调节学习率

在深度学习和其它一些循环迭代算法中,学习率都非常重要。在效率上,它几乎是与算力同等重要的因素;在效果上,它也决定着模型的准确率。如果设置太小,则收敛缓慢,也有可能收敛到局部最优解;设置太大又导致上下摆动,甚至无法收敛。
设定学习率
下面总结了设置学习率的一些方法:
- 理论上,如果将学习率调大10倍,现在10次训练就可以达成之前100次的训练效果。
- 一般使用工具默认的学习率,如果收敛太慢,比如训练了十几个小时,在训练集和验证集上仍在收敛,则可尝试将学习率加大几倍,不要一下调成太大。
- 如果误差波动过大,无法收敛,则可考虑减小学习率,以便微调模型。
- 在测试阶段建议使用较大的学习率,在短时间内测算过拟合位置,尤其好用。
- 在预训练模型的基础上fine-tune模型时,一般使用较小的学习率;反之,如果直接训练,则使用较大的学习率。
- 对于不同层可使用不同学习率,比如可对新添加的层使用较大的学习率,或者“冻住”某些层。
- 下图展示了不同学习率的误差变化曲线。
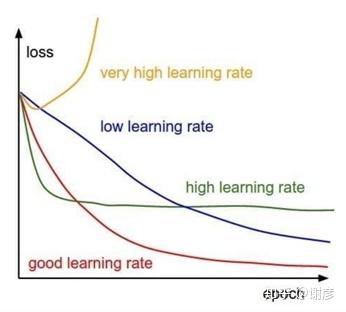
手动调节学习率
Pytorch提供在迭代过程中修改学习率的方法。最简单的方法是手动修改学习率的值。优化器optimizer通过param_group提供对不同层使用不同的优化方法,其中每组参数保存了各自的学习率、动量等,如果只设置了一种优化方法,修改其第0组的lr即可,例如设置学习率加倍: optimizer.param_groups[0]['lr'] *=2 在使用工具调整学习率的过程中,也可通过该值检测学习率的变化:
print(optimizer.state_dict()['param_groups'][0]['lr'])使用库函数调节
更为简便的方法是使用torch.optim.lr_scheduler工具,它支持三种调整方法:
- 有序调整
按一定规则调整,比如使用余弦退火(CosineAnnealing),指数衰减(Exponential),或者步长(Step)等事先定制的规则调整学习率。 - 自适应调整
通过监测某个指标的变化情况(loss、accuracy),当指标不再变好时,调整学习率 (ReduceLROnPlateau); - 自定义调整
使用自定义的lambda函数调整学习率(LambdaLR)
示例
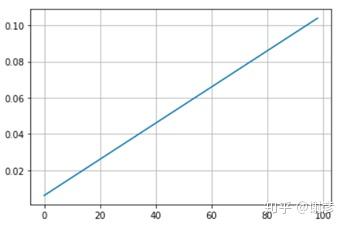
下面示例最简单的调整方法:每十次迭代,学习率减半
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
%matplotlib inline
# 构建一个简单的网络
class simpleNet(nn.Module):
def __init__(self, in_dim, n_hidden, out_dim):
super(simpleNet, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden)
self.layer2 = nn.Linear(n_hidden, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
return x
model = simpleNet(5, 10, 8)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 学习率初值0.1
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5) # 每十次迭代,学习率减半
arr = [] # 用于做图
for i in range(1,100):
scheduler.step() # 学习率迭代次数+1
arr.append(optimizer.state_dict()['param_groups'][0]['lr'])
#arr.append(scheduler.get_lr()) # 与上一句功能相同
plt.grid()
plt.plot(arr)其运行结果如下图所示:

其它常用方法:
多步长调整:在迭代到第10,30,50次时调整学习率,其它情况学习率不变。
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [10,30,50], gamma=0.5)
指数方式调整:每一次迭代,学习率呈指数方式变化lr=base_lr * (gamma**epoch)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
余弦退火:设置每T_max次迭代后衰减到eta_min设置的最小值,然后逐渐恢复其初值,后面依此类推,往复波动:
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, eta_min=0.05)
自适应调整:当误差或准确率达变化很小时调整学习率
torch.optim.lr_sheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10,verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08) (涉及环境较为复杂,此处不做示例) 自定义函数调整(最常用):每次增加迭代次数的百分之一
lambdaf = lambda epoch: 0.05 + (epoch) / 100
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambdaf)
Warmup
深度学习网络往往非常庞大,有时候训练一次epoch需要数小时。学习率设置不合理会浪费大量时间。设置学习率需要确定三个问题:初始时的学习率、终止时的学习率,以及如何变化。其中的变化方法一般有直线变化,曲线变化,或者跳变,只要足够细化,使用哪种方法问题都不大;终止学习率可视学习效果设定,比如当模型在验证集上不再变好,可尝试将学习率调到更低。
初始学习率的设置方法可借鉴论文《Cyclical Learning Rates for Training Neural Networks》。文中介绍了估计最小学习率和最大学习率的方法,比如在首次训练时(第1个epoch),先设置一个非常小的初始学习率,在每个batch之后都更新网络,同时增加学习率,统计每个batch计算出的loss,看增加到多大时,loss开始变差(很容易看到,调大到一定程度,loss变大,甚至变成nan),从而得到初始学习率。其核心在于将学习率由小变大。
Warmup预热是一种非常流行的对学习率先升后降(三角学习率)的调整方法,就效果而言,通常情况下:三角学习率> 按照auc逐步衰减> 保持均值不变。
尽管上述工具简化了调整学习率的工作,但暂时还未找到一种任何情况下都适用的方法,具体的学习率变化方法及其范围仍需要在具体数据集上实验。
笔者的体验是在前期加了lr变大收敛往往非常快,后期变小效果又非常好。过于手调可能降低模型的泛化能力,但针对具体问题,尤其是在数据量较大的情况下(如训练一次几十个小时),一定要精调。使用指数,步长调节方法虽然看起来整整齐齐,但是限制也多,还是建立自己写lambda函数优化更到位,如果使用现成的工具,则根据其example以微调为主。
下面展示一些warmup相关代码:
定义warmup函数
def warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor):
def f(x): # x是step次数
if x >= warmup_iters:
return 1
alpha = float(x) / warmup_iters # 当前进度 0-1
return warmup_factor * (1 - alpha) + alpha
return torch.optim.lr_scheduler.LambdaLR(optimizer, f)训练前设置
lr_scheduler = None
if warmup:
warmup_factor = 1. / 1000
warmup_iters = min(1000, len(train_loader) - 1)
lr_scheduler = warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)训练时每次优化后调用
if lr_scheduler is not None:
lr_scheduler.step()
print(i, optimizer.state_dict()['param_groups'][0]['lr'], np.mean(arr_loss))
arr_lr.append(lr_scheduler.get_lr()[0]) # 加入数组用于后期绘图
arr_loss_all.append(np.mean(arr_loss))