
SAC论文解读以及简易代码复现

一、背景:
在SAC提出之前,主流的Model-Free RL方法,在面向实际应用时都存在着以下几点缺陷:
- 采样效率低:主要为TRPO/PPO等On-Policy方法的不足。由于每一次策略更新都需要在当前策略下重新采样足够多的样本数,完全抛弃之前的采样数据,需要非常高的样本数以及样本复杂性才能保证收敛。
- 对超参数极其敏感:主要为DDPG/D4PG等Off-Policy方法的不足。虽然使用Replay Buffer解决了样本利用效率问题,但是策略与Q-value相互耦合,使其性能不稳定,容易受超参的影响。
在这篇文章里,我们将介绍Berkeley出品的Soft Actor-Critic(SAC,Haarnoja et al)[1]算法,该算法整合了:Actor-Critic、Off-Policy、Maximum Entropy Model 三大框架,极大程度的解决了以上RL算法的缺陷,相较于传统RL方法,也有着全新的贝尔曼方程表达式,同时在机器人等连续控制任务中有着非常出色的表现。
二、理论:
2.1 为什么SAC算法有着出色的控制性能?
相信对RL算法有一定基础的朋友对Actor-Critic和Off-policy方法并不陌生,DDPG、TD3都是使用此类框架的算法,但是为什么SAC算法在连续控制任务上表现更加出色,所以这很直觉的告诉我们Maximum Entropy Model(最大熵模型),是SAC有着出色控制性能的关键所在,接下来我将一一解释什么是最大熵模型以及最大熵RL模型的好处。
- 最大熵:
首先,我们先解释下什么是熵:熵定义为信息量的期望,是一种描述随机变量的不确定性的度量,它的计算公式如下所示。比较直观的说,当随机事件(变量)不确定性越大时,熵越大;相反,如果该随机事件是一确定性事件,则它的熵为零。

那什么时候随机事件的不确定越大呢?答案是:当随机事件中每一种可能发生的概率相等,即随机事件服从均匀分布,也就是P(x1)=P(x2)…=P(xn)时,熵最大。有兴趣看详细描述的同学可以看这里[2]。从本质上来说,最大熵模型的意义就是:在满足已知知识或者限定条件下,对未知的最好推断是随机不确定性的(各随机变量等概率)。
- SAC中的最大熵模型:
在RL算法中,我们希望策略能够尽可能的去探索环境,获得最优策略,但是如果策略输出为低熵的概率分布,则可能会贪婪采样某些值而陷入困境。怎样才能在获得足够多的回报同时对未知状态空间进行合理的探索呢? 最大熵RL模型便能很好的满足这一需求:在满足限定条件下(获得足够多的回报),对未知状态空间等概率随机探索。
所以在SAC中,我们的目标函数包含了回报和策略熵,我么要求策略π不仅能最大限度地提高最终回报,而且还要求最大化熵。


SAC通过最大熵鼓励策略探索,为具有相近的Q值的动作分配近乎均等的概率,不会给动作范围内任何一个动作分配非常高的概率,避免反复选择同一个动作而陷入次优。同时通过最大化奖赏,放弃明显没有前途的策略(放弃低奖赏策略)。总的来说最大熵的好处就是:
- 在最大化奖赏的同时,鼓励探索(我们的最大熵目标可以让动作更均匀的分布,因为当policy输出的动作为等概率时,熵最大)
- 可以学到更多近优策略,提高了算法的鲁棒性
- 训练速度加快(最大熵使探索更加均匀)
2.2 表格型SAC推导
2.2.1 soft policy evaluation
对于一个固定的策略π,其软Q值可以通过Bellman backup 算子迭代出来:
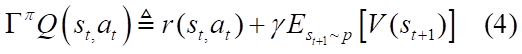

其中:
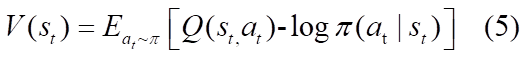
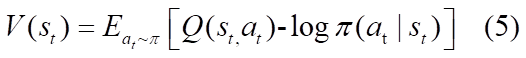
由以下引理1(公式4即Lemma1中的Equetion2)可知:soft policy evaluation可以通过 Q^{(k+1)}=\Gamma^π Q^k进行迭代,若迭代无限次,这样最终Q会收敛到固定策略π下的软Q值函数。


2.2.2 policy improvement
在策略改进中,我们有\pi_{new}(a_{t}|s_{t})\propto{exp(Q^{\pi_{old}}(s_{t},a_{t}))},这与往常off-policy方法最大化Q值不同的是,在SAC中策略是更新向正比于Q的指数分布。如下图所示,我们将策略分布更新为当前Q函数的softmax分布(多峰),而不是向往常一样的高斯分布(单峰)。
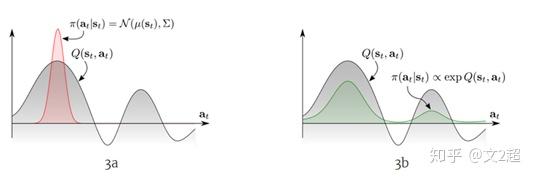

但是在实际操作中,为了方便策略的处理,我们还是将策略输出为高斯分布,通过最小化KL散度去最小化两个分布的差距。
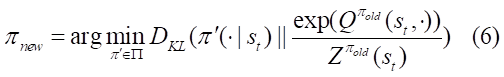

其中 Z^{\pi_{old}}(s_{t}) 为对Q值进行归一化分布。我们的策略 \pi\in\Pi ,被约束在参数空间 \Pi 中。由引理2(Lemma2中的Equetion4为公式6)可知:对于所有的 (s_{t},a_{t})\in{S \times A} ,满足 Q^{\pi_{new}}(s_{t},a_{t})\geq Q^{\pi_{old}}(s_{t},a_{t}) ,这样保证每次更新策略至少优于旧策略。


此外,我们可以证明最小化策略分布与Q函数指数分布的KL散度,与最大化我们的目标函数是等价的:
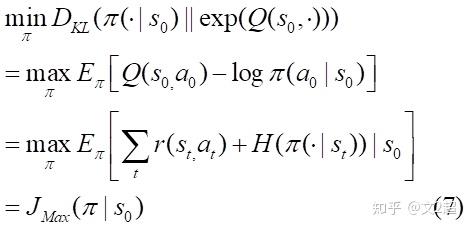

2.2.3 Soft Policy Iteration


与上图传统RL策略迭代求解类似,这一步便是上文中的Soft Policy Evaluation和Soft Policy Improvement两个过程交替迭代求解,通过定理1可知:最终策略 \pi 会收敛到最优策略 \pi^{*} ,对于所有的 \pi\in\Pi ,以及 (s_{t},a_{t})\in{S \times A} ,满足 Q^{\pi_{*}}(s_{t},a_{t})\geq Q^{\pi}(s_{t},a_{t})


2.3 基于神经网络近似的SAC
以上方案保证了策略在状态动作空间是有限、离散的,不使用函数逼近情况下收敛,能获得最优策略,但是对于具有高维、连续状态动作空间的控制任务,通常不可能找到MDP的精确解决。因此,我们必须利用神经网络近似来找到SAC的最优策略。
在这里我们用神经网络定义了软值函数 V_{\psi}(s_{t}) 、软Q值函数 Q_{\theta}(s_{t},a_{t}) 以及策略函数 \pi_{\phi}(a_{t}|s_{t}) ,其中策略输出动作的高斯分布的均值与方差。另外,借鉴了DQN算法的target网络。SAC中隐式定义了一个软Q值函数的target网络 \hat{Q}_{\theta}(s_{t},a_{t}) , 使用V_\hat{\psi}(s_{t}) 网络来的实现。下面我们来看下各个函数的更新方式。
- V值函数 V_{\psi}(s_{t}) 的目标函数使用MSE最小化残差(其实根据上文公式5可知,V值函数可以由软Q值函数替代,完全可以不用重新定义一个网络,在这里作者说是为了稳定训练,但是第二版论文[3]又删去了V值网络):
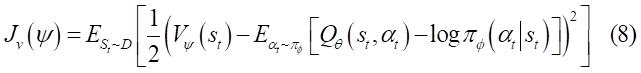

其中状态s是Replay Buffer D中采样得到,动作a是根据当前策略计算而来。梯度为:
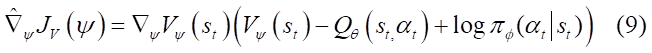

- 软Q值函数 Q_{\theta}(s_{t},a_{t}) 的目标函数也使用MSE最小化软贝尔曼残差(soft Bellman residual):
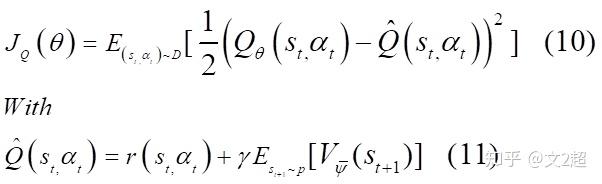

其中 V_\hat{\psi}(s_{t}) 为target network,目的是为了稳定软Q网络的训练,状态s和动作a都是采样得到的。该更新方式与DQN也基本一致,这也是SAC的off-policy之处,只不过更新的是软Q网络。梯度为:


- 我们的策略 \pi_{\phi}(a_{t}|s_{t}) 的目标函数便是最小化两分布之间的KL散度:
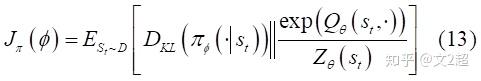

我们把KL散度根据定义化简出来,函数Z视为配分函数,独立于策略参数 \phi 可以省略,便得到了新的目标函数:


由于策略是一个分布,动作a采样后无法对其进行求导,所以在这里使用了re-parameterization[4]技术来对动作采样,我们在这里令:
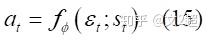
\epsilon_{t} 为输入的噪声向量,一般为标准正态分布,把动作函数带入目标函数14,便得到了与文章中相同的目标函数:
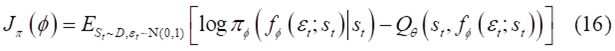

梯度为:
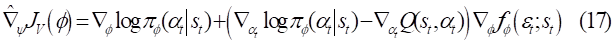

- 整个算法流程就如下所示:


三、核心代码:
测试环境使用的是gym中的"Pendulum-v0",基于Pytorch的简易实现,完整实现代码在这[5],参考了知乎某大佬的实现[6]。
- 定义网络
# Value Net
class ValueNet(nn.Module):
def __init__(self, state_dim, edge=3e-3):
super(ValueNet, self).__init__()
self.linear1 = nn.Linear(state_dim, 256)
self.linear2 = nn.Linear(256, 256)
self.linear3 = nn.Linear(256, 1)
self.linear3.weight.data.uniform_(-edge, edge)
self.linear3.bias.data.uniform_(-edge, edge)
def forward(self, state):
x = F.relu(self.linear1(state))
x = F.relu(self.linear2(x))
x = self.linear3(x)
return x
# Soft Q Net
class SoftQNet(nn.Module):
def __init__(self, state_dim, action_dim, edge=3e-3):
super(SoftQNet, self).__init__()
self.linear1 = nn.Linear(state_dim + action_dim, 256)
self.linear2 = nn.Linear(256, 256)
self.linear3 = nn.Linear(256, 1)
self.linear3.weight.data.uniform_(-edge, edge)
self.linear3.bias.data.uniform_(-edge, edge)
def forward(self, state, action):
x = torch.cat([state,action], 1)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = self.linear3(x)
return x
# Policy Net
class PolicyNet(nn.Module):
def __init__(self, state_dim, action_dim, log_std_min = -20, log_std_max=2, edge=3e-3):
super(PolicyNet, self).__init__()
self.log_std_min = log_std_min
self.log_std_max = log_std_max
self.linear1 = nn.Linear(state_dim, 256)
self.linear2 = nn.Linear(256, 256)
self.mean_linear = nn.Linear(256, action_dim)
self.mean_linear.weight.data.uniform_(-edge, edge)
self.mean_linear.bias.data.uniform_(-edge, edge)
self.log_std_linear = nn.Linear(256, action_dim)
self.log_std_linear.weight.data.uniform_(-edge, edge)
self.log_std_linear.bias.data.uniform_(-edge, edge)
def forward(self, state):
x = F.relu(self.linear1(state))
x = F.relu(self.linear2(x))
mean = self.mean_linear(x)
log_std = self.log_std_linear(x)
log_std = torch.clamp(log_std, self.log_std_min, self.log_std_max)
return mean, log_std
def action(self, state):
state = torch.FloatTensor(state).to(device)
mean, log_std = self.forward(state)
std = log_std.exp()
normal = Normal(mean, std)
z = normal.sample()
action = torch.tanh(z).detach().cpu().numpy()
return action
# Use re-parameterization tick
def evaluate(self, state, epsilon=1e-6):
mean, log_std = self.forward(state)
std = log_std.exp()
normal = Normal(mean, std)
noise = Normal(0,1)
z = noise.sample()
action = torch.tanh(mean + std*z.to(device))
log_prob = normal.log_prob(mean + std*z.to(device)) - torch.log(1 - action.pow(2) + epsilon)
return action, log_prob使用Actor-Critic框架,根据算法定义了V网络、SoftQ网络和Policy网络,每个网络最后输出层参数都裁剪到[-3e-3, 3e-3]范围内。Policy网络输出均值(mean)和标准差的对数(log_std),然后对动作空间高斯分布进行采样,使用tanh函数将其裁剪到[-1,1],得到输出动作。
值得注意的是Policy网络中的evaluate函数,在这里我们使用了re-parameterization技术来计算策略熵:我们在标准正太分布N(0,1)中采样噪声,将其与policy网络输出标准差相乘,然后加上均值,最后使用tanh函数裁剪,便得到了我们的评估动作,然后计算策略熵。
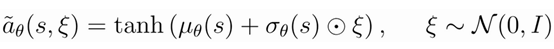

特别的是,动作本应该无界高斯分布,但是我们使用了tanh函数限定了边界,所以我们需要在原始熵计算公式后添加一项修正系数。
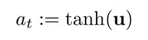
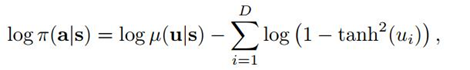

- 定义SAC Agent
class SAC:
def __init__(self, env, gamma, tau, buffer_maxlen, value_lr, q_lr, policy_lr):
self.env = env
self.state_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.shape[0]
self.action_range = [env.action_space.low, env.action_space.high]
# hyperparameters
self.gamma = gamma
self.tau = tau
# initialize networks
self.value_net = ValueNet(self.state_dim).to(device)
self.target_value_net = ValueNet(self.state_dim).to(device)
self.q1_net = SoftQNet(self.state_dim, self.action_dim).to(device)
self.q2_net = SoftQNet(self.state_dim, self.action_dim).to(device)
self.policy_net = PolicyNet(self.state_dim, self.action_dim).to(device)
# Load the target value network parameters
for target_param, param in zip(self.target_value_net.parameters(), self.value_net.parameters()):
target_param.data.copy_(self.tau * param + (1 - self.tau) * target_param)
# Initialize the optimizer
self.value_optimizer = optim.Adam(self.value_net.parameters(), lr=value_lr)
self.q1_optimizer = optim.Adam(self.q1_net.parameters(), lr=q_lr)
self.q2_optimizer = optim.Adam(self.q2_net.parameters(), lr=q_lr)
self.policy_optimizer = optim.Adam(self.policy_net.parameters(), lr=policy_lr)
# Initialize thebuffer
self.buffer = ReplayBeffer(buffer_maxlen)
def get_action(self, state):
action = self.policy_net.action(state)
action = action * (self.action_range[1] - self.action_range[0]) / 2.0 +\
(self.action_range[1] + self.action_range[0]) / 2.0
return action
def update(self, batch_size):
state, action, reward, next_state, done = self.buffer.sample(batch_size)
new_action, log_prob = self.policy_net.evaluate(state)
# V value loss
value = self.value_net(state)
new_q1_value = self.q1_net(state, new_action)
new_q2_value = self.q2_net(state, new_action)
next_value = torch.min(new_q1_value, new_q2_value) - log_prob
value_loss = F.mse_loss(value, next_value.detach())
# Soft q loss
q1_value = self.q1_net(state, action)
q2_value = self.q2_net(state, action)
target_value = self.target_value_net(next_state)
target_q_value = reward + done*self.gamma*target_value
q1_value_loss = F.mse_loss(q1_value, target_q_value.detach())
q2_value_loss = F.mse_loss(q2_value, target_q_value.detach())
# Policy loss
policy_loss = (log_prob - torch.min(new_q1_value, new_q2_value)).mean()
# Update v
self.value_optimizer.zero_grad()
value_loss.backward()
self.value_optimizer.step()
# Update Soft q
self.q1_optimizer.zero_grad()
self.q2_optimizer.zero_grad()
q1_value_loss.backward()
q2_value_loss.backward()
self.q1_optimizer.step()
self.q2_optimizer.step()
# Update Policy
self.policy_optimizer.zero_grad()
policy_loss.backward()
self.policy_optimizer.step()
# Update target networks
for target_param, param in zip(self.target_value_net.parameters(), self.value_net.parameters()):
target_param.data.copy_(self.tau * param + (1 - self.tau) * target_param) 在这里我们初始化了网络,与原文不同的是,我这里使用了两个Q网络,目的是为了减少Q值的过高估计。其中loss的计算方式都保持与原文一致,Q值选取双Q中较小的一个。
- 超参
env = gym.make("Pendulum-v0")
device = torch.device("cuda:1"if torch.cuda.is_available() else "cpu")
# Params
tau = 0.01
gamma = 0.99
q_lr = 3e-3
value_lr = 3e-3
policy_lr = 3e-3
buffer_maxlen = 50000
Episode = 100
batch_size = 128
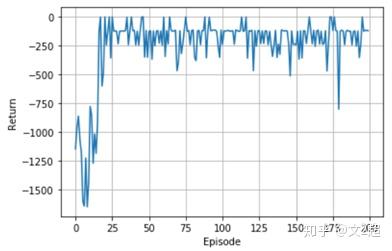
- 结果
四、SAC改进(第二版论文):
- 使用双Q网络减少Q值过度估计(代码中以实现)。
- 去除了V网络,简化训练。
- 在这片文章中我们默认了a temperature为固定常数,但实际上由于reward的不断变化,采用固定的a并不合理,当策略探索到新的环境空间时候,我们并不知道最优动作,应该调大a ,从而去探索更多的空间。当某一个区域已经探索得差不多,最优的策略基本确定了,那么这个a就可以减小。所以在第二版论文中,a参数为一个自适应调整的过程,而不是一个固定的值,下次再慢慢推导。
参考
- ^https://arxiv.org/abs/1801.01290
- ^https://wanghuaishi.wordpress.com/2017/02/21/%E5%9B%BE%E8%A7%A3%E6%9C%80%E5%A4%A7%E7%86%B5%E5%8E%9F%E7%90%86%EF%BC%88the-maximum-entropy-principle%EF%BC%89/
- ^https://arxiv.org/abs/1812.05905
- ^https://www.jianshu.com/p/9d5a0698f982
- ^https://github.com/Wen2chao/RL-Algorithm/tree/master/SAC2018
- ^https://zhuanlan.zhihu.com/p/75937178

