
移动设备GPU架构知识汇总

目录
- 移动GPU渲染架构概述
- 真假TBDR
- PowerVR的HSR技术
- Adreno的Flex Render技术
- 基于移动GPU的通用渲染优化建议
- AlphaTest究竟有多耗
一、移动GPU渲染架构概述——TBR/TBDR与IMR
TBR(Tile-Based (Deferred) Rendering)是目前主流的移动GPU渲染架构,对应一般PC上的GPU渲染架构则是IMR(Immediate Mode Renderers)。为什么移动设备的GPU要用这样的渲染架构,以及TBR架构的特点是什么,看下面这三篇文章就行了。其中第一篇应该是我看到过的最新最完备的中文文章了,其中用到的比喻我觉得真的是很形象也很准确,我也没必要再自己写一遍了,直接上链接。
简要概要的总结一下TBR的渲染框架:
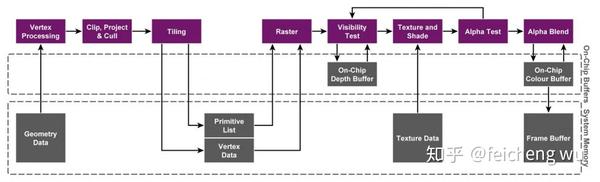

- 缓存所有绘制指令直到最后才开始进行真正绘制
- 首先对所有图元执行VS,把相关的所有绘制数据保存起来
- 计算每个tile都包含哪些图元
- 开始绘制一个tile
- 依次绘制tile中的每个图元
- 把绘制好的tile拷贝到framebuffer对应的位置上
二、真假TBDR
早年间有这样一个说法:
PowerVR的GPU是TBDR架构,别的移动GPU是TBR架构。
这个说法是对的。从官方的表述上来看,只有PowerVR称自己的GPU架构是TBDR,而Adreno和Mali称自己的GPU架构是TBR。这是没有任何的疑问与含糊的地方的。
但是也还有很多技术文章通常会将移动GPU渲染架构都统称为TBDR。这种说法从某种程度上来说也没有错。因为无论是PowerVR的GPU还是Adreno或者Mali的GPU,无论是所谓的TBR还是TBDR,相比于IMR来说都是延迟渲染架构。都是将Rasterize/PS的处理延后到了处理完所有VS之后,而不是像IMR一样VS后马上Rasterize/PS(还有一些中间步骤就省略了,不要缸)。所以说TBR架构也是个延迟渲染架构。
那么为什么只有PowerVR的GPU称其渲染架构为TBDR呢?其他的移动GPU也是Tile-Based也有Defer,怎么就只能叫做TBR呢?原因在于PowerVR的渲染架构中还多了一步Rasterize到PS的延迟,PowerVR为处理这一步延迟的组件起名叫HSR(Hidden Surface Removal)并申请了专利。HSR在下面一部分会进行详细的说明,这里简单直接的描述一下PowerVR的TBDR架构与其他移动GPU的TBR架构的区别:
- TBR:VS - Defer - RS - PS
- TBDR:VS - Defer - RS - Defer - PS
第一个Defer大家都有,而且通过第一篇链接的文章我们可以明白,第一个Defer是Tile-Based渲染架构所必须的,没有这个Defer,Tile-Based优势就无从发挥。而第二个Defer则是Power VR的TBDR架构所特有。通过这第二个Defer,PowerVR的渲染架构真正最大程度上实现了“延后(Defer)PS的执行”,以避免执行不必要的PS计算与相关资源调用的带宽开销,以达到最少的性能消耗和最高的渲染效率。
TBDR是由PowerVR所提出的说法,意在于表示自己的架构是基于TBR架构的改进,并实现了最大程度的DR。因此要严格论起来,其他移动GPU是没有资格称其架构为TBDR的,他们只是TBR。分享一个文章链接,其中PowerVR控诉其他芯片厂商偷换TBDR的定义以混淆这二者,以此掩盖TBR与TBDR仅从设计上的就产生的巨大性能差异。
总结一下,当你在各种技术文章中看到TBDR的表述时,一定要弄清楚这其中的D代表什么意思。如果文章是在讨论任意一种移动GPU与PC GPU的对比,那么这时候的D所强调的是VS与RS之间的延迟,不太严谨的话是可以代表所有的移动GPU框架。而如果文章是在对比PowerVR的GPU与其他移动GPU的渲染架构的话,此时的D所强调的是RS与PS步骤间的延迟,此时TBDR只代表PowerVR GPU的渲染架构。
三、PowerVR的HSR技术 —— 硬件实现的Overdraw优化
HSR(Hidden Surface Removal)技术的概念和原理其实真的非常简单,没有多深奥。
介绍HSR之前先简述一下EarlyZ。EarlyZ优化已经是现代GPU的标准流程了,简单来说就是当不透明的图元从Rasterize阶段开始逐像素进行处理时,首先进行Depth Read & Test,通过后直接Write,后续再执行该像素上的PS程序,否则就可以停下来休息等待下一个要处理的像素了。后续又进一步对于那些在PS阶段会改变深度写入的图元(有discard/clip指令或有ZOffset)加入了 Depth Read & Test -> PS -> Depth Read & Test & Write 流程。总之简单一句话就是,绘制前先做深度检测,减少不必要的绘制。
这也是为什么我们在渲染不透明物体时要按从近到远的顺序去绘制,因为近处的物体先绘制好之后,其写入的深度会阻挡住后面物体的ZTest,也就避免了后面物体无意义的渲染开销。
基于EarlyZ是无法完全的避免Overdraw的。这是因为我们在真正对一个复杂场景去渲染的时候是不可能进行严格的由近到远的绘制的。一个面积很大的地块与远处的物体相比谁应该算“近”呢? 一个有凹面的物体,其上每个图元的的渲染顺序也会因视角不同而会出现先绘制远处三角面再绘制近处的情况。想把物体拆碎?那意味着drawcall增加。完全严格的前后物体排序?那很可能意味着Shader切换次数的增加。
基于硬件EarlyZ特性对渲染物体进行排序优化对于移动GPU也是同样适用的 —— 除了PowerVR,因为人家真正的TBDR渲染框架能做得更好。
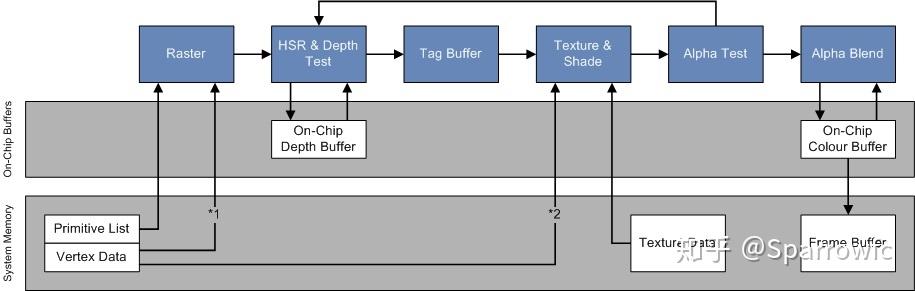

这里HSR登场了,不需要在软件层面对物体进行排序,HSR在硬件上实现了零Overdraw的优化。原理也超简单,当一个像素通过了EarlyZ准备执行PS进行绘制前,先不画,只记录标记这个像素归哪个图元来画。等到这个Tile上所有的图元都处理完了,最后再真正的开始绘制每个图元中被标记上能绘制的像素点。这样每个像素上实际只执行了最后通过EarlyZ的那个PS,而且由于TBR的机制,Tile块中所有图元的相关信息都在片上,可以极小代价去获得。最终零Overdraw,毫无浪费,起飞。
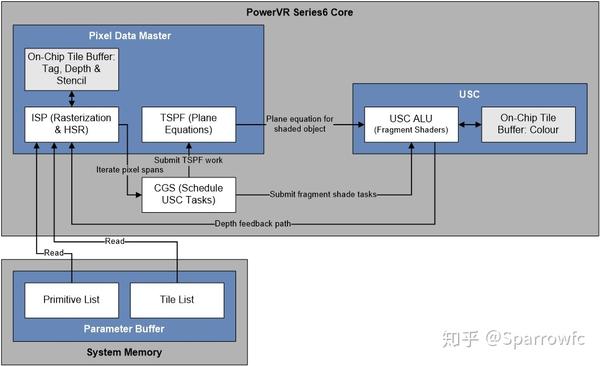

最后说一下HSR是怎么处理AlphaTest和AlphaBlend的。HSR在设计原理上高到飞起,但前提是假定了前面的物体会挡住后面的物体,因此对于AlphaTest和AlphaBlend物体都是没有作用的(但他俩仍然可以被EarlyZ拦住)。不仅没作用,反而会被其中断Defer流程,导致渲染性能降低。(这里要加黑强调一下,所谓导致渲染性能降低只是与不透明物体相比较降低了,而不是说PowerVR在处理AlphaTest/Blend时比别的GPU慢。打个比方:原来大家都走路,PowerVR骑自行车,现在遇到AlphaTest,PowerVR会改成下来推车走)
如果在HSR处理不透明物体的过程中突然来了一个AlphaTest的图元,那么为了保证渲染结果正确,HSR就必须要终止当前的Defer,先把已标记好的像素都绘制出来,再进行后面的绘制。这显然严重影响了渲染的效率,也是为什么官方文档特意提到尽量避免AlphaTest的原因。相对应的AlphaBlend同样也要中断HSR的Defer,强制开始绘制,但是比AlphaTest好那么一点点的是他不影响后续图元并行地继续开始进行HSR处理,有兴趣可以参考下面的官方技术文档链接,里面详细说明了HSR是怎么应对AlphaBlend和AlphaTest绘制的。
最后总结下,在PowerVR上渲染,因为有HSR的存在我们只需要把所有不透明物体放到一起扔给GPU画就行了;在其他移动GPU上,同样也是要把所有不透明物体放到一起,但是还要先做个排序再交给GPU。而对于爹娘不爱的AlphaTest我们到底怎么画才最好,文章的最后一部分会有说明。
四、Adreno的Flex Render技术 —— Flex Render真的比TBDR高到不知道哪里去了么?
这一段其实可以跳过,与优化的关系不大,可以当个小知识看。起因是看到一位大神的上古回答导致我误入歧途(也就是此段的副标题),如果有同样误入歧途的小伙伴请赶快迷途知返。
PowerVR有自己专有的秘密武器HSR,并且申请了专利不让别人用。但是不甘示弱的Adreno也搞了个叫做Flex Render的专属武器。
这个Flex Render的功能就是智能的在某些时候将渲染流程由TBR切换为IMR,也就是直接渲染到FrameBuffer。很明显根据TBR/TBDR的设计特点,当渲染目标足够小的时候IMR相比TBR/TBDR就有了更高的执行效率,毕竟省去了binning(把图元分配到关联的Tile上)和拷贝操作。这个Flex Render的作用,就是根据渲染目标的大小让GPU的渲染模式在TBDR和IMR中自动切换。
可以进行推测的是,比如在Bloom后处理的Downsample阶段,或者是生成Tonemapping LUT的阶段,Adreno GPU很可能都会通过Flex Render将这些渲染过程改为IMR流程去执行。
但是其实在讨论渲染优化的一般情况下,我们都是针对TBR/TBDR来进行分析。Flex Render与在应用层利用硬件特性去优化渲染没有什么太大关系,也没有必要为此做深入考虑。
关于Flex Render详情确认可以参考官方文档第14页到15页
五、移动设备渲染通用优化建议
了解了移动GPU的设计架构,就能明白:移动GPU相对于桌面GPU来说最大的区别就是带宽的开销成本很高。因此任何有高带宽开销成本的操作都具有高性价比优化的潜力。
降低Shader的复杂度固然是通用的降低GPU开销的方式,但如果还考虑到耗电或发热问题的话,带宽开销应该是最为重点的关注。
针对于带宽的优化具体来说可以有以下几点:
- 贴图格式能压缩就压缩。贴图内存越小,片上命中率就越高,总的传输量也少
- 能开mipmap就开mipmap(前提是能用到,UI贴图就不用开了)。与减小实际使用的贴图内存是一个道理,但是会增加总贴图的内存占用大小,需要在内存开销和带宽开销上做一个平衡。
- 随机纹理寻址相对于相邻纹理寻址有显著开销。提高片上命中率。
- 3DTexture Sampling有显著的开销。3DTexture整体内存占用大,垂直方向相邻像素内存不相邻很容易cache miss,这是我个人推测。
- Trilinear/Anisotropic相对于Bilinear有显著的开销。Trilinear其实就相当于tex3D了(此结论不负责任),Bilinear相对于Point几乎没有额外开销(此结论负责任,texture fetch都是一次拿相邻的四个出来),所以Bilinear能忍就尽量凑合用着吧。
- 使用LUT(look up texture)很可能是负优化。需要对比权衡带宽占用+texture fetch操作增加与ALU占用增加降低并行效率,另外还很可能涉及到美术工作流和最终效果,所以是个不是很好进行操作的优化。之前看过腾讯的技术分享将引擎中Tonemapping那步的3DLUT(UE4和Unity都是这样的)替换为函数拟合的优化,理论上应该是会提升不少性能,但是要想真正应用到生产环境,保证效果,还要做好拟合工具链,是得费不少力气的
- 通道图能合并就合并,减少Shader中贴图采样次数。这个不多说了
- 控制Framebuffer大小。这个也不多说了
- 总顶点数量也是带宽开销的影响因素。虽然以现在GPU的计算能力来说,顶点数增多产生的VS计算开销增加通常是忽略不计的。但是仍不能忽略总顶点数量对于VertexBuffer所消耗带宽的影响,对于总顶点数的限制应该更多的从带宽消耗上去进行测试和分析。
另外还有一些优化点,一般来说引擎都给弄好了,不是特别作应该都碰不到,也简单列一下:
- 任何必要情况下(比如新一帧绘制前)都应该显式地对FrameBuffer进行Clear操作。
- 不要在一帧的绘制中多次更新VBO。
以上优化建议都是适用于PowerVR、Mali、Adreno任何一款GPU的。在他们各自的文档中都有提到,我只是做一个汇总。
PowerVR开发者指南 | Adreno开发者指南 | Mali优化指南
六、AlphaTest究竟有多耗
写不动了,先放结论吧,适用于任何移动GPU(对,没有写错,对于AlphaTest的优化与PowerVR/TBDR/HSR无关)。另外也说明一下,有些结论都是我的推论,错了不负责,欢迎指正与讨论。推导是基于TBR/TBDR的每个流程节点GPU都是去并行处理图元或像素的,如果只是基于线性的流程去进行分析是推不出任何有意义的结果的:
- 只要Shader中包含discard指令的都会被GPU认为是AlphaTest图元(GPU对于AlphaTest绘制流程的判定是基于图元而不是像素)
- 无论是PowerVR还是Mali/Adreno芯片,AlphaTest图元的绘制都会影响整体渲染性能。
- 随着芯片的发展AlphaTest图元对于渲染性能的影响主要在于Overdraw增加而非降低硬件设计流程效率,其优化思路与AlphaBlend一样,就是少画!
- 严格按照Opaque - AlphaTest - AlphaBlend的顺序进行渲染可以最大化减小AlphaTest对于渲染性能的影响。
- 将Opaque, AlphaTest与AlphaBlend打乱顺序渲染会极大的降低渲染性能,任何情况下都不应该这么做。
- 不要尝试使用AlphaTest替代AlphaBlend,这并不会产生太多优化。
- 不要尝试使用AlphaTest替代Opaque,这会产生负优化
- 不要尝试使用AlphaBlend替代AlphaTest,这会造成错误的渲染结果。
- 在保证正确渲染顺序情况下,AlphaTest与AlphaBlend开销相似,不存在任何替代优化关系
- 增加少量顶点以减少AlphaTest图元的绘制面积是可以提升一些渲染性能的。
- 首先统一绘制AlphaTest图元的DepthPrepass,再以ZTest Equal和不含discard指令的Shader统一绘制AlphaTest图元,大多数情况下是可以显著提升总体渲染性能的(需要实际测试)