object recognition: An unsupervised approach." Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011.
[3] 流形学习:[转载]manifold learning 流形学习
[4] 格拉斯曼流形:格拉斯曼流形 | Wikiwand
========================
[作者简介]王晋东(不在家),中国科学院计算技术研究所博士生,目前研究方向为机器学习、迁移学习、人工智能等。作者联系方式:微博@秦汉日记 ,个人网站Jindong Wang is Here。
=================
更多《小王爱迁移》系列文章:小王爱迁移》系列文章汇总
