
《边界值分析》-有这篇就够了

目录:
- 定义(What)
- 为什么使用该方法?(Why)
- 如何选定边界值?(How)
- 设计测试用例
- 根据测试用例的完整性划分
- 边界的分类
- 使用场景
- 实战演练
- 边界值分析的优缺点
- 特殊值测试
- 边界值分析和等价类划分的联系
- 常见的产生边界值bug的原因
- 边界值法应用时,如果测试时间紧张,应该优先测试哪些点?
1.定义(What?)
边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法,通常作为对等价类划分法的补充,其测试用例来自等价类的边界。
所谓边界值,是指相对于输入等价类和输出等价类而言,稍高于边界或稍低于边界的一些特定情况。
2.为什么使用该方法?(Why)
- 等价类划分忽略掉了某些特定类型的高效测试用例,而边界值分析可以弥补其中的很多不足;
- 根据大量的测试统计数据,编程的很多错误是发生在输入定义域或输出值域的边界上,而不是发生在输入/输出范围的中间区域。因此针对输入和输出等价类的边界情况设计测试用例,可以查出更多的错误,具有更高的测试回报率;
- 边界值数据本质上是属于某个等价类的范围,测试时确实是一种冗余(重复),但是为了更好的测试质量(边界值特别容易出bug),边界值必须要单独测,适当的冗余是可以接受的。
3.如何选定边界值?(How)
很难提供一份如何进行边界值分析的“详细说明”,因为这种方法需要一定程度的创造性,以及对问题采取一定程度的特殊处理办法。
但是可以提供一些通用指南:
- 如果输入条件规定了一个输入值范围,那么应针对范围的边界设计测试用例,针对刚刚越界的情况设计无效输入测试用例。举例,如果输入值的有效范围是-1.0至+1.0,那么应针对-1.0、1.0、-1.001和1.001的情况设计测试用例。
- 如果输入条件规定了输入值的数量,那么应针对最小数量输入值、最大数量输入值,以及比最小数量少一个、比最大数量多一个的情况设计测试用例。举例,如果某个输入文件可容纳1~255条记录,那么应根据0、1、256和255条记录的情况设计测试用例。
- 对每个输出条件应用指南1。举例,如果某个程序按月计算FICA的扣除额,且最小金额是0,最大金额是1165.25,那么应该设计测试用例来测试扣除0和1165.25的情况。此外,还应观察是否可能设计出导致扣除金额为负数或超过1165.25的测试用例。
- (Tips:检查结果空间的边界很重要,因为输入范围的边界并不总是能代表输出范围的边界情况(例如三角正弦函数sin)。但是总是产生超过输出范围的结果也是不大可能的,但无论如何,应该考虑这种可能性。)
- 对每个输出条件应用指南2。如果某个信息检索系统根据输入请求显示关联程度最高的信息摘要,而摘要的数量从未超过4条,则应编写测试用例,使程序显示0条、1条和4条摘要,还应设计测试用例,导致程序错误地显示5条摘要。
- 如果程序的输入或输出是一个有序序列(例如顺序的文件、线性列表或表格),则应特别注意该序列的第一个和最后一个元素。
- 如果程序中使用了一个内部数据结构,则应当选择这个内部数据结构的边界上的值作为测试用例。
- 此外,发挥聪明才智找出其他的边界条件。
Tips:边界值分析方法和等价类划分之间的重要区别是,边界值分析考察正处于等价划分边界或在边界附近的状态。
4. 设计测试用例
A.确定边界值
在尝试针对划分好的等价类进行边界值取值的时候,一定要有适当的范围,不是根据我们的端点值往左右两侧随意选择测试值,而是也有科学的方法进行选择。
边界值点的定义:
上点:边界上的点,闭内开外(“闭”是指域的边界是封闭的,即闭区间;“开”是指域的边界是开放的,即开区间)。
离点:离上点最近的点称为离点。开内闭外。
内点:域范围内的任意一点。
三点分析法:结合等价类划分的具体情况,针对边界值的选择就包括开区间、闭区间以及半开半闭区间。
- 闭区间:闭区间中的情况,上点为可以取值的点,在上点之间任取一点就是内点。而紧邻上点范围之外的第一对点被称为离点(也称为外点)
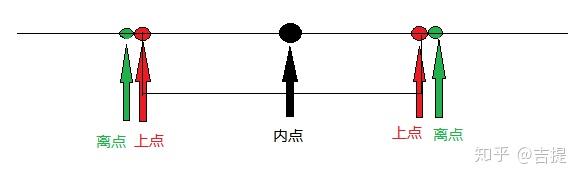
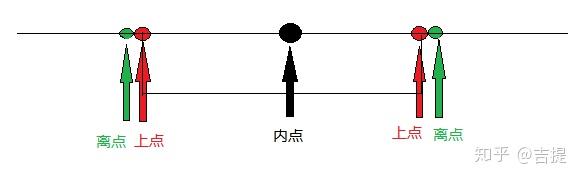
- 半开半闭区间:半开半闭区间中,上点与内点的定义不变。离点是开区间一侧上点内部范围内紧邻的点,而在闭区间一侧是上点外部范围内紧邻的点。
- 开区间:开区间中,上点与内点的定义仍然不变。而离点就是上点内部范围内紧邻的一对点。
总结为,上点就是区间的端点值,而内点就是上点之间任意一点。对于离点,要分具体情况,如果开区间的离点,就是开区间中上点内侧紧邻的点;如果是闭区间的离点,就是闭区间中上点外侧紧邻的点。
PS.小数类型,等价类+边界值测试时的注意事项:
有效等价类:除了有效的小数外,有效的整数也需要测(小数中默认包含了整数,除非需求中明确的说:小数中不包含整数)
无效等价类:小数类型—非小数(非数):字母、汉字、特殊字符;小数位数—超出小数的有效位数(例如:最多两位,那么>2位就是无效等价类)
边界值:小数的次边界与边界之间的相差单位是与精确度相关的,例如:精确到小数点后2位,那么相差单位就是0.01。例如:最小值是:1.00那么次边界就是 0.99 和1.01;要考虑小数位数的边界问题。例如:小数位数最大值:小数点后2位
那么次边界是:小数点后1位和小数点后3位B.设计测试用例(详见“实战演练”)
5. 根据测试用例的完整性划分
单缺陷假设与多缺陷假设:
单缺陷假设是边界值分析的关键假设。单缺陷假设指“失效极少是由两个或两个以上的缺陷同时发生引起的”。在边界值分析中,单缺陷假设即选取测试用例时仅仅使得一个变量取极值,其他变量均取正常值。
多缺陷假设则是指“失效是由两个或两个以上缺陷同时作用引起的”,要求在选取测试用例时同时让多个变量取极值。
几种边界值分析法模型:一般性边界值测试、健壮性测试、最坏情况测试、健壮性最坏情况测试。
- 一般性边界值测试
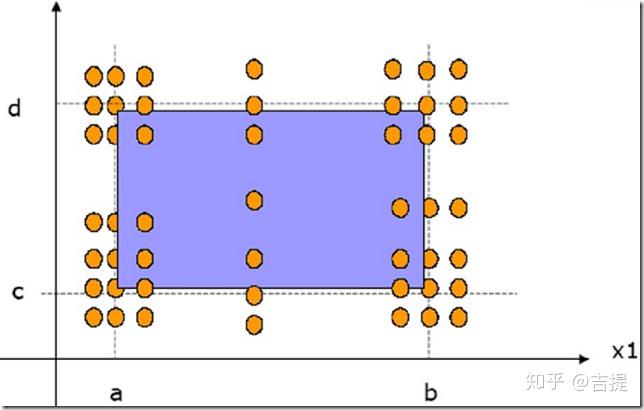
有n个输入变量,设计测试用例使得一个变量在数据有效区域内取最大值、略小于最大值、正常值、略大于最小值和最小值。如下图所示,两个变量X1,X2。它们的有效取值区间分别为[a,b]、[c,d]。
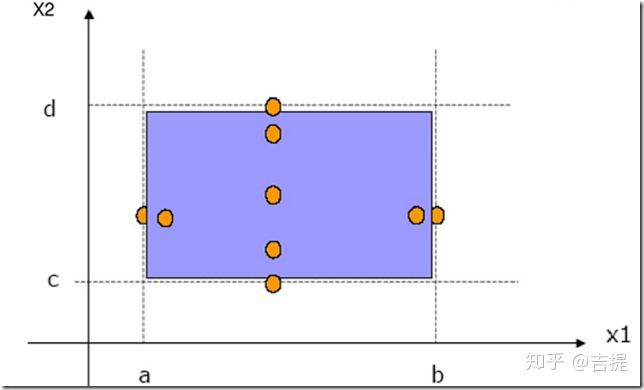

对于有n个输入变量的程序,一般性边界值分析的测试用例个数为4n+1。
边界值测试分析采用了可靠性理论的单缺陷假设。
- 优点:简便易行;生成测试数据的成本很低;
- 局限性:测试用例不充分;不能发现测试变量之间的依赖关系;
- 结论:只能作为初步测试用例使用。
- 健壮性测试
健壮性是指在异常情况下,软件还能正常运行的能力。健壮性考虑的主要部分是预期输出,而不是输入。健壮性测试是边界值分析的一种简单扩展。除了变量的5 个边界分析取值还要考虑略超过最大值(max)和略小于最小值(min)时的情况。健壮性测试的最大价值在于观察处理异常情况,它是检测软件系统容错性的重要手段。如下图所示。
PS:软件容错性的度量:从非法输入中恢复;健壮性有两层含义:容错能力和恢复能力


对于有n个输入变量的程序,健壮性测试的测试用例个数为6n+1。
- 最坏情况测试
最坏情况测试拒绝单缺陷假设,它关心的是当多个变量取极值时出现的情况。最坏情况测试中,对每一个输入变量首先进行包含最小值、略高于最小值、正常值、略低于最大值、最大值等5个元素集合的测试,然后对这些集合进行笛卡尔积计算,以生成测试用例。最坏情况测试将意味着更大工作量。如下图所示。
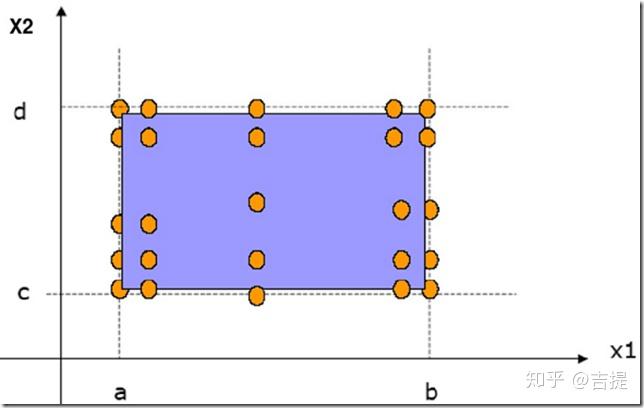

对于有n个输入变量的程序,最坏情况测试的测试用例个数为5^n。
最坏情况与基本边界值分析的比较:
- 基本边界值分析测试用例是最坏情况测试用例的真子集;
- 最坏情况测试显然更彻底;
- 最坏情况测试工作量大得多,变量函数的最坏情况测试会产生5的n次方个测试用例,边界值分析只产生4n+1个测试用例。
- 健壮性最坏情况测试
健壮性最坏情况假设对每一个变量首先进行最小值、略小于最小值的值、略高于最小值的值、正常值、最大值、略高于最大值的值、略低于最大值的值等7个元素的集合。然后对这些集合进行笛卡尔积运算,以生成测试用例。如下图所示。

对于有n个输入变量的程序,健壮最坏情况测试的测试用例个数为7^n。
6.边界的分类
- 边界条件:可以在产品说明书中有定义或者在使用软件过程中确定;
- 内部边界条件:在软件内部,也称为内部边界条件;
- 其他边界条件:如输入信息为空、非法、错误、不正确和垃圾数据。
A.边界条件的常见数据类型
数值、速度、字符、地址、位置、尺寸、数量、空间
- 例如,“字符”,边界值是起始-1字符、结束+1个字符。测试用例的设计思路是,假设一个文本输入区域允许输入1个到255个 字符,输入1个和255个字符作为有效边界值;输入0个和256个字符作为无效边界值,这几个数值都属于边界条件值。
- 例如“数值”,边界值是最小值-1、最大值+1。测试用例的设计思路是,假设某软件的数据输入域要求输入5位的数据值,可以使用10000作为最小值、99999作为最大值;然后使用刚好小于5位和大于5位的数值来作为边界条件。
- 例如“空间”,边界值是小于空余空间一点、大于满空间一点。测试用例的设计思路是,例如在用U盘存储数据时,使用比剩余磁盘空间大一点(几KB)的文件作为边界条件。
B.内部边界条件
在多数情况下,边界值条件是基于应用程序的功能设计而需要考虑的因素,可以从软件的规格说明或常识中得到,也是最终用户可以很容易发现问题的。然而,在测试用例设计过程中,某些边界值条件是不需要呈现给用户的,或者说用户是很难注意到的,但同时确实属于检验范畴内的边界条件,称为内部边界值条件或子边界值条件。
内部边界值条件主要有下面几种:
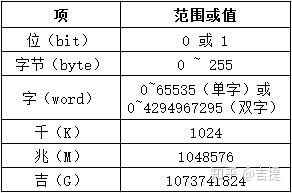
- 数值的边界值检验:计算机是基于二进制进行工作的,因此,软件的任何数值运算都有一定的范围限制。
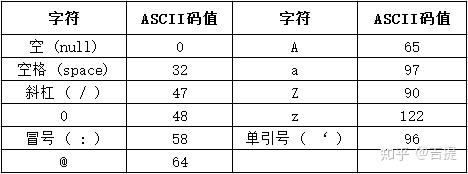
- 符的边界值检验:在计算机软件中,字符也是很重要的表示元素,其中ASCII和Unicode是常见的编码方式。如下列出了一些常用字符对应的ASCII码值。

- 其它边界值检验:在不同的行业应用领域,依据硬件和软件的标准不同而具有各自特定的边界值。如下列出部分手机相关的边界值

7.使用场景
有数据输入且存在取值边界或长度边界时,一般可以使用边界值法。边界值法往往跟等价类划分法一起使用,从而形成一套较为完善的测试方案。
8. 实战演练
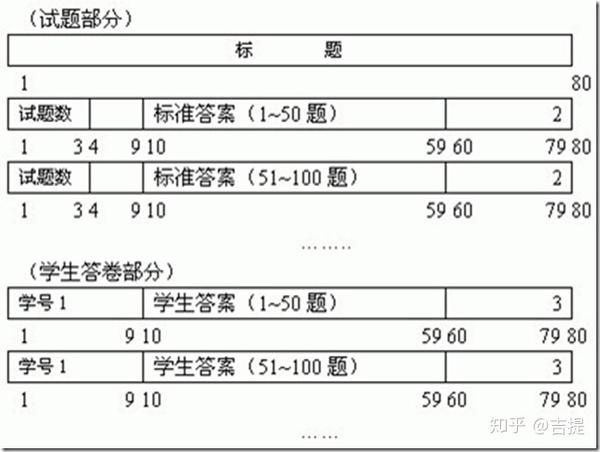
例1. MTEST是一个多项选择考试的评分程序。程序的输入是一个名为OCR的数据文件,包含多个长度为80个字符的记录。按照文件的格式要求,第一个记录的内容是标题,作为每份输出报告的标题。后面的一组记录的首条记录中,第1~3列存储的是试题的数量(一个1~999的数),第10~第59列存储的是第1~第50道试题的标准答案(任何字符都为有效答案),后续记录的第10第59列存储的是第51~第100道试题、第101~第150道试题的标准答案等。第三组记录描述的是每个学生的答案,这些记录的最后一个字母皆为“3”。对于每个学生来说,第一条记录的第1~第9列存储的是学生的名字或编号(任意字符),第10~第59列存储的是该学生对第1~第50道试题的答案。如果本次考试试题超过50个,该学生的后续记录的第10~第59列存储的是第51~第100、第101~第150道试题的答案等。学生的人数最多是200。输入数据如下图所示。四个输出报告分别是:
- 按学生的编号排序的报告,显示每名学生的成绩(正确答案的百分比)和名次。
- 按成绩排序的报告。
- 显示成绩的平均值、中间值和标准偏差的报告。
- 按问题的编号排序的报告,显示正确回答每个问题的学生比例。



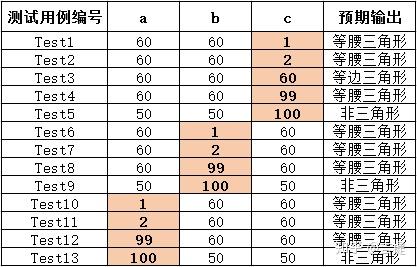
例2. 在三角形问题描述中,除了要求边长是整数外,没有给出其它的限制条件。在此,我们将三角形每边边长的取范围值设值为[1, 100] 。那么三角形问题的边界值分析测试用例如下:
- 一般性边界值测试
- 健壮性边界值测试
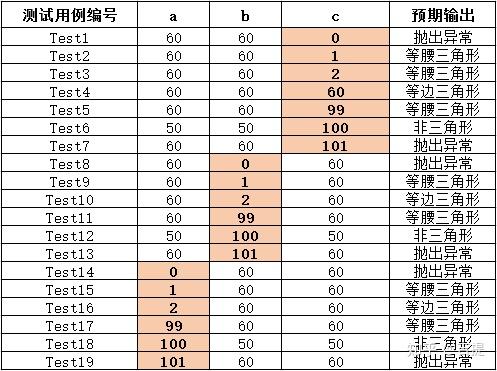

- 最坏边界值:5^3=125条测试用例
- 最坏健壮性边界值:7^3=343条测试用例
例3. 某程序具有如下功能:文本框要求输入日期信息,日期限定在1990年1月~2049年12月,并规定日期由6位数字字符组成,前4位表示年,后2位表示月;程序需对输入的日期有效性进行校验。用等价类划分方法和边界值分析法为该程序的“日期检查功能”设计测试用例。
A.划分等价类&选取边界值
步骤一、要求输入6个数字字符yyyynn;参照等价类划分法规则5,划分为一个有效等价类和三个无效等价类。
- 有效等价类(1):输入6个数字字符
- 无效等价类(2):输入6个字符,存在非数字的情况
- 采用边界值,6个字符全为非数字:abcdef
- 采用边界值,6个字符中有1个为非数字:19930m
- 无效等价类(3):输入少于6个数字字符
- 采用边界值,输入5个数字字符
- 无效等价类(4):输入多于6个数字字符
- 采用边界值,输入7个数字字符
步骤二、在有效等价类(1)的基础上,参照等价类划分法规则6,对该等价类进行细分;考察6个数是否满足日期格式要求,1990<=yyyy<=2049,01<=nn<=12,参照规则,划分为一个有效等价类和四个无效等价类。
- 有效等价类(5):日期格式满足要求,1990<=yyyy<=2049,01<=nn<=12
- 采用边界值,[yyyy,nn]取值为:[1990,06],[1991,06],[2020,06],[2048,06],[2049,06],[2020,01],[2020,02],[2020,11],[2020,12]
- 无效等价类(6):yyyy不满足要求,yyyy<1990
- 采用边界值,[yyyy,nn]取值为:[1989,06]
- 无效等价类(7):yyyy不满足要求,yyyy>2049
- 采用边界值,[yyyy,nn]取值为:[2050,06]
- 无效等价类(8):nn不满足要求,nn<01
- 采用边界值,[yyyy,nn]取值为:[2020,00]
- 无效等价类(9):nn不满足要求,nn>12
- 采用边界值,[yyyy,nn]取值为:[2020,13]
B.设计测试用例


例4. 假设商店货品价格(R)皆不大于100元(且为整数),若顾客付款在100元内(P),求找给顾客的最少货币个(张)数?(货币面值50元,10元,5元,1元四种)
题目分析:设四种货币的张数分别为n50、n10、n5、n1(均为整数)它们的值即为结果。
- 输入情况有R>100, 0<R<=100, 0<R, P>100, R<=P<=100, P<R。
- 输出情况有n50=1||0, 0<= n10 <5, n5=1||0, 0<= n1 <5。
- 测试实例(R,P)有:

本例采用的是最坏情况测试,因为两个变量中P变量的边界是随着R变化而变化的,因此在测试中先确定R的取值,然后在此基础上对P的取值进行分析。由于采用最坏情况测试,出现了比较多的非法输入。其实这些非法输入可以根据R的值分成三个等价类非别是R>100, 0<R<=100, R<=0,在此为了展示所有情况,所以列出了所有可能的操作。
9.边界值分析的优缺点
- 优点:更全面更系统的测试边界上存在的问题,是最有效的测试用例设计方法之一;
- 缺点:只能作为一个对其他设计方法的补充;这种方法表面上听起来简单,但有的边界值非常微妙,不容易确定下来;只适用于多个变量相互独立又都代表实际物理量的情况,对变量之间的依赖关系则考虑不到。
10.特殊值测试
特殊值测试的基本思想,边界值分析假定n个变量是互相独立的,没有考虑这些变量之间的互相依赖关系;特殊值测试使用领域知识、使用类似程序的经验来确认用例的特殊值。
- 特点:最直观、最不一致、具有高度主观性;
- 特殊值测试特别依赖测试人员的能力;
- 虽然特殊值测试是高度主观性,但是能更有效地发现问题。例如:2月28日、2月29日
11.边界值分析和等价类划分的联系
- 一个属于确认有有效和无效区间,一个属于确认边界,联系就是等价类划分和边界值要一起考虑,边界值分析法属于等价类划分法的补充,任何等价区间都有边界,有边界就有等价区间;
- 与从等价类中挑选出任意一个元素作为代表不同,边界值分析需要选择一个或多个元素,以便等价类的每个边界都经过一次测试
12. 常见的产生边界值bug的原因
- 疏忽开区间闭区间
- 疏忽循环变量的初始值(0,1的区别)
- 数组越界等等。
13. 边界值法应用时,如果测试时间紧张,应该优先测试哪些点?
优先测试最大值和最小值
