
YawMMF package: 因子设计下,线性混合模型分析的“利器”

本文的第一部分的目的是梳理一下我以往关于线性混合模型 (Linear Mixed Model, LMM) 分析的有关文章。第二部分是简单介绍YawMMF数据包
首先,LMM 作为一种高级统计方法,已经越来越多地应用到心理学的多个领域。我在以下这篇文章对该方法进行了简单介绍:
@包寒吴霜 的以下这篇文章也介绍了LMM有关知识:
此外,我与 @包寒吴霜 去年11月在中科院心理所举办了有关LMM的工作坊,相关的PPT都已分享:我主讲的内容 和 包寒主讲的内容。
根据以上的内容,读者可以对“什么是LMM”,以及“如何在R中进行LMM分析”有初步的了解。
但在实际操作中,往往会出现若干问题,以我所了解的,这些问题可分为两类:一是有关模型优化、确定最终模型的问题,二是有关数据分析与获取相应分析结果的问题。对于后者,一旦模型确定下来,R中一般都有对应的函数来解决。但对于如何确定最优模型的,目前来说还没有较确切的解决方法和分析流程。因此接下来这半年我的文章主要围绕“如何筛选最优模型”的问题。
最初时我对模型为何存在无法收敛或畸形协方差矩阵的问题了解甚少,因此想到一个粗暴的方法:遍历所有可能的模型,并从中筛选。
后来,我从模型出现畸形拟合的问题入手,并通过阅读lmerTest包中isSingular()函数的说明文档等方式,对畸形拟合有了初步的了解:
虽然知道当模型出现问题时需要削减随机斜率,但是在实际操作过程中遇到了问题:当因子水平数量超过2时,该因子对应的随机斜率不只有一个, 如果直接删掉该因子,那么会把应该删掉的和不应该删掉的随机斜率一起删掉。
另一方面,我在实际操作中,也意识到因子的对比方式对模型的固定效应和随机效应有影响:
并且逐渐了解几种常见的因子对比方式,在此基础上,了解了如何设计因子的事先对比矩阵:
同时了解到,因子的对比方式其实是对其重新编码,而建模时,模型会用根据因子的对比方式生成的虚拟变量建模。因此我意识到,可以根据因子的对比方式事先生成虚拟变量,再根据虚拟变量建模:
通过用虚拟变量建模的方法,我们可以更自由地调整模型的随机斜率部分了。
在阅读了Bates等人的相关文章后,得知可以用主成分分析的方法来确定模型的随机效应部分哪些成分是有用/合适的。主成分分析,结合事先定义对比矩阵和生成虚拟变量的方法,使得优化模型更高效,更有理论依据:
至此,总结一下在因子设计的实验中,利用LMM数据分析的大体步骤:
- 数据整理&检查:删除数据、变量因子化、描述统计信息、数据检查(异常值、正态性);
- 定义对比方式;
- 生成虚拟变量;
- 建立全模型 或 零相关模型(zero-correlation model);
- 利用主成分分析,删减随机斜率 (iterative reduction);
- 检查新模型和全模型的差异;
- 其他分析:Power分析,获取分析结果,数据可视化等。
针对这些分析步骤,我编写了相应的函数,并整合成数据包,可以帮助用户较快捷地实现模型的筛选和部分零零碎碎的功能:YawMMF package。
该数据包发布在我的 GitHub 上,因此用户需要用以下方式下载(如无必要,请忽视下载过程中有关更新某些数据包的提示):
if(!require(devtools)) install.packages("devtools")
devtools::install_github("usplos/YawMMF")其中的函数大体可分为三类:
- 建模前有关的函数:
MixedModelDataExplore():探索因变量,绘制QQ图,箱线图等,可帮助用户检测数据分布以及是否有异常值;
MixedModelDataSummary():描述统计信息汇总;
- 模型优化有关的函数:
contr.simple():定义simple coding的因子对比方式;
MixedModelDummy():生成虚拟变量;
MixedModelOpt():优化模型;
- 建模后有关的函数:
MixedModelPower():进行Power分析的函数;
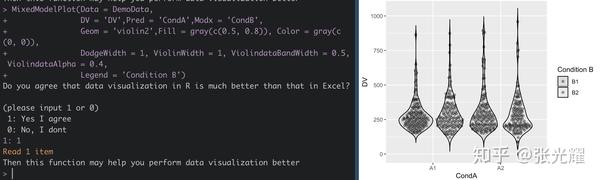
MixedModelPlot():数据可视化的函数,可绘制条形图,折线图,小提琴-箱线图,小提琴-散点图;
MixedModelWrite():支持把模型的固定效应部分或者数据的描述统计信息以csv文件格式存到电脑;
这里展示两个函数的例子:
利用MixedModelOpt()优化模型,函数会根据输入的参数构建全模型(也支持用户手动输入模型),并且按照上文提到的主成分分析等方法,优化模型,并返回生成虚拟变量后的新数据、优化后模型、优化后模型的公式、以及与全模型比较结果等信息。


利用MixedModelPlot()进行数据可视化:



更多的有关函数的信息,用户可查询相应的函数帮助文档。
如下载时遇到问题,请见https://github.com/usplos/YawMMF。
如有其它问题或对该函数包有任何建议,欢迎大家在评论区留言。
