
如何使用drop_duplicates进行简单去重(入门篇)

什么是去重呢?
简单来说,数据去重指的是删除重复数据。在一个数字文件集合中,找出重复的数据并将其删除,只保存唯一的数据单元。在我们的数据预处理过程中,这是一项我们经常需要进行的操作。
去重有哪些好处?
- 节省存储空间
- 提升写入性能
- 提高模型精度
今天我们就来简单介绍一下,在pandas中如何使用drop_duplicates进行去重。
一、函数体及主要参数
函数体:
df.drop_duplicates(subset=['A','B'],keep='first',inplace=True)主要参数:
subset: 输入要进行去重的列名,默认为None
keep: 可选参数有三个:‘first’、 ‘last’、 False, 默认值 ‘first’。其中,
- first表示: 保留第一次出现的重复行,删除后面的重复行。
- last表示: 删除重复项,保留最后一次出现。
- False表示: 删除所有重复项。
inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。
(inplace参数在很多时候都需要用到,是一个十分常见的参数,忘记的同学可以看下面)
二、实例操作
首先还是一样,建立一个我们实验用的数据表:
import numpy as np
import pandas as pd
df = pd.DataFrame({'Country':[1,1,2,12,34,23,45,34,23,12,2,3,4,1],
'Income':[1,1,2,10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000,3000,15666,1],
'Age':[1,1,2,50, 43, 34, 40, 25, 25, 45, 32,12,32,1],
'group':[1,1,2,'a','b','s','d','f','g','h','a','d','a',1]})
df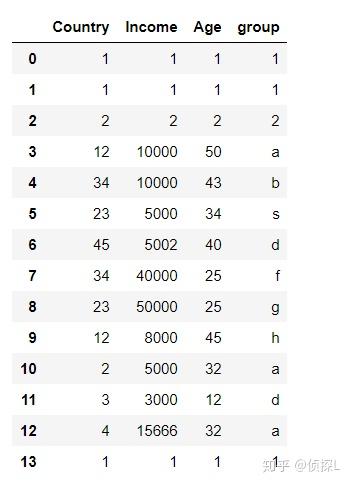
df.shape
可以看到,这是一个14行4列的数据表,其中,第0,1以及13行的数据是完全一样的。
下面开始我们的实验。
1、对整个数据表进行去重处理
df.drop_duplicates(inplace=True)
df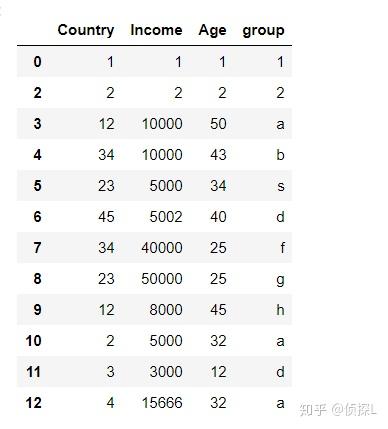
可以看到,数据表默认使用‘first’参数 保留了第一次出现的重复行,因此,第1行和第13行数据被删除了。
注意了~
大家看数据表中的索引,在我们使用drop_duplicates删除重复行时,重复行相对应的索引值也是被默认删除掉的,也就是说,索引值已经发生了变化。
那我们该如何解决这个问题呢?
答案是要将索引重置,这样后面再次使用才不会因为索引不存在而报错。
重置索引的方法是:reset_index
reset_index,默认(drop = False),当我们指定(drop = True)时,则不会保留原来的index,会直接使用重置后的索引。
我们来实验一下:
df.reset_index(drop=True)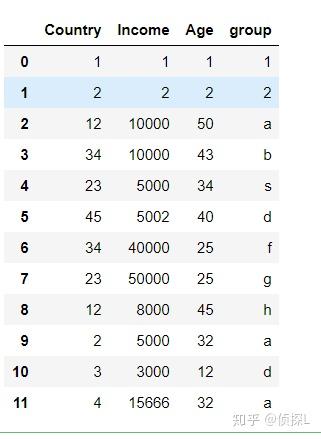
成功~ 索引恢复了。
补充完上面的解释,我们接下去介绍drop_duplicates的其他用法。
2、对指定的数据列进行去重:
(由于在上面我们对整个数据表进行去重的时候使用了 inplace=True 对原表进行修改,为了更好地展示实验成果,同时避免冲突,我在这里重新导入了一次数据)
import numpy as np
import pandas as pd
df = pd.DataFrame({'Country':[1,1,2,12,34,23,45,34,23,12,2,3,4,1],
'Income':[1,1,2,10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000,3000,15666,1],
'Age':[1,1,2,50, 43, 34, 40, 25, 25, 45, 32,12,32,1],
'group':[1,1,2,'a','b','s','d','a','b','s','a','d','a',1]})
df
3、下面,我们对'Age’列进行去重,同时使用‘last’参数:
df.drop_duplicates(subset=['Age'],keep='last')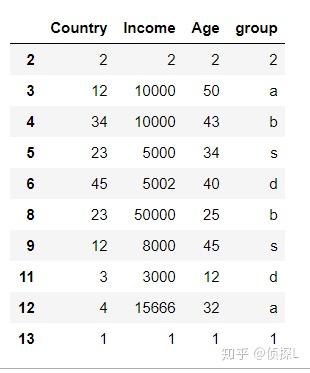
4、再尝试对'group'列进行去重,同时使用‘last’参数:
df.drop_duplicates(subset=['group'],keep='last')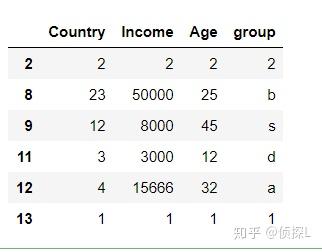
5、同时对'Age’列和'group'列进行去重:
df.drop_duplicates(subset=['Age','group'],keep='last')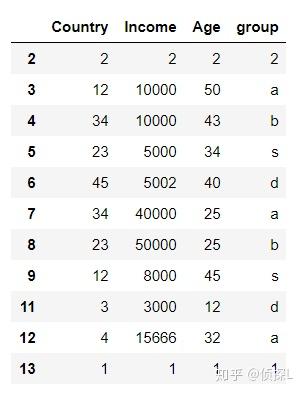
从步骤3-5,大家可以体验到,同时对数据表中多个列进行去重操作,判定标准是怎么样的。
6、体验keep=False的用法:
df.drop_duplicates(keep=False)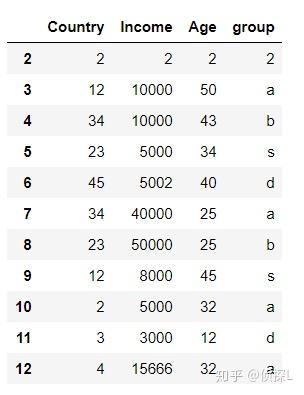
可以看到,所有重复的数据都被删除了。
然而,这种用法L个人不是很提倡。当然了,各种用法仍需结合实际进行使用。
以上便是<如何使用drop_duplicates进行简单去重(入门篇)>的内容,感谢大家的细心阅读,同时欢迎感兴趣的小伙伴一起讨论、学习,想要了解更多内容的可以看我的其他文章,同时可以持续关注我的动态~

