![[质疑][CVPR2019][A Late Fusion... Matting]](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[质疑][CVPR2019][A Late Fusion... Matting]

本文作者:信息门下跑狗
全文分为三个部分:
- 图像抠图的过去与现在
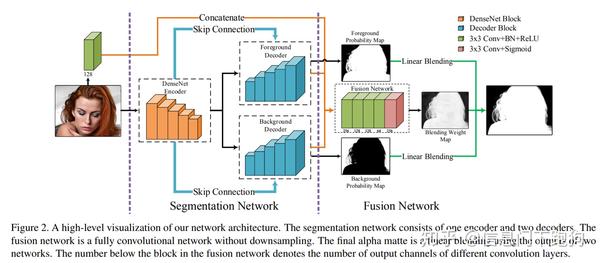
- 疑点重重的全自动抠图鼻祖:CVPR 2019 - A Late Fusion CNN for Digital Matting(LFM)—— 疑似将test set也放进train set
- 质疑总结与彩蛋



(1) 图像抠图的过去与现在
图像抠图(Image Matting)是一个无论在工业界抑或视觉研究领域都有非常重要价值的研究课题。从2000年开始,在进行图像抠图及相近研究问题的研究过程中,诞生了类似GrabCut、Guided Filter、Closed Form Matting、Poisson Matting、Bayesian Matting等等对各计算机视觉以及计算机图形学研究都有深远影响的工作。在好莱坞的动作大片、迪士尼的动画巨作、Office以及Adobe PhotoShop的一些功能中都能够看到抠图算法的身影。
求解抠图问题需要我们对一张图像,分别求解出它的前景、背景以及alpha matte。alpha matte是我们常说的alpha通道,基于alpha 通道我们可以将前景和任意背景进行重新组合得到新的图像。因此alpha matte是和原图同大小的一个单通道图像,每个像素都对应于原RGB图像相同位置像素的alpha值。根据基本假设,对于一张RGB 图像,每个像素在R、G、B这三个通道上的强度(intensity)是由前景以及背景的凸组合构成的,即
I_{i}^{j} = \alpha_{i} \cdot F_{i}^{j} + (1 - \alpha_{i}) \cdot B_{i}^{j} ,
这里 I 代指Image, F_{i}^{j} 代表第 i 个像素下第 j 个通道的前景像素强度(pixel intensity), B_{i}^{j} 代表第 i 个像素下第 j 个通道的背景像素强度(pixel intensity)。对于一张图片而言,由于我们只知道它的R、G、B三个通道的像素强度,因此对于每一个像素而言,我们有三个方程分别对应RGB三个通道,同时我们需要求解 \alpha_{i} , F_{i}^{j} 以及 B_{i}^{j} 一共7个未知数。三个方程七个未知数,这是妥妥的未知数个数大于方程个数,解可以有无穷多个,属于经典的视觉研究中的反问题,难度非常的大。
为了能够降低求解的难度,过去到现在绝大部分的方法都是基于人工手动标注的三元图(trimap)来提供更多的约束。三元图顾名思义就是将一副图像分成三个部分,分别是绝对前景(absolute foreground),绝对背景(absolute background)以及未知区域(unknown area)。基于三元图,我们只需要将未知区域的像素对应的alpha值进行求解就可以了。从2017年 CVPR Oral Deep Image Matting 以来,含有trimap作为网络输入的深度学习方法在http://alphamatting.com (image matting的一个benchmark网站)疯狂打破记录,可以说深度学习对含有trimap进行matting问题求解是有非常大的帮助的。同时Deep Image Matting文章还提出了一个dataset,叫做Adobe Deep Image Matting Dataset,这个dataset它含有431张前景及前景对应的ground-truth alpha matte作为train set,以及40张前景及前景对应的ground-truth alpha matte作为test set。论文里首次提出可以考虑在训练的时候对同一张前景与不同的背景进行合并得到composition image,然后扔进去网络进行训练。而背景池就是从MSCOCO里面进行采样。这样就可以构造一个非常大的train set进行训练。这样的操作也从2017年延续至今。下图的第二列就是trimap的示意图,我们可以看到灰色的部分就是所谓的unknown区域,也就是我们实际上要求解出alpha matte的区域。这个截图来自最近比较火的CVPR 2020 Background Matting:The World is Your Green Screen的 Figure 6,这篇文章下面我也会提及:)


(2)疑点重重的全自动抠图鼻祖:CVPR 2019 - A Late Fusion CNN for Digital Matting(LFM)
然而如果不考虑trimap而直接对一张图片进行抠图,那么就是以hard 模式去求解抠图问题了。而最近一两年在视觉顶会CVPR中就有一些这样的论文在进行探索。
A Late Fusion CNN for Digital Matting(LFM)这篇文章是我看到的首篇在顶会(CVPR2019)上发表的号称给定任意输入的RGB自然图像都能完成自动抠图。这样的claim(声称)一旦是真的,那么将是matting领域近年来最好的工作,没有之一。之前所有的将trimap作为网络输入之一的方法将全部GG(因为不再需要了)。这篇文章的作者来自于浙江大学 CAD & CG国家重点实验室,同时也有阿里巴巴的研究员以及来自University of Texas at Austin的研究员参与了这项研究。并且我也在方法对比中看到了与阿里巴巴在2018 ACM MM发表的Semantic Human Matting(SHM)方法的对比,意味着作者应该是拿到了SHM的pretrain model,毕竟作为企业内部的研究一般是不会放出pretrain model以及数据集的。高校+知名企业的研究团队,对于matting这个既有科学研究价值又具备商业落地可能的研究课题,在我看来应该是最佳的设定。
带着好奇,我开始研究了一下这篇文章。
面对号称能对自然图像自动化抠图这样的claim,通过简单的推理,首先就有一个简单的疑问,如果图A里面有个女人,LFM能成功抠出来;现在有个图B有个马,LFM又能成功抠出来。那么我用图B作为背景图和图A做合成图,那么扣的是女人还是马?或者直接拿一个有一个女人和马的图片,那么会输出什么?没有任何的指定,怎么知道要抠什么?这是在做显著性检测吗?由于官方github中并没有放出任何代码(截止至2020.04.08),所以不得而知了。

带着很多小问号,我尝试发了邮件给作者,然而并没有回。那么只能自己复现,讲真,网络结构并不是很复杂,甚至有些平平无奇。Ok,那就实现吧,然后结果就出来了。
首先要提到的是在LFM的实验中,作者采用了上文中提到的2017 CVPR Oral Deep Image Matting提供的Adobe Deep Image Matting Dataset数据集 进行训练并且基于这个数据集的测试集进行测试,来佐证LFM能够在任意RGB图像上都能够进行抠图
(原文表述: (2) Composition-1k testing dataset in [39], which is to evaluate how our network performs on natural images.)
此外LFM作者还建立一个前景全是人的train set进行学习,然后在全是人作为前景的一个test set进行测试 ,
(原文表述:(1) Human image matting testing dataset, which is to measure the performance of our method on a specific task.)
作者在4. Experimental Results 的 Evaluation on human image matting testing dataset中声称(claim):
Note that our network works well for various poses and scales of the human in the foreground. For instance, the woman viewed from the back (second row in Fig. 5) is difficult for the deep automatic portrait matting.
也就是说LFM能够很好地应对具有不同姿态以及比例大小的人作为前景时候的抠图。综上所述,通过文章的实验结果是可以对LFM能够具备对任意RGB图像都能进行抠图的claim进行有力佐证的。目前来看文章的实验设计逻辑还是很严谨的。那么这里也是为了严谨,我选择了LFM作者在论文的Figure 9中提供的Internet image matting results作为我的测试对象,因为internet images都是不包含alpha matte ground-truth的。通过以图搜图功能我顺利找到了三张Internet image的其中一张,链接在这里。


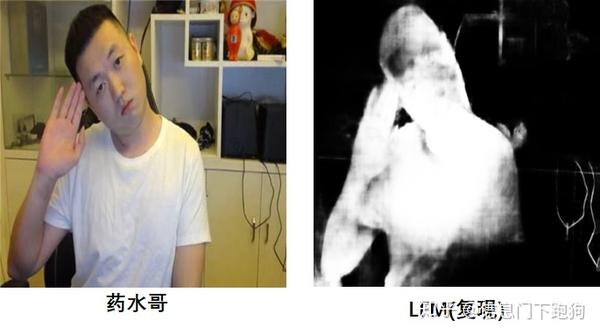

上图就是我复现得到的结果。只能说我真的尽力了,通过疯狂的调参上图是能cherry-pick的最好结果了。为什么LFM论文report的结果丝般顺滑,就像segmentation一样(哭了)。当然或许是因为我的复现存在一些tricky的问题(没办法,作者没开源,都一年过去了,你专利还没申请好吗?),那么既然我自己的复现不行,那么有没有第三方的依据来说明LFM可能是存在瑕疵的呢?
鉴于最近 CVPR 2020 放榜以及ECCV 2020 投稿结束,在arxiv上我发现几篇有提到LFM作为对比的matting文章,看来别人还是可以要到代码和pretrain的,估计是我运气太差了:)然而再深入一看这几篇投稿以及被CVPR 2020 accepted的新的paper,让我产生了进一步怀疑。首先我们来看最近被各大AI公众号在疯狂安利的CVPR 2020 论文Background-Matting。
CVPR 2020 的Background Matting:The World is Your Green Screen是另一篇“自动化”抠图的文章,这篇文章考虑让用户对需要抠图的图片多拍摄一幅背景图片的方式作为“绿幕”,而后基于背景图片提供的各种类型的信息构造全“自动化”的神经网络模型。通过这样的方式,就能够摆脱trimap,就能够实现全“自动化”抠图了。对于视频,可以通过分割视频后每一帧的前后几帧重构得到背景。
文章中Figure 6给出了含trimap作为输入的SOTA方法以及不含trimap的全“自动化”抠图的SOTA,即LFM以及该论文自身的结果对比:


以防大家看不清,我进一步截图了一下:






从(a)(c)的结果来看,有很大一部分的背景也被涵盖到了最后的alpha matte 预测结果中,譬如LFM的(a)图右下角出现了椅子,(c)图的右下角也出现了椅子,右上角出现了部分墙壁。这看起来与我复现的效果来看非常一致。
然而进一步阅读论文,我发现一个非常惊人的地方,作者们在论文正文的4.1. Results on Synthetic-Composite Adobe Dataset (这里Adobe Dataset 就是 CVPR 2017 Oral Deep Image Matting所提供的dataset,也是我上文复现用到的数据集) 相当明确地写道:
We omitted LFM from this comparison, as the released model was trained on all of the Adobe data, including the test data used here (confirmed by the authors).
意思是LFM放出的pretrain是将Adobe Deep Image Matting的train/test都放进去进行训练以后得到的pretrain model!这让人相当匪夷所思,即使是机器学习小白都应该明白一个道理,train set 和 test set应该分开,并且在报告结果的时候应该只报告train set上训练得到的model在test set上的表现。因此我们都会默认说如果作者放出结果,那么就应该放出只在train set上训练的结果。然而没想到LFM给那些能够要到pretrain model+代码+数据集的幸运儿们的居然是train+test一起训练的pretrain model,不知道这些幸运儿是否知道这些信息并且在基于这个pretrain model报告对比结果的时候是否有声明清楚。
我接着阅读CVPR 2020 Background Matting直到附录,在C.3 Results on Real Data中发现了作者们对于LFM涵盖很多背景的问题作出了更加详尽的叙述:
LFM was more problematic. We found that LFM would at times pull in pieces of
the background that were larger than the foreground person; the result of retaining the largest connected component would then mean losing the foreground subject altogether, an extremely objectionable artifact. Rather than continuing to refine the post-process for LFM, we simply did not apply a post-process for its results. As seen in the videos, LFM, in any case, had quite a few other artifacts that made it not competitive with the others.
能够在一篇文章中对于LFM进行如此多的叙述,看来LFM作为全自动化的SOTA在作者们的心目中也是有非常高的地位的,毕竟如果说不清的话很可能就会被reviewers 质疑吧:)
看完了CVPR 2020 Background Matting对于LFM的结果汇报,我开始寻找其他同样也要到LFM放出的pretrain model并且进行了结果汇报的论文,在arxiv上一搜,还真让我找到了两篇最近的文章。一篇是IEEE Transaction on Image Processing (TIP) 的投稿的preprint,这篇文章已经在http://alphamatting.com(一个大概在2009年提出的alpha matting benchmark 网站)提交过结果,巧合的是这篇文章也是叫做Background Matting:)难道说要make background matting great again?另一篇则是来自印度一家电商公司Fynd的论文AlphaNet: An Attention Guided Deep Network for Automatic Image Matting,看到题目提到了Automatic我猜这肯定要提LFM了,果然不出所料在论文中就用LFM进行了对比分析。下面我们就来进一步看看这两篇也拿到pretrain model报告的LFM的结果。
首先来看看同样也叫做Background Matting的这篇2020 TIP的投稿。这篇也叫做Background Matting的文章是一篇依赖trimap进行设计的文章,通过把background image也考虑进去作为input的一部分,这样构成了一个新型的网络input格式,即input image + trimap + background image。基于这样的方式这篇文章展开了一些探究。
在论文的Figure 2 以及Figure 3中分别都有基于LFM pretrain model的在Adobe Deep Image Matting Dataset的test set上的测试。要注意到这里的前景实际上带有一定透明度的,而在CVPR 2020 Background Matting:The World is Your Green Screen里面用到的测试图片的前景是非透明的(如人作为前景):


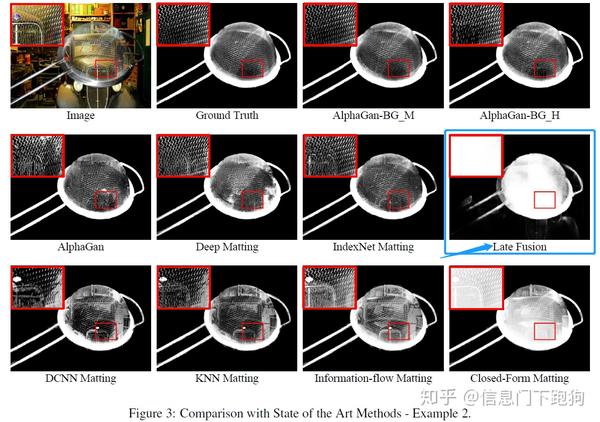
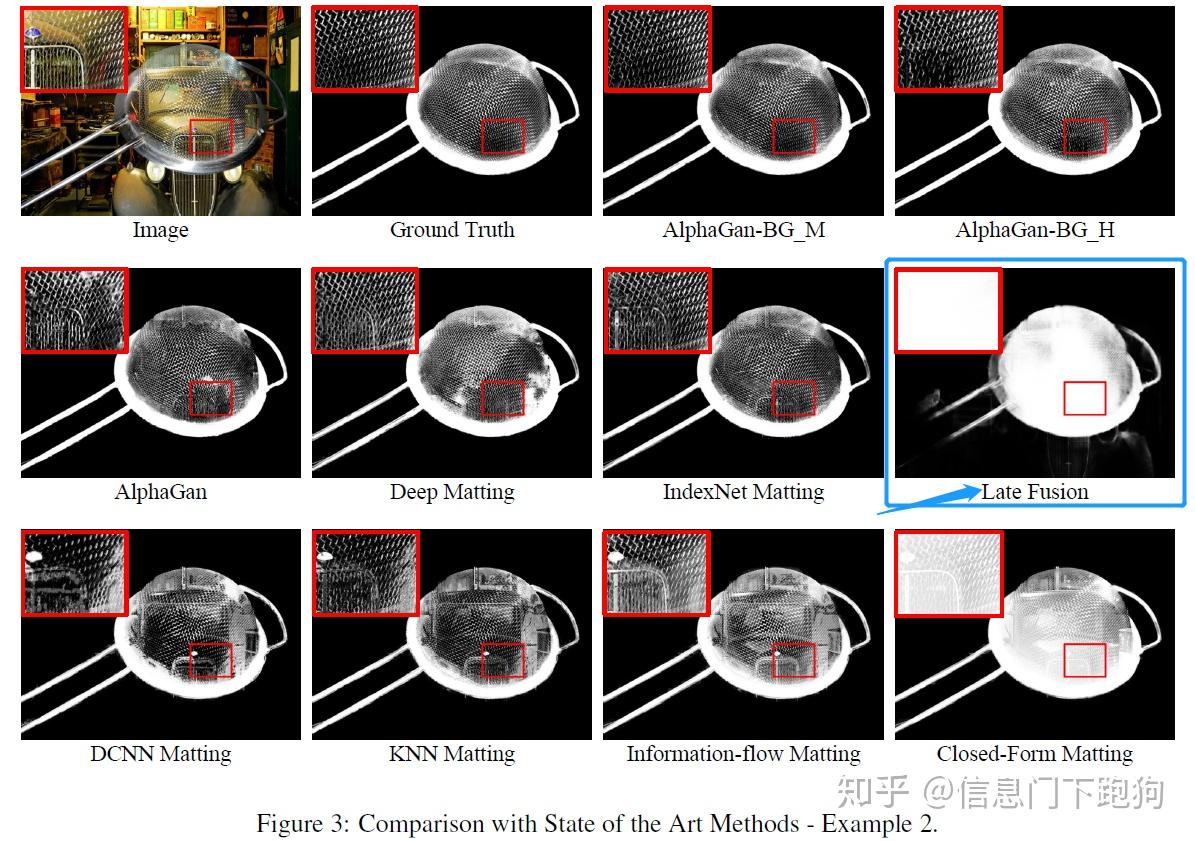
而恰好在LFM论文的Figure 6里面,也用到了与上面Figure 2一样的前景进行抠图。下图Figure 6 红色框框住的部分就是用相同前景合并了不同背景后LFM报告的结果。


当然了LFM和这篇TIP投稿的Background Matting论文用到进行合成的背景是不同的,但是进一步考虑到这篇TIP投稿的作者拿到的这个LFM pretrain model应该也是将test set包含进去的(不可能每个人都给不同的pretrain吧,如果是的话那就更诡异了:)),这样的话对于这个在test set中出现过前景,LFM的pretrain model也应该是已经训练过了,然而效果上依然不行呀:)
进一步地在这篇TIP 投稿的Table 1中我们可以看到,
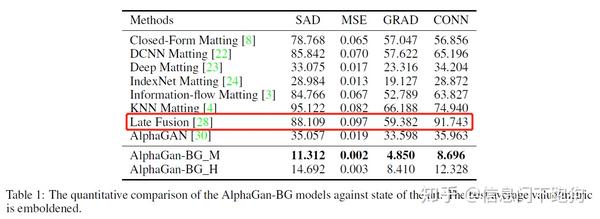

LFM的pretrain model在Adobe Deep Image Matting Dataset 上的表现远差于Deep Image Matting 的方法(SAD上差了55个点),甚至还比其他的不基于神经网络的closed-form matting以及Information-flow Matting的结果要差。但当我回看LFM在论文里报告的在Adobe Deep Image Matting Dataset的test set上的表现的时候:
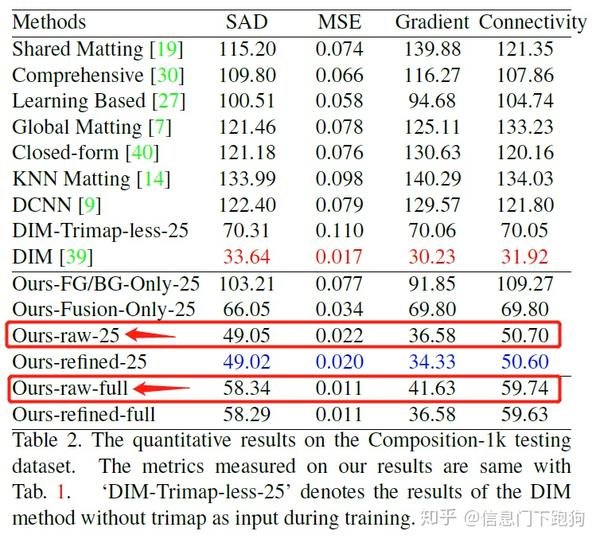

这里Ours-raw-full的意思是指LFM方法在没有经过guided filter进行后处理时对整张图算4个指标(SAD、MSE、Gradient、Connectivity)得到的结果。而Ours-raw-25是指仅仅在alpha matte的transition region进行dilation 25 pixels得到一个区域,计算这个区域下LFM对于alpha matte的预测与ground-truth alpha matte的差异得到四个指标的值。可以看到,从在LFM 报告的结果来看,无论是哪种计算方式都不会与DIM相差甚远,并且远远优于除DIM外的所有方法。这就非常尴尬了:)
单单看TIP这篇Background Matting报告的结果可能还是会怀疑会不会是TIP的这篇投稿在测试的时候出了问题,那么我们就来看看另一篇文章,来自印度友人的AlphaNet,同样是声称要进行自动化抠图。在该论文的Fig 4. 中也放出了LFM pretrain model在他们构建的dataset 上的结果。这里注意到论文提到了LFM的pretrain model是pre-trained on DIM (DIM就是Deep Image Matting的缩写,意味着在Deep Image Matting Dataset上进行pretrain),这下看来印度友人应该也是有询问过他们幸运地拿到的pretrain model是在什么数据集上面训练的,但很遗憾他们没有进一步问下去究竟是用train set还是test set还是一起用进行训练的: )


我们再次看到,三张放出来的图片在估计前景的时候都出现了大量的背景artifacts,与CVPR 2020 Background Matting在正文以及附录里面对于LFM的评价完全一致,也跟我的复现结果非常吻合:)
这三篇文章,CVPR 2020 Background Matting:The World is Your Green Screen, TIP投稿 Background Matting以及印度友人的AlphaNet分别通过Adobe Deep Image Matting Dataset的test set里面的透明物体作为前景以及非透明物体如人作为前景来测试了他们幸运拿到的LFM pretrain model,并且CVPR 2020 Background Matting拿到的pretrain model是在Adobe Deep Image Matting Dataset的train+test set一起训练后的model。应该说对于最开始LFM在摘要提到的对于RGB image可以自动化求解出alpha matte,我们可以从这两个不同类型的前景上LFM pretrain model的糟糕表现窥探到LFM的这个claim是否成立之一二:)
更多的测试只能留待大家向LFM的作者要到代码+pretrain model+dataset以后才能进一步好好玩耍了:)
(3) 质疑总结与彩蛋
下面就来到了总结归纳的时间了,基于这三篇不同的文章利用LFM作者提供的pretrain model我们可以得到以下的一些信息:
- LFM作者提供的pretrain model是在Adobe Deep Image Matting Dataset上进行训练的,并且基于CVPR 2020 Background Matting与作者确认的结果,是把train+test set一起放进去训练的。当然了为了保持严谨,我依然要说的是在非常小的概率情况下,有可能会发生LFM作者给不同的论文作者分别提供不同的pretrain model让他们进行复现。毕竟给不同作者提供不同的pretrain model这件事应该是小概率事件吧:)
- LFM作者提供的pretrain model的效果都与原论文上性能表现相去甚远,并且对于同一个前景图片在不同背景下的表现也是差别非常大。若除了CVPR 2020 Background Matting作者外其他作者拿到的pretrain model也是train+test进行训练的,那么只能说LFM即使将test set放进去训练,也无法做好自动化matting这个任务。对于LFM摘要提到可以直接输入一张RGB图像便能进行全自动化地进行matting,获得高质量的alpha matte,目前来看道阻且长:)
- LFM的论文中并没有留足够的位置去讨论可能存在的failure cases(在Figure 9的马那张图还是有提了一嘴),作为一个学术研究,尤其是计算机视觉以及图形学的研究,well-studied的问题往往都是很少的,因此对于能想得到的以及常见的failure cases都应该做更加详细的讨论,就算在正文没有了位置了也应该在附录予以讨论。然而我除了在Figure 9 Internet image的马的那张图看到了作者似有若无的讨论了一嘴关于这个“失败”的例子,在马嘴上出现了一些artifacts,除此以外我就没有看到过其他的讨论以及工作limitation的讨论。退一万步来说,如果放大去看马嘴的部分,其实也不是说完全是错误的:)
在这里,我保持着对LFM作者最大的敬意,因为无论如何,他也是(应该是)第一个考虑用CNN进行全自动化前景无差别抠图的第一人,并且能够发表在CVPR 2019。我非常希望如果作者本人看到了这篇知乎文章能够予以回应,向我们稍微阐述一下这些不解与困惑。我深知作为一名研究员,没有义务需要回答所有的质疑或者疑问。但当多篇文章分别都得到较为一致的结果的时候,作为这篇文章的作者,我觉得非常有责任要向整个community进行交代。
其次,我深知当前泡沫化下的AI研究领域让各大顶会充斥了大量无含金量的投稿。Reviewer都是义务劳动,在短时间内处理大量的投稿自然是非常困难的。然而现在让我们整个community看到的,是类似LFM这样的文章可以发在CVPR上。作为第一篇全自动化抠图的文章,并且能够发表在CVPR上,这注定了LFM会继续成为全自动化抠图这个领域未来好几年的benchmark以及比较对象。然而,对于那些在全自动化抠图这个领域耕耘的研究者来说,他们难道要每次投稿的时候,都要像我一样,像CVPR 2020 Background Matting一样,在正文以及附录都写了一次对于LFM的种种质疑和该如何将自己的方法和LFM进行合理的对比吗?这是一个领域顶会对整个领域该起到的作用吗?
Matting是一个无论在工业界抑或学术界都有非常高价值的研究课题,从2000年开始,大量的视觉研究员都曾经投身到Matting的研究中,像沈向阳、孙剑、何凯明、汤晓鸥、Jue Wang等等,更不乏在研究matting以及相近研究课题时候诞生出的类似GrabCut、Guided Filter、Closed-Form Matting等对其他视觉领域都有重要意义的工作。我真的不希望这个研究课题,从此可能会被乱搞下去。

对了,
在CVPR2020中有一篇同样claim了可以全自动抠图的文章
Attention-Guided Hierarchical Structure Aggregation for Image Matting
[https://github.com/wukaoliu/CVPR2020-HAttMatting],作者在知乎: @大工彭于晏
非常期待这篇文章/代码放出来。讲真,CVPR2020的camera ready过去很久了,应该可以先把论文放出来的吧?也诚邀各位大佬和大姥能一起来监督一下进展,要是有什么进展也可以艾特一下我,谢谢大家!
—————————倡议——————————
各位大佬和大姥:
如果在阅读论文或者代码的时候发现一些可能存在问题,且掌握一些证据,石锤,
欢迎将您的质疑投稿本专栏。
【如果不方便自己的号发出来,欢迎私信我,可以让我来代发,或者用小号来投稿,邮箱也可以联系runningdog_ai@126.com】
我一个人的实力实在是太弱了,质疑一篇文章所需要的时间和精力远不及有害论文的accept速度。随着全国人工智能学院的遍地开花和各种国家层面人工智能政策的颁布,亟需健康稳健干净的AI社区。
2020年2月-4月疫情阶段,我体会了从未有过的内忧外患,有没有想过自己能为祖国做点什么?中华民族伟大复兴不是,也绝不能是一句空话。在这个semi-和平时代,AI领域需要有突进者,也要有清道夫。我想我暂时应该有能力成为后者,希望我能继续坚持下去,作为即将可能要退役的我想做的一点微小的工作。也希望本专栏在大家的帮助下很快就再也再也发不出一篇质疑文章!
太阳快落下去了,你们的孩子居然不害怕?
“当然不害怕,她知道明天太阳还会升起来的。”——三体·黑暗森林
