
CPU制造的那些事之二:Die的大小和良品率


经常有朋友问我:“Intel为什么不出个100核的CPU”,“AMD单核干不过Intel,怎么不堆出个巨无霸和Intel竞争呢?”。“质不够,量来凑”似乎是个好主意,顿时感觉摩尔定律有希望了,我们相关行业又可以混几年了。
幻想美妙,现实残酷。CPU制程不变的情况下,堆砌内核必定造成CPU核心Die尺寸的增大,而其对于产品的良率有极大的影响。产品的良率影响到产品的价格,谁也不想看到自己的钱包缩水。下面我们来看一下Die的大小对于良率的影响。
Die的大小与良率(yield)
在前文(CPU制造的那些事之一:i7和i5其实是孪生兄弟!?)中我们介绍了CPU的制造过程,也顺便提到了晶圆Wafer。我们都知道CPU的制造过程,一定会用到晶圆Wafer。每个CPU内核Die都是从一个完整的Wafer上面切割下来的:

CPU成本的一个重要考量是每个Wafer能制造多少个Die,并尽量减少浪费。我们就以目前主流的300mm晶圆为例。先假设我们的晶圆出自上帝之手,没有任何缺陷(Defect)。因为Die一般是长方形或者正方形,所以圆形的Wafer边缘部分被浪费了,如下图:
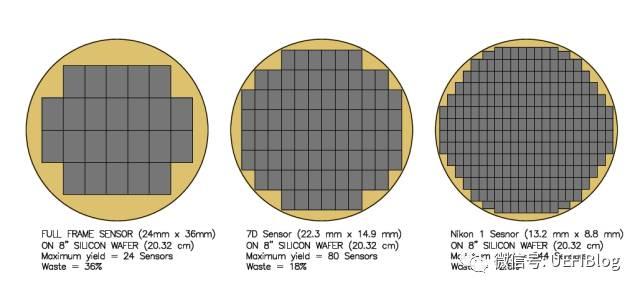

从图中我们可以看出随着Die的缩小,浪费的比例也从36%缩小成为12.6%。根据极限知识,我们知道如果Die的大小足够小,我们理论上可以100%用上所有的Wafer大小。从中我们可以看出越小的Die,浪费越小,从而降低CPU价格,对CPU生产者和消费者都是好事。
回过头来,晶圆在制造过程中总是避免不了缺陷,这些缺陷就像撒芝麻粒,分布在整个Wafer上:

如果考虑缺陷,Die的大小会严重影响良率:
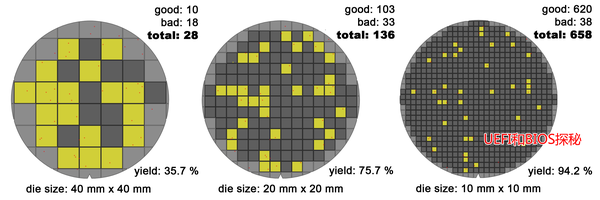
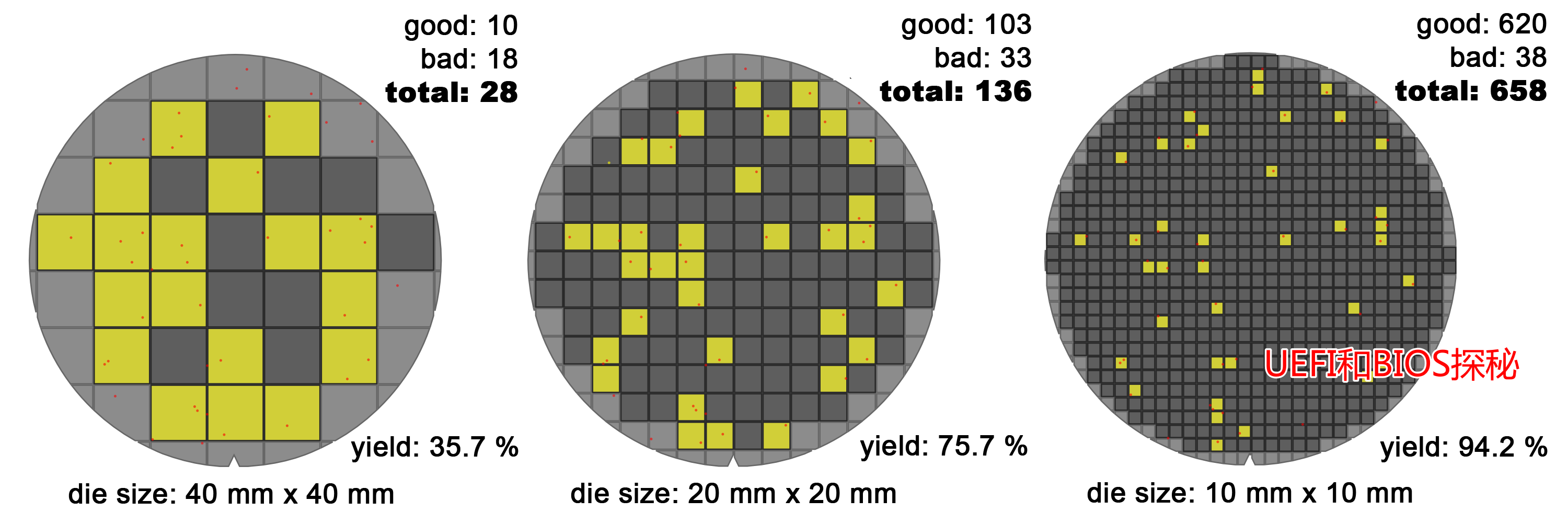
上图大家可以点开看(图比较大),其中不太清楚的红色小点是晶圆的缺陷,在Die很大时,有很大概率它的范围内会缺陷,而只要有缺陷该Die就报废了(简化处理);在Die比较小的时候,它含有缺陷的可能性就大大降低了。如图中,随着Die的减小,良率从第一个的35.7%提高到了95.2%!我们举个极端的例子,整个Wafer就一个Die,那么良率只有0%了,生产一个报废一个。谁还干这么傻的事!
制程、Die的大小与良率
22nm->14nm->10nm,每一步前进都会消耗大量的投资,芯片生产厂家还乐此不疲,有很大的原因就是制程提高了,Die也小了(或者同样大小可以塞入更多的晶体管),良率提高了,也就省钱了。制程提高还能带来另外的好处,譬如更加省电了,性能更好了等等。
但是更好的制程在最初往往会让晶圆的缺陷更容易造成严重问题,反过来会降低良率。频率也可能上不去,不得不binned到低频。同时漏电流的增加会让待机功耗增加,这也是为什么最初的14nmCPU比22nm待机功耗更高的原因。
结论
100个内核的CPU是行不通的,至少目前行不通。现在Die尺寸最大的据我所知就是Intel的Knight系列和N的人工智能板卡,成本非常高。而它们能做那么多核是因为每个核都很简单,占地很小,加起来Die的面积也在可控范围内。
也有同学好奇为什么不采用更大的Wafer呢?那将我们下一篇的内容。
补充
AMD在猪队友工艺落后Intel的前提下,又想要堆核怒怼。另辟蹊径,采取一个Package封装4个独立Die的做法,推出了EPYC服务器芯片,即不影响良率,又可以核心数目好看,可谓一举两得。


并在刚不久发布了ThreadRipper


可惜连接四个Die的片外总线终归没有片内总线效率高,在好些benchmark中败下阵来,可见没有免费的午餐。他也似乎忘记了自己在2005年双核口水大战中调侃Intel是“胶水粘”的双核,自己这次可是“拼积木”式的,为了数据好看也够“拼”的了。
我们来看看四个Die是怎么连接的。我们来看一个双路EPYC服务器:

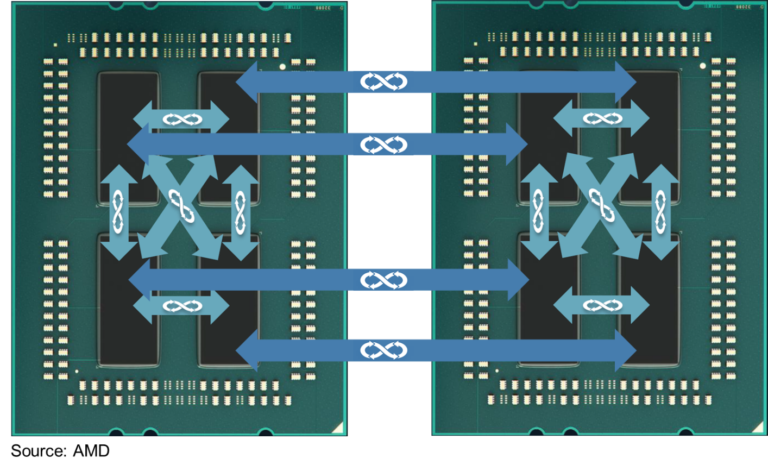
注意这里的双路之间互联和每个CPU Package(MCM)里面4个Zeppelin Die都是Infinity Fabric连接的,本质上Package的四个Die和四路CPU没有什么不同。是四个NUMA的Node(NUMA与UEFI)。
而Intel的Pakcage内部是一个Die, Core之间原来是Ring Bus,在Skylake后改为Mesh:
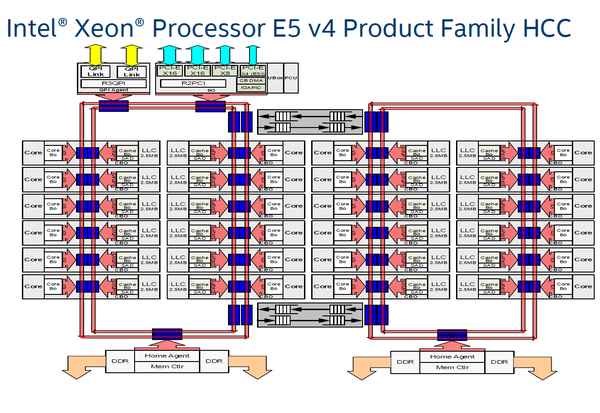
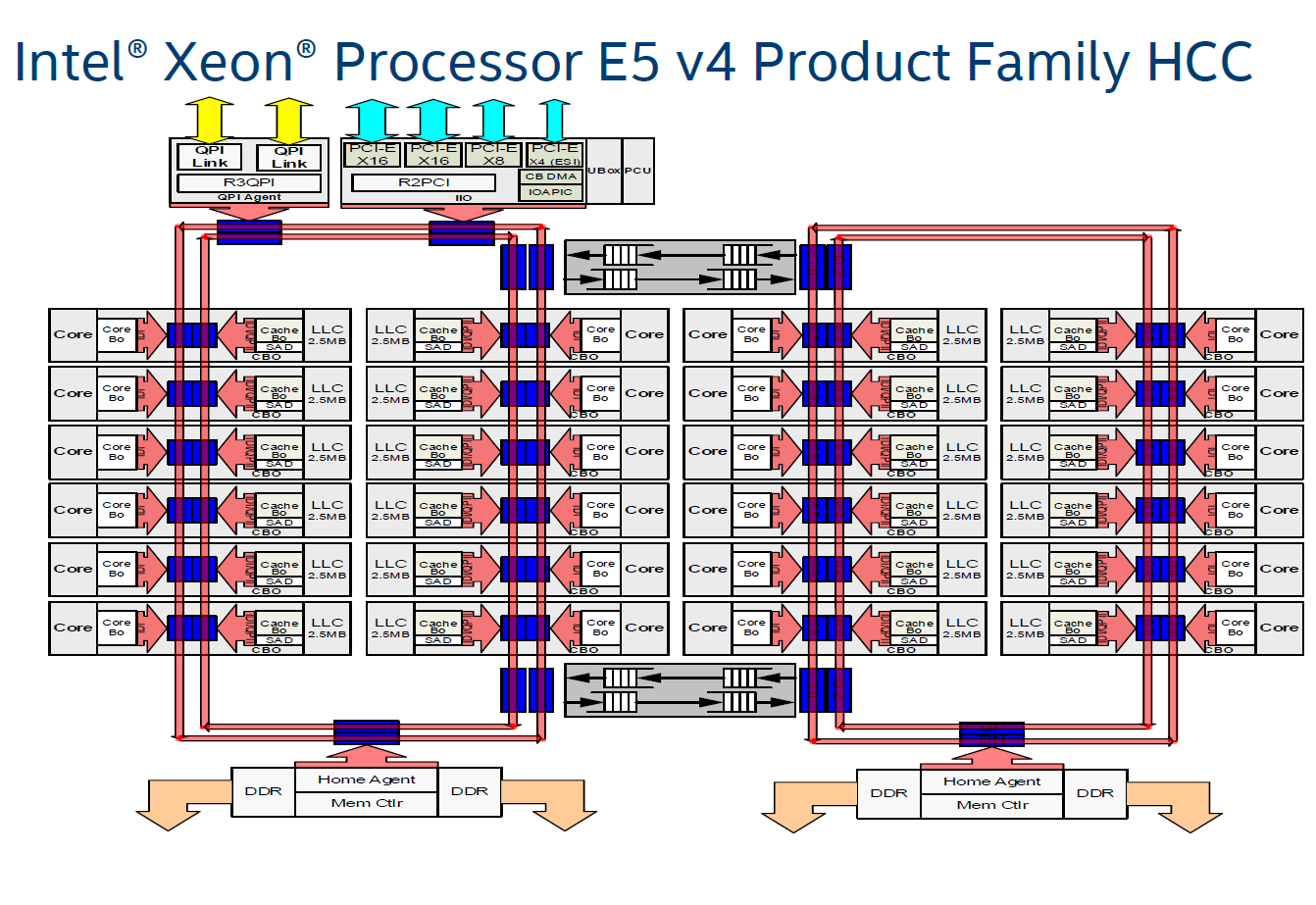
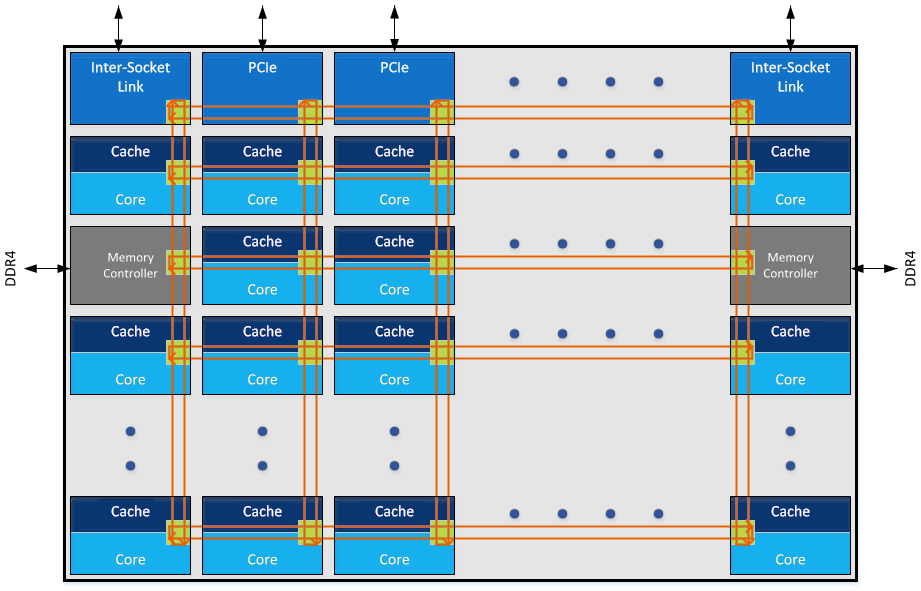
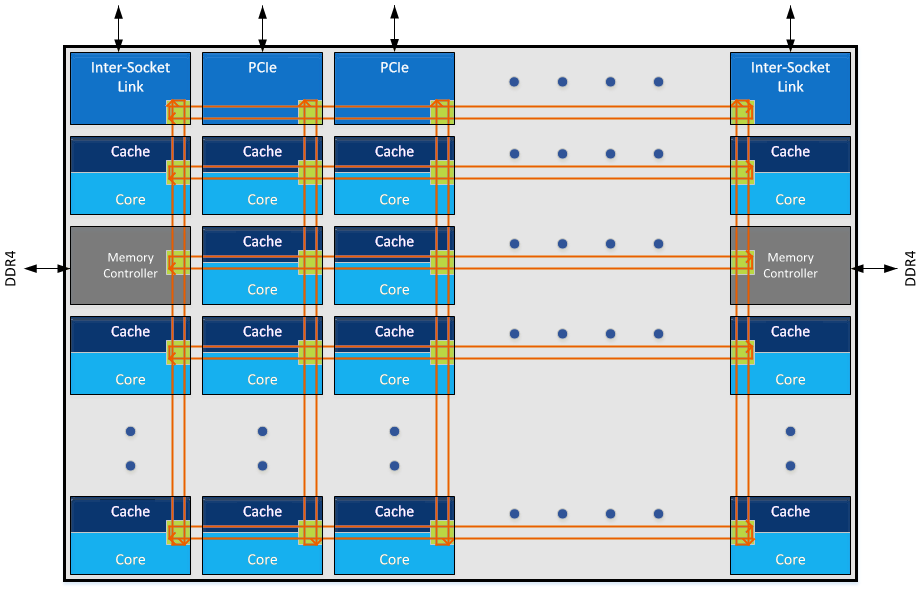
而与Infinity Fabric对应的QPI和UPI只用到了socket互联:

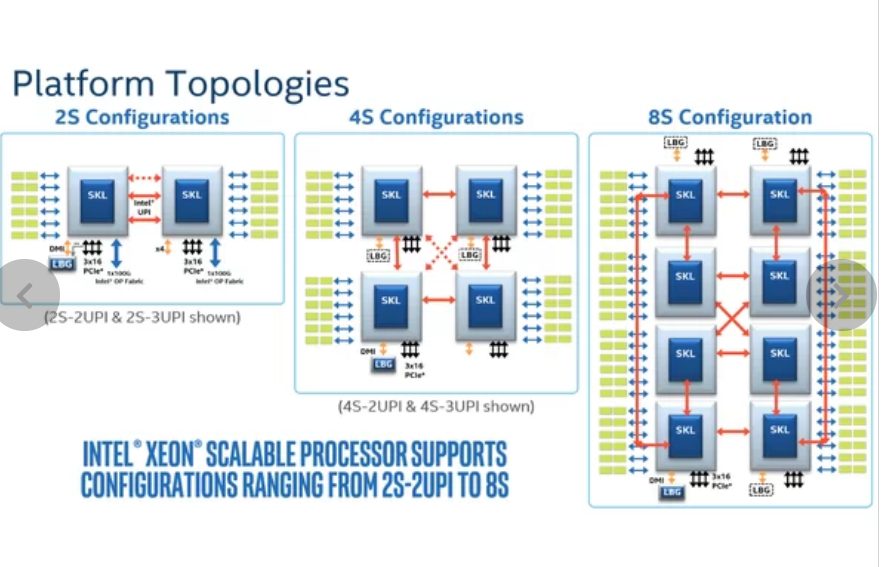
它们的延迟不在一个数量级上。
AMD这样做,在增加灵活性之外,主要的目的是:省钱!!AMD每个Zeppelin Die都比Intel的小,这对良品率提高很大,节约了生产费用。
欢迎大家关注本专栏和用微信扫描下方二维码加入微信公众号"UEFIBlog",在那里有最新的文章。同时欢迎大家给本专栏和公众号投稿!

