
不要等愤怒的用户来通知你的问题

引子
周日早上爬完香山回来,想起还和一位朋友约了咖啡,赶忙打开微信扫路边的一辆单车。摩拜的小程序提醒我开锁中,请勿关闭小程序。然而这开锁的进度在百分之零的位置停留若干分钟,毫无变化。等了许久,我怀疑网络不畅,于是关闭小程序又重新打开扫描,这下可好,小程序直接告诉我:「您上次用的车还未关锁,暂时不能在用其它车哦」。
这就傻逼了。我对着一辆明明没开锁却被认为已开锁的车扫了又扫,我期望聪明的系统能够发现这一异常行为 —— 如果一辆被认定是开锁使用中的车被同一个用户扫了又扫,那一定是这部车没有正常开锁 —— 尤其对一个信用分有 160,人品还算扎实的老同志来说。
可是摩拜就是固执地不让我用车,每次扫码后那句相同的文案,尤其是最后一个用来卖萌的「哦」字,无情地嘲弄在寒风中拖着鼻涕的我。没办法,周日一天,若干本没有必要打车的短途,我都不得已使用滴滴,给北京人民添了赌加了霾。我在朋友圈吐槽两句,有摩拜的朋友要下我的手机号,看了看后说等后台的任务处理到就能给我解锁。
周一早上,算算过去有二十多小时,再慢的任务也该处理完闭,上班路上我想试试账号是否已恢复正常,就顺手扫了一辆车,结果问题依旧。我出离愤怒,写下这样的话准备和摩拜道别:
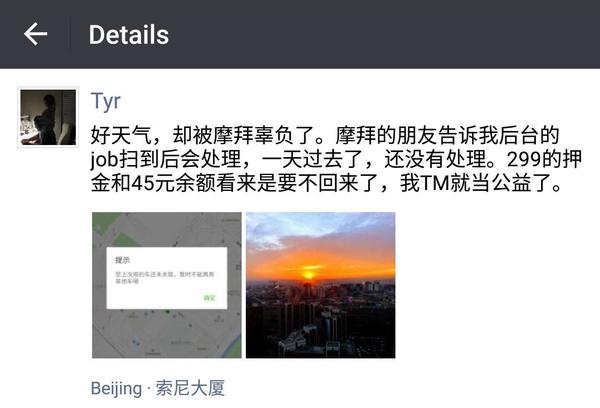

很快地,我被两位朋友分别拉进两个群。一个里有 BD director,一个里是某部门的 head of engineering,在大佬们的亲切关切下,我的问题瞬间解决 —— 在我「骑行」1273 分钟,也就是 21 小时之后,那幽灵一般的车子终于「成功关锁」:
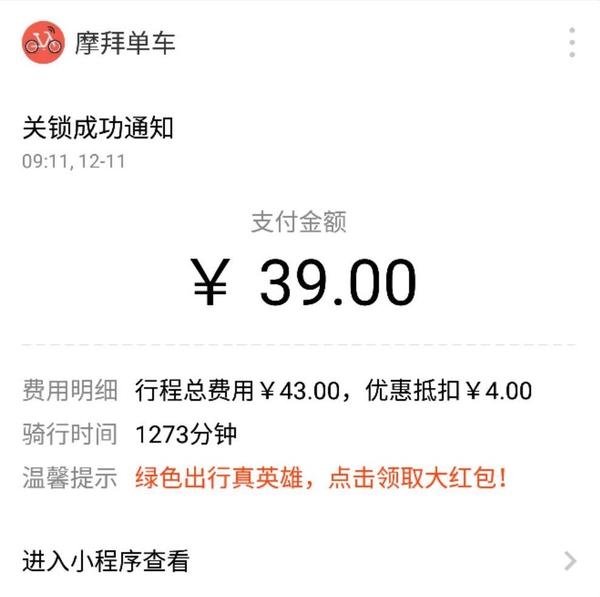

问题解决,该退我的钱也退还给我,借此感谢一下帮忙的各位朋友。在这样一个黑天鹅事件中,我的一众微信好友,还有我在程序员圈子里小小的名气,帮上了大忙。如果换一个用户,这事肯定就没有这么顺利。她的牢骚也许石沉大海,只能通过客服,耗时耗力,才能追回不该产生的费用。
换做别人,这事可能就这么揭过,顶多变成茶余饭后的谈资。但对于一个闲的蛋疼没事就瞎琢磨的程序员来说,没有什么比这样的事情更有趣,跟值得思考。周一晚上回到酒店,在游泳池里消磨脂肪,打发卡路里的时间里,我的脑海里反反复复萦绕着一个问题:如何让系统更好地自行监测和处理类似的问题,而不是由愤怒的用户反馈上报?
如何更快地发现和处理类似问题?
作者按:以下分析纯属扯淡 —— 它并非基于一系列真实的数据,而是做了诸多很可能不靠谱的假设,分析也并非深思熟虑,就是半个多小时的突发奇想。套用菜头叔的一句话:我所说的,都是错的。
按照已公开的专利:一种基于物联网的公共自行车租赁系统(https://www.google.com/patents/CN105354935A?cl=zh)的描述,借车的流程是这样子的(略修改):
- 利用手机APP扫描车身上的二维码,手机APP获取该自行车的唯一标识信息,并把借用请求发送到后台控制系统。后台控制系统同时给自行车的车载控制器发送开锁指令。
- 车锁打开后,车载控制器会向系统发送开锁成功信息(同时附带GPS定位信息),自行车进入借用状态。
我的情况显然是车载控制器向系统发送开锁成功的信息,系统认为自行车进入到借用状态,而车锁实际并未真正打开。这在实际应用中是很难杜绝的问题,因为机械的开关动作无法完美地和发送开锁成功消息的芯片形成有一个完整的事务(transaction)。
上文中吐槽过,如果一个信誉良好的用户在「刷开」一辆车后,又重新扫相同的车,那么,非常非常大的几率是车锁并未真正打开。从产品的角度上讲,不应该阻止用户用车,而是再次尝试重新开锁,如果用户反复扫码,则应该在 app 中问问用户这辆车是不是无法正常开锁,并提示其汇报问题车辆。用户此时可以扫别的自行车骑行。
当然,这一优化对信誉一般的用户,或者扫一辆车没扫开,便换一辆车来扫的用户来说,不太适用。很多时候还是会出现系统认为你正在用车进而无法借车的问题,我们需要更快地,更妥善地解决它。
我们先做些定义:
- session:每次开锁后,到用户使用完毕关锁前是一个 session。session 有下面若干种。
- active session:正在进行中的 session,当用户扫码开锁借用一部车时,就产生一个 active session。一个用户只能有一个 active session。
- abnormal session:不正常的 active session,比如开锁后三十分钟却无产生位移。
- finished session:结束的 session。当用户关锁后,会结束当前的 active session,用户有资格继续借车。
还有假设:
- 90% 的 session 不超过 1 小时。最长的 session 不会超过 1 天。
- 如果一个 session 在半小时(1800s)没有任何活动(意味着用户既没有关锁,又没有真正在骑行),那么这个 session 应该做异常处理。
- 开锁后,车载的智能锁每 N 秒(假定 N=10)会向服务器发送心跳信息 —— 其中包含车辆编号,用户id,当前的地理位置,产生的位移(位移可以通过车轮的转速和周长算出)等。如果用户的 app 处于打开状态,也会以相同的节奏发送类似的数据,包含车辆编号,用户id,当前地理位置,以及根据 4G / WiFi / GPS 的信号来计算产生的位移。
给定这些定义和假设,我们可以讨论下 session scan 的方法。
方案一
最传统的方式是将 active session 组织成一个双向链表,当一个 active session 结束后,将其从链表中拿出释放。然后,后台有一个定时任务扫描这个链表,如果发现 abnormal session,将其拉出来 打上标记 并插入一个 abnormal session 的双向链表,当其再度达到 timeout 时,进行异常处理。比如说再次关锁并结束这个 session,修正计费问题,或者进而加入到一个有待线下人工处理的队列。
方案二
方案一简单易行,但最大的问题是 scan 本身是个线性的操作,O(N) 的复杂度避无可避。如果 N 在千万甚至上亿量级,其效果将会很差,可能一次完整的 scan 要数个小时完成,那么很多异常只有在数个小时后才能发现。
所以我们需要更高效的数据结构来避免这种全表的扫描。我们知道,业界使用很多,效果很好,时间复杂度是 O(1) 数据结构是 timer wheel。她大概长这个样子:
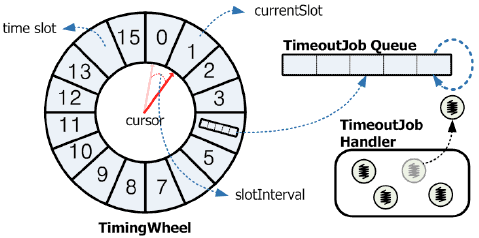

根据业务的需要,timer wheel 可以有不同大小的总槽数(total slots)。slot 和 slot 的间隔我们称为一个 tick。假设一个 tick 是 1s,total slots 128k,那么这个 timer wheel 可以承载最多 1.5 天(128 x 1024 / 86400)内超时的 session,这可以满足我们上述的假定。timer wheel 保持一个 current tick,表明现在时钟走到哪里。时钟走到的位置,如果对应的链表中有 session,那么,这些都是超时的 session,需要被拉下来,由一个或者若干个 worker 来处理。如果在某个 tick 下有一个新的 session 产生,按照上述假设,我们为 session 设置 1800s 的超时时间,那么这个 session 会被安插在 current tick + 1800s 的位置,用双向链表组织起来。下次 current tick 指到这个位置时,这个 session 会被处理。
timer wheel 的好处是,处理超时的 session 是 O(1) 的动作,current tick 指向的位置就是要处理的超时的 session 的列表,非常高效,不用全表扫描来找出需要处理的 session。不过她有一些额外的更新成本,比如说,用户在骑行过程中,每 10s 发送心跳,我们可以通过 GPS 位置的变化,产生的位移来决定是否要刷新这个 session。如果要刷新,那么需要把 session 从 timer wheel 的当前位置取出,放入一个新的位置,从而延缓超时任务对这个 session 的处理。千万级的 session 每 10s 刷新一下,那么每秒有百万级的链表操作,插来插去,非常不经济。一种办法是我们刷新 session 时,在 session 里记录 time diff,当 current tick 到达,worker 处理链表上的超时 session 时,如果发现 session 的 time diff 不为 0,则将其插回到 timer wheel 相应的位置,这样大大节省刷新时的处理(见 patent:http://www.google.com/patents/US8805988)。
timer wheel 还有一个优化是,如果每个 slot 上链表很长,可以在 slot 上用 array + linklist 的方式,把 session hash 到 array 的不同位置,然后再 link 起来,比如说 array 长度为 32,原来一个 1024 长度的链表,可以被分布在 32 个链表下,每个链表平均 32 个 session。这样,我们可以用 32 个 worker 并发处理这些超时的 session。
这样下来,我们可以把异常 session 的处理时间大大缩短,从而挽回一个个悲痛欲绝的用户。
技术之外的一些思考
我们常说,工程师要对其所负责产品有 ownership。这 ownership 说起来简单,但做起来,要付出很多额外的心血。一个业务线的功能做起来并不麻烦,麻烦的是:
- 哪些路径上的哪些 data point 要送到监控系统(如 statsd)?上线后要在监控平台(如 datadog)上的哪些 dashboard 中添加哪些 graph,monitor,alert?潜在问题发生时的执行手册是什么?
- 哪些 error log 送错误追踪系统(如 sentry)?
- 这个功能如何 provision?如何 deploy?如果使用新的资源,如何描述这些资源(infrastructure as code)?
- 如何保证 performance 不会恶化?
- 是否有必要要做 A/B testing,做多大的量?
- 现有的 analytics event(数据埋点)是否完备,如果不够,如何扩展,ETL job 是否要变更,谁来分析处理新收集的数据?
这里面,1 和 2 都是用来帮助我们在问题显现时,能够及时发现和处理。
系统的问题由客户发现,并「被迫发出最后的吼声」,对开发这个系统的程序员来说,不啻是一种耻辱。一个问题为什么由用户报告给我们,我们才开始应对?是我们知道问题的存在假装视而不见?还是压根不知道问题的存在?前者看上去是人品的问题,但八成是程序员被 burn out 之后的自然反应,后者则是技术团队平时对监控和报警不注意导致的。平日里,我们对 UT 没有捕捉到的问题会非常在意,第一时间会补上相关的 UT,让 CI 能够在下次同样的问题发生时,异常退出;然而,对于线上的问题,我们却很少追根溯源,从相应的 data point 是否缺失开始,一路追查到 monitor 和 alert 是否齐备。
前两天,在回顾 11 月我们 Tubi TV 线上问题时,一位同事总结他之前在微软中国 bing team 处理线上问题的一些收获,给大家普及了 TTD / TTA / TTE / TTR 的概念,我觉得很有帮助,列在这里:
- TTD(Time To Detect):问题从发生到被监测出来的时间(可以是通过工具,工程团队,甚至用户发现的)。TTD 越短越好,由工具发现远胜于用户发现并反馈。我们现在大部分问题 TTD 都在 5 分钟之内。
- TTA(Time to Aware):问题从被监测出来到第一个能对此负责的人知道这个问题的时间。TTA 也是越短越好,然而这里有人这个因素的存在,有很多变数。我们用 opsgenie,它接收到报警再通过短信和电话通知到 oncall 的 dev,再到 dev 意识到问题,往往会有 5-10 分钟的间隔;如果 20 分钟无人响应,那么 opsgenie 会打电话给 dev team 的每一个人。所以,绝大多是情况,我们的 TTA 波动很大,大概在 5 - 40 分钟内。
- TTE(Time To Engage):从有人知道发生问题到开始处理问题的时间。有时候,oncall 的 dev 可能在开车,在没有网络的环境,或者手头没有电脑,所以她需要联系下一个她能联系到的,且有资源处理问题的人,这里面也有很多人的因素,我们的 TTE 波动也很大,大致在 5 - 30 分钟之内。
- TTR(Time to Resolve):问题从开始处理到解决。线上的问题,往往是一些固定类型的问题,我们也有相应的处理手册,所以,简单的问题(如重启一下服务)几分钟能够处理完成;中等的问题(如添置更多的资源),半小时内;复杂的问题,可能一下子没有合适的方案,但我们可以 workaround,也在半小时到一小时间可以解决。
对于研发团队来说,我们要尽可能缩小 TTD / TTA / TTE / TTR,这样才能尽可能先于用户发现问题,在用户抓狂前,把问题解决掉。要缩小 TTD / TTA / TTE / TTR,我们需要知道,how good/bad we are —— 我们目前这些指标的的 max / min / mean 都是什么,这样才能有的放矢地改进。
比如说,TTD 太长,那么,是监控数据收集地不够充分,还是收集好数据却没有设置相应的警报,还是设置好警报,但阈值过于宽泛,这样一层层追溯下来,我们就能够找到并修复监控的问题,进而可以观察下几次事故发生时,TTD 的曲线是否在下降。
以上。
