
从零搭建LevelDB--Golang

如今KV数据库已经成为工作中必不可少的一种数据存储模式,首先联想到的就是高并发的代表--Redis,其已经征服了各种领域,如高性能缓存、分布式锁、热点数据存储等。与Redis遥相呼应就是持久型(文件)KV数据库RocksDB,谈论RocksDB将是一个浩大的工程,而RocksDB是基于LevelDB改进而成,因此我们直击它的基础版,也就是我们今天的主角LevelDB,它也是文件型KV存储的代表。 本文对LevelDb的基本实现源代码地址在文末呈上。
LevelDB
LevelDB的本质是Level,也特现在了它的名称上,即我们通过多层文件结构来达到顺序存储KV数据的目的。这句话听起来可能有一些绕口,抛弃你对它的前置观念,让它的架构图来解释这句话。
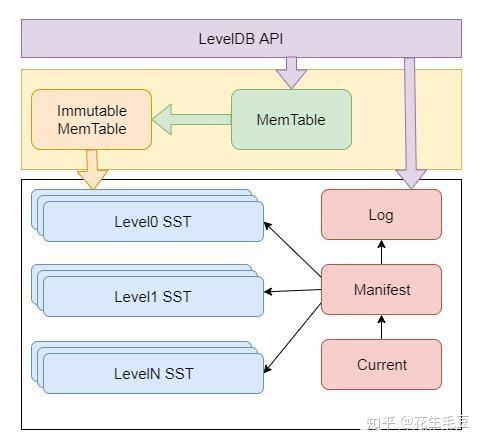

在API做KV插入时是不能保证顺序(即不按KEY排序)的,但是我们在查找时却希望是有序的,顺序KEY最起码可以用二分进行查找而不是遍历。LevelDB最重要的就是在SST上做文章,将插入时的无序演变为有序,最后让二分查找变为现实,后面让我们对各个部分逐一击破。
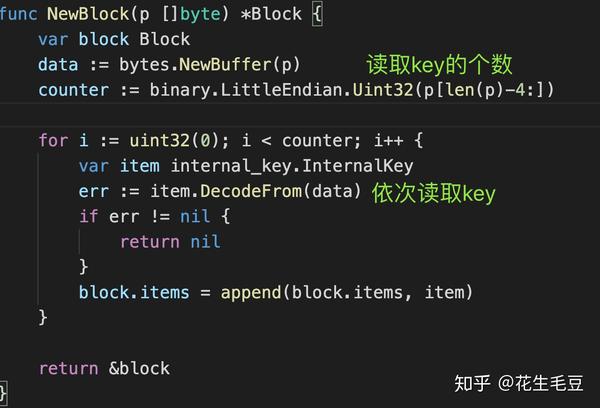
LevelDB中一次完整的数据插入过程,首先数据插入LOG(防止突然的宕机,利于恢复现场)再插入内存MemTable,在一定条件时内存MemTable会演变为内存Immutable MemTable,而内存Immutable MemTable的数据是不可变,同时New一个新的MemTable继续接API传来的数据。接下来Immutable MemTable的数据将会被固化到SST中。SST的文件从level 0开始一路升级打怪直到Level TopN,每次Level升级其实也就是多个低Level的SST文件进行聚合操作。而数据在SST中的文件内将会是有序的。这将便于查找。因此在LevelDB中,数据有可能存在MemTable--> Immutable MemTable --> SST之中,同时表明了数据流的流向过程。
在LevelDB中是没有数据删除的概念,最起码API是不可以主动删除数据,只能是追加一条KEY-DELETE记录,当查找时会发现KEY-DELETE了,视为KEY不存在。这也是为什么LevelDB适合写多读少的场景,因为其采用的日志追加的形式,正常的DELETE需要先GET再DELETE,而LevelDB的DELETE只需要APPEND即可。
了解了LevelDB的大致内部工作原理,来具体看内部各个模块的内容吧。
LevelDB API
LevelDB真的很简单,实现四个基本API即可:GET、PUT、DELETE、Iterator 。按照之前的解释,其中的PUT和DELETE其实又是一个接口,因此本质上只有3个接口即PUT/GET/Iterator。 而这三个API的背后则是需要所有数据存储的模块都实现这四个接口,这样才能整个系统玩得转。
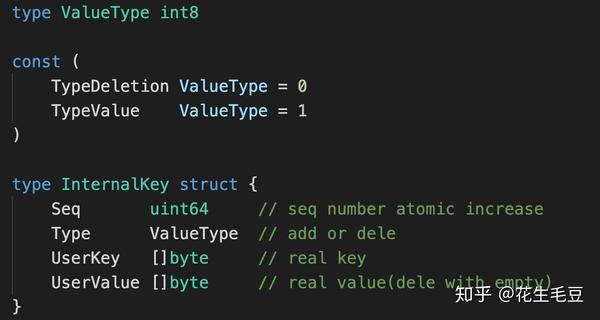
定义KV数据在LevelDB中的存储格式,使用Type字段来表明这是删除or插入一个新Key

MemTable
为了简单实现,我们抛弃了LOG步骤,直接将数据插入MemTable,这对整体DB无其他影响。Log只是为了数据先落盘确保出现宕机状况可以恢复数据。
在MemTable中依旧需要实现GET、PUT、Iterator四个接口。 而MemTable的真实结构为SkipList(跳表),其拥有链表和数组的优势,便于寻找与插入(毕竟LevelDB是没有删除操作的)。 下图展示的是一个skiplist的插入过程。跳表的另一个经典场景就是游戏里面的拍卖行排序,在Redis中也有经典的使用场景。
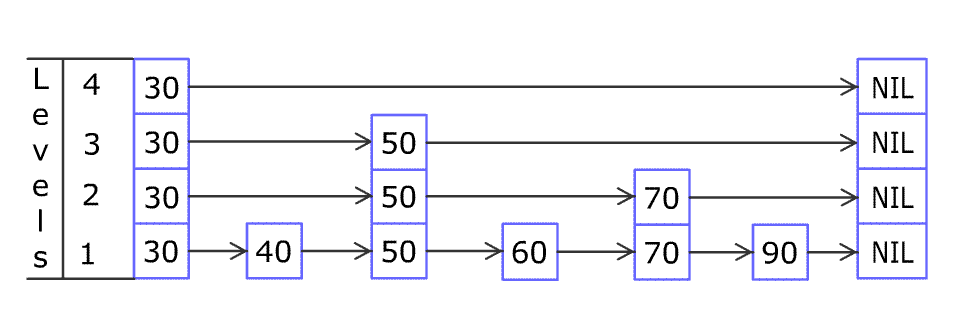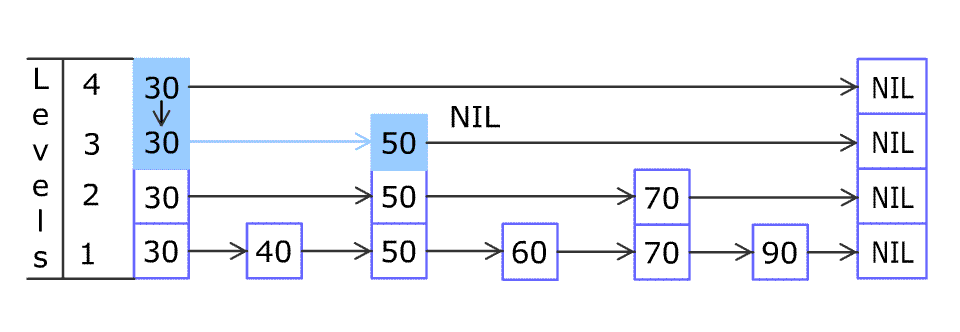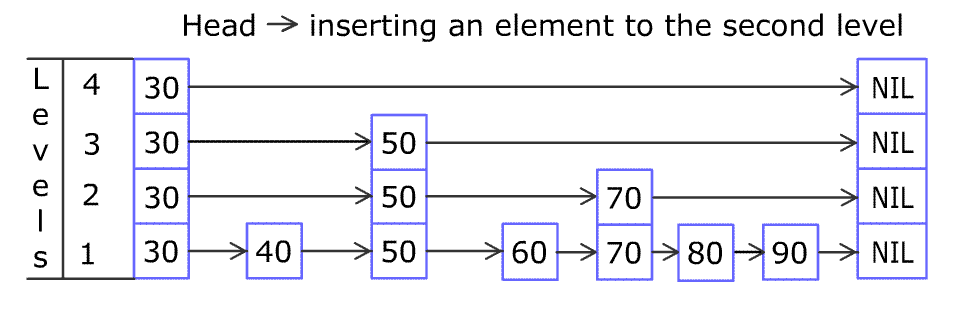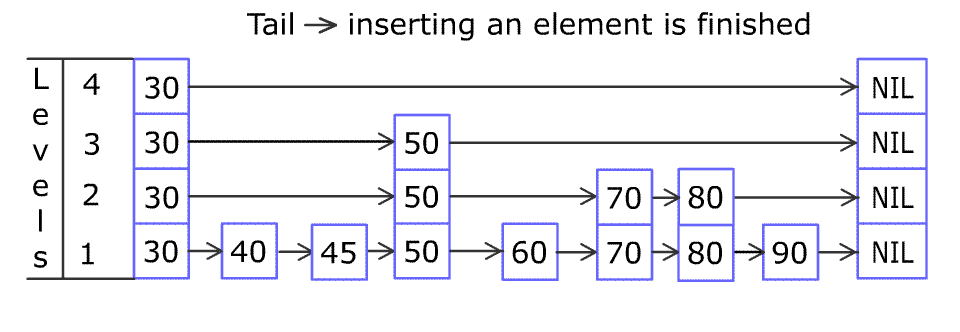

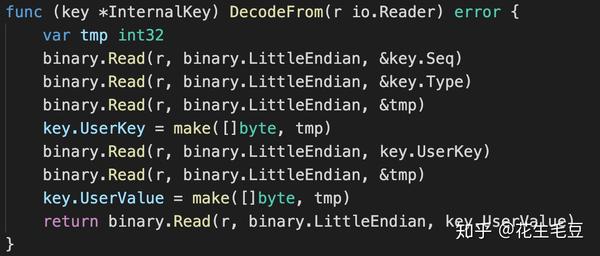
MemTable和SkipList的结构如下代码所示,其中Node的key即LevelDB的数据元素(InternalKey).
- 在执行插入(PUT/DELETE)时按照预设的comparator进行跳表元素大小比较去确定插入位置。比较InternalKey.UserKey,当相同时seq越大表示数据越新。
- 在执行GET时也按照大小比较去寻找有没有对应的KEY即可。
- Iterator就更简单了,按如上动图将level0层直接按链表遍历一边即可。
因此在MemTable中,我们将数据做到了跳表内顺序排列。


Immutable MemTable
Immutable MemTable其实与MemTable是一个东西,只是介于MemTable和SST文件之间的中间产物,在真正固化为SST文件之前不阻塞API继续写入而已。
SST
首先来看一下SST文件的文件结构,SST是分level的,level越高表示单个SST文件越大,内部包含的数据也就越多。同时level 0是由Immutable MemTable转换而来,一个Immutable MemTable固化为一个level 0的SST文件,因此level 0的SST文件之间是未排序的,但单个SST文件内部是排序的。从level 1开始都是由第一级的多个SST文件聚合而来,在聚合过程中就会保证其顺序性,因此自level 1开始,同level的SST文件之间是有排序的。这也不难理解。


- Data Block(s)存储一系列排序的KV值,数据存储内容和格式表示在图中(/是为了分割方便理解,并非真正存在,正在内容就是一堆紧挨着的二进制码)
- Meta Block(s)存储对应Data Block的过滤信息,如布隆过滤器的值,加速Key的查找
- MetaIndex Block存储Meta Block的索引信息
- Index Block存储Data Block(s)的索引信息,包含每个Data Block的最小Key和offset以及整个Block的length
- Footer存储指向MetaIndex、Index Block的索引信息,固定长度
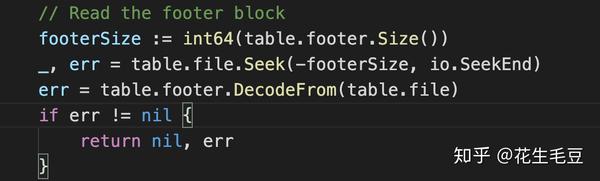
读取SST:按照如图的结构和如上的解释,对单个SST文件的读取(disk文件-->内存结构)应该先移动文件游标到最后,读取出Footer,因为footer是固定长度,很容易根据内容构建出footer对应的结构体。然后再根据Footer的内容移动游标读取MetaIndex和Index Block,再根据对应的信息去读取对应的Data/Index Block。这样一个完整的SST文件就被恢复成内存中的结构化对象。
可能听起来还是有一些云里雾里,但是基本思路就是SST内容是分Block的,
- 先读取Footer获得到MetaIndex和Index Block索引所在offset和length,
- 根据Index Block的offset和length可以将Index Block构建出来
- 再根据Index Block的内容去分Block读取Data Block并依次构建
不如通过一个示例来实操一下读取过程,示例为某个sst文件只存了key为123,value为456的值。使用od读取后的结果如下。
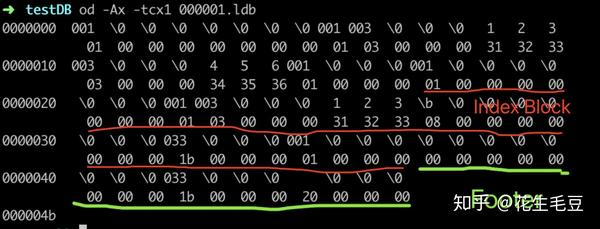

- 先读取Footer, 根据下文Footer的结构体也就是Footer会Encode为4个unit32,也就是占16位,直接游标读取最后的16位(绿色标出)然后还原(小端写入方法),得到MetaIndex的值为0和0,IndexHandle的offset为27,length为32。

- 因为忽略MetaIndex的实现,直接将游标设为offset27,并读取后面的32长度,得到红色部分。Block的部分其实就是紧密的写Key,最后写Block中含有多少Key的个数(uint32),因此先读取最后的4位,得到只写了1个key。然后再读取key即可。单个key也是按照写入方式依次读取的,因为seq(uint64),type(int8)是固定长度可以直接读取,而key和value则是用户自定义的不能直接读取,因此先读取一个len(key)和len(value),根据长度再分别读取真正的字符串。 所以value为 `00 00 00 00 1b 00 00 00`,这个value是作为index而写入的,表明了对应的data block块的offset为0, length为27(1b)。


- 这时候可以去按照index block的内容真正读取data block了,读取方式和读取index block是一致的,这次读取出来的value则是真正的用户写入的value。
seq: 01 00 00 00 00 00 00 00,type: 01,lenkey: 03 00 00,key: 31 32 33,lenvalue: 03 00 00,value: 34 35 36,number of key: 01 00 00。
构造SST-Data Block:按照Immutable MemTable中已排序的kv依次插入,写成Byte流暂存在内存中,等达到一个Block的限制时flush到磁盘,并记录最小Key、offset和length作为Index Block中的一项。其实就是把上述读取过程反转一遍即可。
构造SST-Meta Block / MetaIndex Block: 为了尽可能的简化LevelDB以帮助理解,此文没有实现MetaBlock和MetaIndecBlock,如果按照布隆过滤的方法来算,每一个MetaBlock将是一个根据对应DataBlock中key来构造的布隆过滤表(256字节长度的01值,假设)。那么在读取数据可以先通过布隆过滤器过滤一下来判断此datablock是否有可能存在此key,最终来决定是否读取此DataBlock(因为读取文件的成本很高,所以设计一个过滤器来减少不必要的读取,加快查询速度)
构造SST-Index Block: 伴随着DataBlock的写入,不断积累Data Block的索引信息,信息包含每个DataBlock的最小Key和起始offset以及length
构造SST-Footer: 当内容都写完之后,添加一个固定类型值的Footer用于表明Index Block的offset和length,(还应包含MetaIndex Block的offset和length)。 这样在读取时,就可以直接定位到Index Block。 实际操作中offset和length都是用uint32的值来存储,因此是可以将文件游标移到最后- len(uint32)*2来读取Footer的。


- SST文件的GET: 根据上文对SST文件的构造以及读取方式,在某个SST文件中GET一个key需要先读取Footer,然后根据Index Block中的key来判断目标Key是否在DataBlock中,因为SST文件是按照Key大小顺序排列的,同时IndexBlock中存储着每个DataBlock的最小值,因此可以作为第一层的判断依据。当目标key恰好位于此DataBlock中时,还有MetaIndex中的布隆过滤器再进行依次过滤,其次才是真正的读取整个DataBlock内容,因此查询效率变得更高。
- SST文件的PUT: SST文件都是由Immutable MemTable一次性转变而来,如上文的各类Block构造过程。 并无单独的PUT接口
- SST文件的Iterator: 遍历接口则是根据IndexBlock中的offset和length将每一个DataBlock内容读取并返回。
Version
上文讲了SST的单个文件,但没有讲到SST的Level信息。整个DB需要对SST文件进行管理,包括各层级的文件(s)以及升级(聚合、merge、Level上升)等信息,所以有了Version这个模块,Version是一个一步步向前的演进的模块,同时整个DB架构图中的current文件就是指向Manifest,而Manifest存储的就是对应的最新的Version信息。
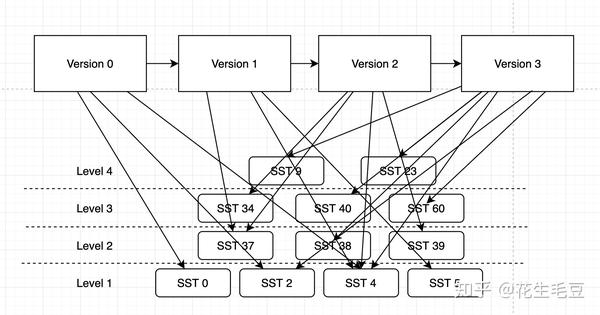

在Version中很重要的一个过程就是将多个Level N的SST文件聚合然后变成更大的Level N+1的文件,在聚合过程中也是要完成排序操作的。 因为Immutable MemTable会变成Level 0的SST文件,也就是说Level 0的SST文件只会文件内部有序,而文件与文件之间无序。这一点需要注意。但是Level 1开始,因为都是聚合而来的,文件与文件之间也是有序乐的。即上图的SST37的Key都会小雨SST38内的Key。
因此当低Level的文件向上合并时,会选取一个或多个高Level的文件进行merge,视低Level的文件最小与最大Key的跨度来决定,如果横跨两个高Level文件则需要两个高Level文件参与。这将会产生一个新的更大的高Level文件。 之后将高Level文件加入到Version中,将之前的参与Merge的低Level与高Level文件移除,并将Version向前移动一步。 SST文件Level的升级过程便完成了。
过程说起来简单,但实际上选取得到低Level中SST文件的跨度以及高Level的SST文件选择也是有技巧的,但是合并过程中就像多个队列一样,因为文件内部都是有序的,我们只需要做多路归并即可。最后的到的大size的高Level文件,这样一层层合并上去,Level越高则文件Size也越大,但是得益于内部有序,以及Index的帮助,在查找时会快速的跨过绝大多数不需要的DataBlock。
总结
其实通过上文的讲解,对LevelDB的整个系统运转过程大致有了一个简单的思路,但这也只是最简版,而且也有一些BUG存在,比如遍历过程中,同一个Key如果先插入后Delete可能会被遍历出来两次,而这就需要更严格的逻辑来确保数据的准确性。但本文的着眼点在于LevelDB的整体思路,并不局限于某个具体的case。 LevelDB不像内存的数据库,可以原地修改,为了数据的Merge需要将多个SST文件读取并重新输出一次,其成本是很高的。而读取的时候为了加速读取,设计了Index Block的布隆过滤器(也可以其他方法替换,满足对应接口即可),减少真正对大文件的读取。
希望通过本文可以帮助你对LevelDB有一个整体的宏观认识。对Level的含义有了自己的解读,对文件存储的读取学会了一个新的技巧(游标的移动设计、index的读取设计)。
列举一个更高级的实现或者思考:
- MetaIndex使用布隆过滤器,即使Key的大小落在此DataBlock内,布隆过滤器可以先过滤一遍,通过了布隆过滤器才表示有可能存在,如果没通过则一定不在。
- 数据压缩,本文都是明文存储的数据有风险也浪费空间降低效率,那么需要合理的压缩算法来压缩文件
- 数据的校验,即使压缩完了,如何保证一个sst文件读取出来是正确的呢,如果中间缺少了一个字节应该如何处理,那么数据的校验工作则是必须考虑的
- 数据库先写Log来保存记录是一种默认的行业潜规则,也是一个灾后重建的恢复依据。
强烈推荐下方链接视频,正是此视频开蒙了作者:
