
把爬虫放到手机上跑!Flutter爬虫框架初探~

最近做毕设需要大量数据训练模型,很多网站又要反爬机制,得爬一会停一会,所以特别慢,要是我用电脑24小时爬虫太费电了,于是想到利用手机~
然后就想到flutter,安卓苹果旧手机都能利用起来做数据采集。
ok,然后就开始做,折腾了一天做了一个大概的框架。总算可以方便的添加爬虫任务了,集成了配置、日志、数据持久化这些基本的功能,然后封装网络请求、网页解析的功能,用起来还行。
只不过众所周知的,dart是一种单线程语言,虽说提供了isolate机制,但是不能共享内存,用起来缚手缚脚的,然后flutter还禁用了反射!谷歌团队真是牛逼,我折腾了一下午之后被这辣鸡玩意气到了,索性弃坑了。
想要实现多线程爬虫的话看来应该是要写一部分原生代码才行,那我还不如全部用原生。。。
(ps:放着好好的Android原生不用,用什么辣鸡flutter做爬虫?? 秀逗了啊,气死我了)

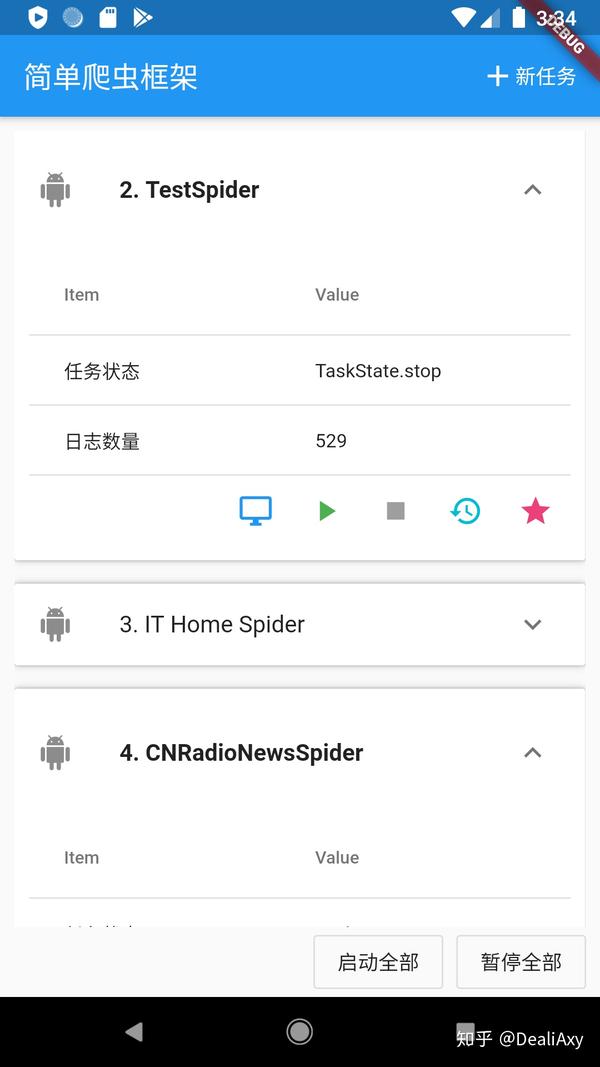
app截图

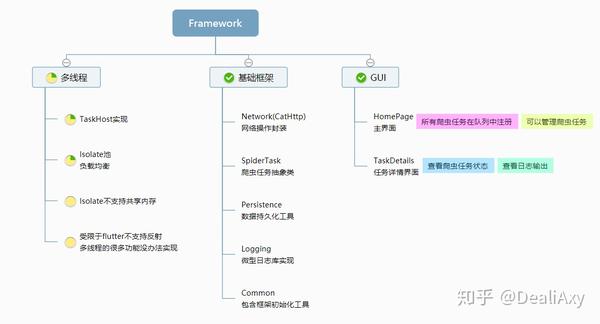
系统架构
画了几个图

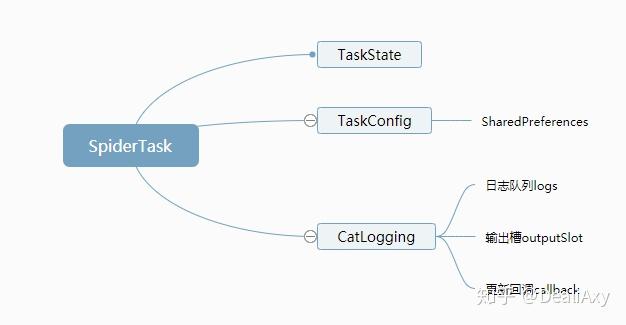
SpiderTask基类,所有爬虫类都从这个类派生,SpiderTask内自己维护一个TaskConfig任务配置对象和一个日志对象。如下图:

至于数据持久化的,我用了另外一个类,采用单例模式,在app启动的时候初始化。


工作流程
- 在home里的任务列表中注册爬虫任务
- 启动app后在主页面管理各个爬虫任务
- 选择一个任务启动
- 进入详情页面会自动与爬虫任务的logging对象进行绑定,可以看到日志输出
简单的例子
写一个简单的例子,运行后会爬取CN Radio网站的新闻。
import 'package:flutter/src/widgets/framework.dart';
import 'package:flutter_spider_fx/framework/index.dart';
class CNRadioNewsSpider extends SpiderTask {
var url = 'http://news.cnr.cn/';
CNRadioNewsSpider(BuildContext context) : super(context, 'CNRadioNewsSpider');
@override
start() async {
super.start();
var dom = await CatHttp.getDocument(url, encoding: 'gb2312');
var links = dom.querySelectorAll('.contentPanel .lh30 a');
links.forEach((link) {
logging.debug(link.attributes['href']);
logging.info(link.text);
});
}
}框架代码
了解详情可以在GitHub查看项目代码~
项目地址:https://github.com/Deali-Axy/flutter_spider_fx
最后提一下:辣鸡flutter,千万别迷信谷歌的技术,这玩意目前仍然是个坑,写个简单GUI实现CRUD还行,高级的玩法就不要想了。

欢迎交流
交流问题请在微信公众号后台留言,每一条信息我都会回复哈~
发布于 2020-02-20 15:50

