高速缓存与一致性专栏索引

Linux Programmer
我一直坚持由浅入深的方式发布文章,因此时间线就是很好的阅读顺序。但是文章日益增多,或许部分读者喜欢阅读自己感兴趣方向的文章。因此,为了方便大家,有必要引入一个索引。
- 首先是介绍高速缓存的基本原理,硬件是如何缓存和查找数据,这是个基础入门。
- 针对高速缓存基本原理中引入的问题,在下篇文章中解答。从代码的角度考虑高速缓存是如何影响我们代码的运行。
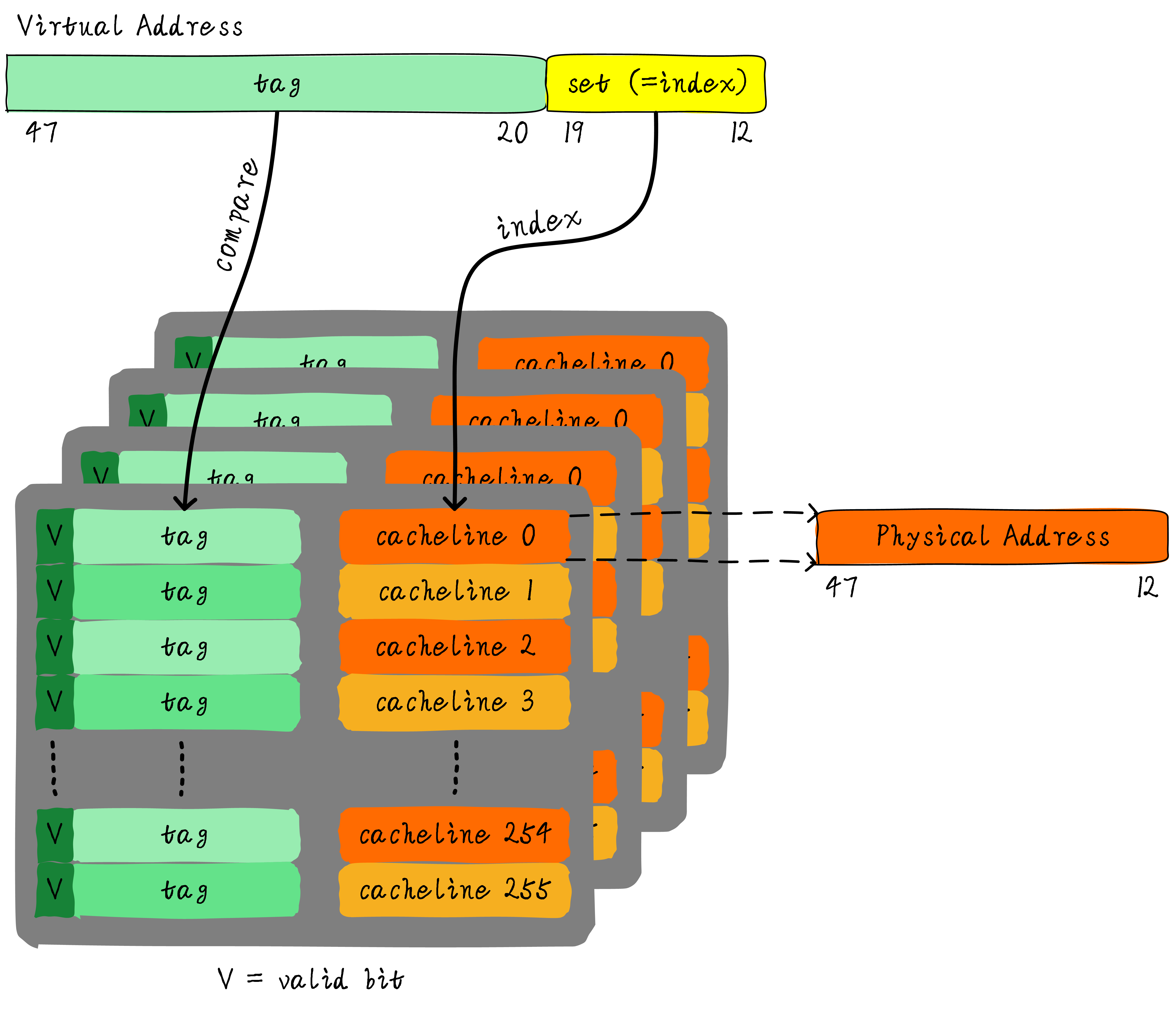
- 我们对高速缓存已经有了一定的认知,也明白高速缓存的基本原理。但是在高速缓存查找命中时使用的是虚拟地址还是物理地址?另外,高速缓存可能存在别名和歧义问题,操作系统是如何解决这些问题?
- 经过上篇文章的洗礼,我们明白了高速缓存的不同设计方式。并且知道了虚拟地址和物理地址对高速缓存设计的影响。同时引入一个新的问题,MMU转换虚拟地址到物理地址时也使用了一块特殊的高速缓存TLB。下面认识下TLB的原理,以及TLB的歧义和别名问题。
- 从这一刻起,你已经真正的了解了CPU和高速缓存之间交互的基本原理,以及可能遇到问题。但是系统中往往除了CPU以外还存在其他控制器,例如DMA。接下来将带你了解高速缓存和DMA之间的一致性问题。
- 以上DMA一致性问题只是其一,我们还要面对其他的一致性问题。我们的高速缓存不但有数据高速缓存(dCache)还有指令高速缓存(iCache)。因此dCache和iCache之间的一致性问题也需要思考。
- 前面的一系列文章我们考虑的基本都是单核场景。从现在开始,欢迎来到多核世界。多个CPU之间也同样存在一致性问题。而针对这种问题,我们又是如何解决的呢?
- 了解了多核cache一致性协议MESI后,或许我们对原子操作的硬件实现有了新的想法。硬件实现原子操作时,是否可以借助MESI协议简单实现呢?
- 到这里,似乎Cache一致性问题告一段落。并且我们也明白了高速缓存的数据是如何在多核之间传递,MESI协议又是如何保证Cache一致性。但是,随着多核的引入,也让我们面对了新的问题 - 伪共享。
- 当我们掌握了足够的高速缓存相关知识后,作为软件工程师的我们又是如何针对Cache对代码做特定的优化呢?我们以spinlock的实现为例,一步步优化到底。
- 就像spinlock的进化史,软件工程师会对自己的代码做足够的优化以提高性能。同样,硬件工程也不甘示弱,尽最大的努力设计硬件以获取最大性能。我们引入高速缓存的目的就是为了降低内存访问的延迟,谁知硬件工程师依然不满足高速缓存带来的延迟。为了进一步加快内存访问速度,硬件引入了新的缓存 - store buffer。随着store buffer的引入,彻底刷新了软件工程师对代码执行流的认知。我们之前考虑的一致性问题属于高速缓存一致性考虑的范畴,接下来面临的问题属于内存一致性范畴。
- 我们第一次接触的内存模型时TSO,这是最简单的一种模型。随着store buffer不以FIFO次序更新Cache之后,我们提出了新的内存模型PSO。
- 硬件的优化总是追求极致的。硬件工程师在不满足于PSO的基础上提出了更弱的内存模型RMO。
- 所有的内存模型告一段落。但是这并不是终点。软件工程师也不甘示弱,编译器优化工程师针对指令也会优化排序,编译器的插手使问题又复杂了一步。我们看下编译器是如何指令重排。
- 所有的理论终将要付诸于实践,因此作为软件工程师的我们如何正确使用屏障指令成为问题的关键。
编辑于 2022-01-13 23:08