
AAAI 2020 | 中科大:智能教育系统中的神经认知诊断,从数据中学习交互函数

作者 | 陈恩红、刘淇团队
编辑 | Camel
本文对中国科学技术大学陈恩红、刘淇团队完成,被AAAI-20录用的论文《Neural Cognitive Diagnosis for Intelligent Education Systems》进行解读。
论文链接:https://arxiv.org/abs/1908.08733v1
认知诊断与智慧教育
在许多现实场景如教育、游戏竞技、医疗诊断中,认知诊断是一项十分必要且基础的任务,其中在智慧教育场景应用最为广泛。智慧教育是随大数据时代和人工智能发展而兴起的新型教育方式,采用计算机辅导和线上教学等方式,使教学更高效、智能化,学生学习自主化、个性化。
智慧教育中的认知诊断,通过收集学生的行为记录(通常是答题记录)和试题信息(如试题文本),来推断学生当前的知识状态。例如图1,
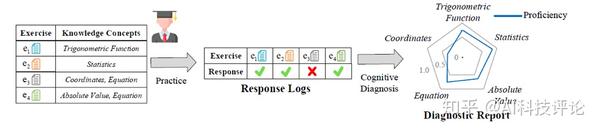

学生选择了一些题目进行练习,得到了对应的答题记录,每道题目包含了特定知识点,通过认知诊断技术得到该学生在各个知识点上的掌握程度。例如学生答对了试题 e_1 ,而e_1包含“三角函数”(Trigonometric Function)这个知识点,因此诊断出来该学生对于“三角函数”这个知识点掌握程度较高(例如0.8),反映到诊断报告的雷达图中蓝线靠近外侧。认知诊断的结果可以被用作教育资源推荐、学生表现预测、学习小组分组等后续教育应用中。
背景
认知诊断并不是一个新兴的概念,在教育心理学领域已有数十年的发展。教育心理学的相关研究中,项目反映理论(Item Response Theory, IRT)和DINA(Deterministic Input, Noisy And)模型是其中最经典的两类工作。IRT模型中,每个学生和试题分别用一个单维的连续变量表征(记为θ和β),其中θ表示学生的综合能力,β表示试题的整体难度。学生和试题之间的关系使用Sigmoid函数建模,一个简单的IRT反应函数中,学生i答对试题j的概率为:
P(r_{ij} = 1 | \theta_i, \beta_j) = \text{sigmoid}(a_j(\theta_i, -\beta_j))
而在DINA模型中,每个学生和试题分别用一个离散向量表征(记为 θ和β),其中试题表征β直接取自Q矩阵的对应行,表示该试题包含的知识点。这里Q矩阵是一个人工标注的试题-知识点关联矩阵,每一行对应一道试题,每一列对应一个预定义的知识点,有:


DINA模型中,学生i与试题j之间的关系被建模为:
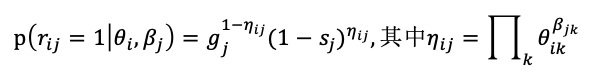

式中 g_j 表示试题的猜对概率, s_j 表示试题的失误概率。其函数基于的假设是:学生要答对试题,需要掌握该试题需要的所有知识点并且不失误,否则只能以概率 g_j 猜对。
尽管后续有许多改进的工作,但整体来说,都是专家设计学生与试题之间的交互函数(例如IRT中的Sigmoid函数),基于一些假设对真实场景进行简化,这样的做法不仅函数设计耗时耗力,而且简化后的函数也难以准确捕捉学生与试题之间真实的复杂关系。因此寻找自动化建模学生与试题之间复杂关系的方法是十分必要的。此外,传统方法只能处理学生-试题组成的数值矩阵,不能建模试题文本等异构信息,这也是需要完善的研究点。
近年来已有使用深度学习方法进行学生建模的研究。以DKT(Deep Knowledge Tracing)为代表的多个知识跟踪工作旨在跟踪学生知识状态的动态变化。然而,这些工作与认知诊断的最大差异在于,它们的主要目标是预测下一时刻学生答对各道题目的概率,多数工作中不严格区分试题与其包含的知识点,因而不具有认知诊断所需要的高度可解释性,不适合直接作为认知诊断方法。
在这样的背景下,我们提出神经认知诊断(Neural Cognitive Diagnosis,NeuralCD)框架,期望利用神经网络,通过简洁的形式设计一类效果好且高度可解释的泛用性认知诊断框架,直接从数据中学习学生与试题之间的交互函数,而非人工设计。并且得益于神经网络在各领域的成功,框架能够利用试题文本等异构数据,提高模型的学习能力。
基于神经网络的认知诊断
1、问题定义
设在一个学习系统中有N个学生,M道试题,K个知识点。学生集合 S=\{s_1,s_2,...,s_N\} ,试题集合 E=\{e_1,e_2,...,e_N\} ,知识点集合 K_n=\{k_1,k_2,...,k_N\} 。学生的答题记录可以表示为三元组 (s, e, r) 的集合 R ,其中 s\in S , e\in E , r 是学生 s 在试题 e 上的得分(转换为百分比)。此外,有将试题与知识点关联的Q矩阵 Q = \{Q_{ij}\}_{M\times K} (例如,有教研专家提前标注)。
给定学生答题记录 R 和 Q 矩阵 Q ,我们的认知诊断的任务是通过学生答题预测的过程获取学生在各个知识点上的掌握程度。
2、神经认知诊断框架
使用神经网络做认知诊断并不容易,一个主要的原因是其广为诟病的“黑盒”特性,即模型参数难以解释,而认知诊断需要得到学生在各个知识点上的掌握程度,因此这是必须跨越的障碍。同时神经网络也带来了新的机遇,其强大的拟合能力使其能够从数据中学到更为复杂且贴近现实的交互函数,且神经网络在自然语言处理方面取得的成功也使将试题文本运用到认知诊断成为可能。
几乎所有传统认知诊断方法都包括学生参数、试题参数、学生与试题交互函数这三个部分,其合理性已被大量工作验证,因此神经认知诊断框架NeuralCD亦沿用此方式,其结构如图2:
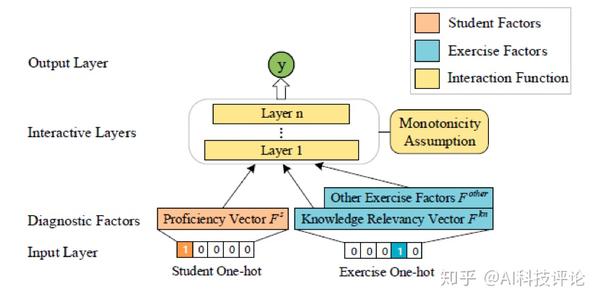

NeuralCD将认知诊断分为三个部分:学生因素、试题因素和交互函数(在图中分别用不同颜色标注)。学生因素最基本的是知识点熟练度向量 F^S ,试题因素则包括基本的知识点相关度向量 F^{kn} 和其他可选因素 F^{other} (如试题难度、区分度等)。交互函数则由多层神经网络构成,这是与传统方法最大的不同点。NeuralCD的输入为答题记录中学生和试题的one-hot向量,输出为学生答对该试题的预测概率。
为了确保训练结束后得到的 F^S 的解释性(即每一维对应该学生在对应知识点上的掌握程度),我们做出如下约束:
1. 输入层需要包含 F^S \circ F^{kn} (“ \circ ”表示按元素乘),这是为了让 F^S 中的每一维都与 F^{kn} 中对应维的知识点对应;
2. 对多层神经网络使用“单调性假设”来约束。单调性假设是教育心理学方法中常用的假设,其内容是:学生答对试题的概率随学生任意一维知识点熟练度单调递增(不需要严格单调)。换句话说,在训练过程中,若模型的预测值小于真实得分,则需要提高该学生的F^S中的值;反之则降低F^S中的值。而具体调整F^S中的哪些维度,则是由 F^{kn} 控制。
3、神经认知诊断模型(Neural Cognitive Diagnosis Model, NeuralCDM)
在NeuralCD的框架下,我们做了一个模型实现,其结构如图3:
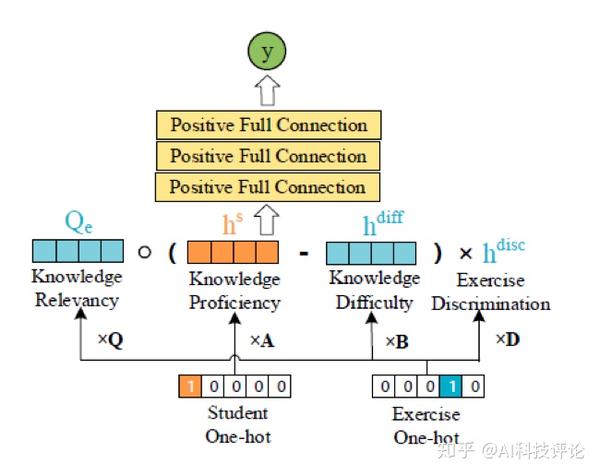

学生的知识点熟练度向量(对应前述的 F^S )在此处具体为 \bold{h}^s = sigmoid(\bold{x}^s \times A) ,其中 \bold{x}^s 是学生的one-hot向量, A 是所有学生的熟练度矩阵。试题因素中知识点相关度向量(对应前述的 F^s )直接取自人工标注的Q矩阵,具体为 Q_e = \bold{x}^e \times Q ,其中 \bold{x}^e 是试题的one-hot向量;此外还使用了试题的知识点难度向量 \bold{h}^{diff}=sigmoid(\bold{x}^e \times B) 表示试题对每个知识点考察的难度,以及试题区分度 h^{disc} = sigmoid (\bold{x}^e \times D) 表示试题区分不同水平学生的能力。A、B、D都是通过数据学习的可训练参数。这样,多层神经网络的输入层为:
\bold{x} = Q_e \circ (\bold{h}^s - \bold{h}^{diff})\times h^{disc}
NeuralCDM不追求模型的复杂性,而是为验证NeuralCD的有效性,因而其交互函数由最常见的多层全连接层构成。为满足单调性假设,我们限定每一层的权值为正(可部分为0),这样
\frac{\partial y}{\partial h^s_i} \geq 0 ,熟练度向量中值 h_i^s 的调整方向与输出的预测值 y 的变化方向一致。最后,训练时采用预测值与真实得分的交叉熵:
loss_{CDM} = - \sum_i (r_i \log y_i + (1-r_i)\log(1-y_i))
训练结束后,学生对应的 \bold{h}^s 即为该学生的诊断结果,每一维对应该学生在该知识点上的掌握程度(范围(0,1))。
4、利用试题文本对NeuralCD扩展
试题文本与试题信息是十分相关的,例如通过试题文本预测试题的难度、区分度、知识点等。这里我们不对所有相关性进行讨论,而是选取其中的一种展示NeuralCD的可扩展性。
在NeuralCDM和一些传统方法(如DINA)中,通过Q矩阵获取试题与知识点的关联信息。然而,人工标注的Q矩阵不可避免地主观性甚至错误。例如,对于一道解方程的问题,专家可能只标注了其中的主要考点“Equation”,但是却忽略了其中乘除法的知识点。而通过试题文本,发现其中包含除法符号“÷”,可以将此知识点补充。基于此,我们利用试题文本对NeuralCDM进行扩展,记为NeuralCDM+,其结构如图4:
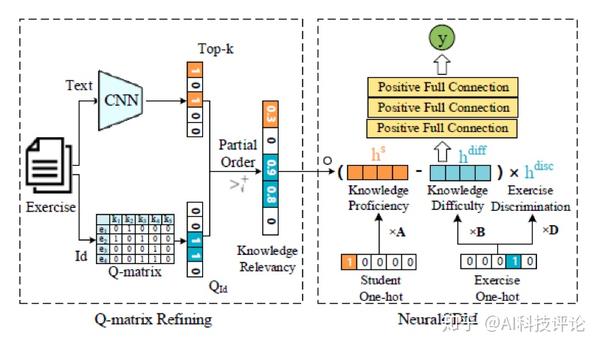

我们首先预训练了一个卷积神经网络(CNN),输入试题文本来预测与试题相关的知识点,取其输出的Top-k知识点集合 V^k_i 作为预测结果。
接下来我们通过将 V^k_i 与Q矩阵结合来得到优化后的 \tilde{Q} 。使用如下的偏序关系表示一道题中各个知识点的相关度:
相关度: Q矩阵标注\geq 预测的Top-k \geq 其他 = 0
这是因为尽管人工标注的Q矩阵存在部分缺点,但仍然具有较高的可信度,因此Q矩阵中标注的知识点最有可能有较高的相关度。而既非标注也未被预测的知识点则认为是与该题无关。我们采用概率模型的方式来实现这一偏序关系,并最终得到经文本预测补充的知识点相关度矩阵 \tilde{Q} ,代替NeuralCDM中的 Q 。
5、NeuralCD的泛化性
NeuralCD是泛化性较强的认知诊断框架,一些传统的认知诊断模型可被视为NeuralCD的特例(如矩阵分解、IRT、MIRT等)。例如,IRT与NeuralCD的关系可被下图5概括,
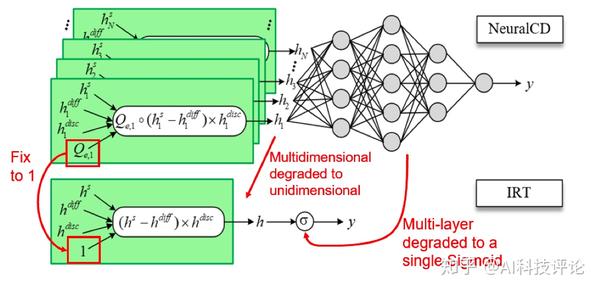

若将NeuralCD从多维退化至一维,知识相关度向量固定为1,并且神经网络构成的交互函数退化为单个Sigmoid函数,模型就退化成了IRT。其他示例和具体推导请参阅论文。
实验
实验在两个数据集上进行。一个是科大讯飞的在线学习平台智学网提供的私有数据集Math,包含多所高中的期末考试试题、文本和答题记录。另一个是公开数据集ASSISTment 2009-2010 Skill-Builder,包含数学试题和学生答题记录。由于后者没有提供试题文本,所以NeuralCDM+并未在该数据集上进行实验。
1、学生答题预测
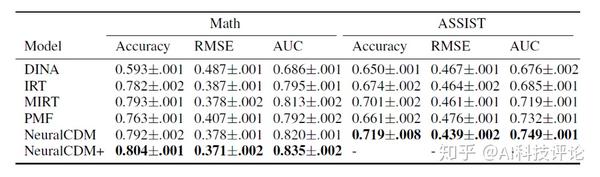
学生真实的知识点熟练度标签是无法获取的,因此我们采用间接衡量诊断结果准确性的方法,即使用学生的诊断结果来预测学生的在非训练数据中试题的得分,这也是传统认知诊断模型的常规做法。实验的结果如下表1,我们的NeuralCD模型在两个数据集中相较传统模型取得了较大的提升。

2、解释性度量
我们希望学生的诊断结果能够符合直觉上的预期:若学生 a 答对了包含知识点 k 的试题 e ,而学生 b 没有答对,那么学生 a 在知识点 k 上的掌握程度( F^s_{ak} )应该更有可能比 b 的( F^s_{bk} )大。为此,我们使用DOA来衡量这一解释性(DOA越高越符合预期):
\text{DOA}(k) =\frac{1}{Z} \sum^{N}_{a=1}\sum^{N}_{b=1}\delta(F^s_{ak},F^s_{bk}) \sum^{M}_{j=1} I_{jk} \frac{J(j,a,b)\wedge \delta(r_{aj},r_{bj})}{J(j,a,b)}
式中 Z 是归一化项。 \delta(x,y)=1 若 x>y ;否则 \delta(x,y)=0 。 I_{jk} =1若试题 j 包含知识点 k ;否则 I_{jk}=0 。 J(j,a,b)=1 若学生 a 和学生 b 都作答了试题 j ;否则 J(j,a,b)=0 。
计算模型诊断结果中平均每个知识点的DOA值,各个模型的结果如下图6:
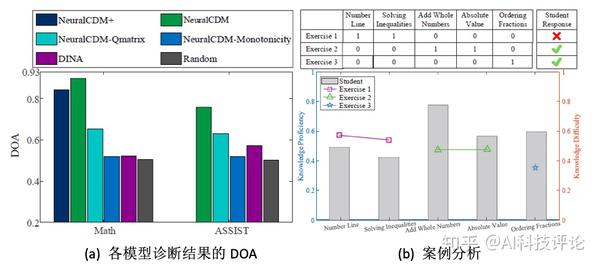

(a)(部分基准模型未做因为其学生向量没有与知识点的对应关系)。(b)是ASSIST数据集中一个学生诊断结果的实例。
上半部分为3道试题的Q矩阵和对应的实际答题结果,下半部分的柱形图为该学生在各个知识点上的诊断出的熟练度,数据点代表3道题所包含知识点的考察难度。诊断结果中,当学生对知识点的掌握程度超过试题的要求时,更有可能答对试题。例如试题2中包含“Add Whole Numbers”和“Absolute Value”这两个知识点,难度分别为0.47和0.48,而该学生在这两个知识点上的掌握度分别为0.77和0.56,超过了难度需求,因此答对了该题。诊断的结果是符合常识认知的。
结语
随着智慧教育的兴起,认知诊断会成为备受重视的任务。传统的认知诊断方法已不在适应当前的多学科、大数据量、异构数据类型的场景。使用神经网络进行认知诊断是值得探索的方向。本文还是初期的探索,在理论上、模型结构上还有许多可以提升的地方,留待未来工作完善。
论文的NeuralCDM代码已公开至https://github.com/bigdata-ustc/NeuralCD,该团队智慧教育研究组的主页:http://base.ustc.edu.cn/。
