
三分钟看懂强化学习系列05--贝尔曼方程

今天介绍一个强化学习中的重要概念。敲黑板!重点!重点!重点!大名鼎鼎的贝尔曼方程(Bellman Equation)。

贝尔曼方程(Bellman Equation)
因为太重要了,以下引入百度百科关于贝尔曼方程的介绍
贝尔曼方程(Bellman Equation)也被称作动态规划方程(Dynamic Programming Equation),由理查·贝尔曼(Richard Bellman)发现。
贝尔曼方程是动态规划(Dynamic Programming)这些数学最佳化方法能够达到最佳化的必要条件。此方程把“决策问题在特定时间怎么的值”以“来自初始选择的报酬比从初始选择衍生的决策问题的值”的形式表示。借此这个方式把动态最佳化问题变成简单的子问题,而这些子问题遵守从贝尔曼所提出来的“最佳化还原理”。
嗯,如果没看懂,没关系。粗暴的解释,贝尔曼方程就是用来简化强化学习或者马尔可夫决策问题的。就是把复杂问题简单话!

还记得我们之前讲到的价值函数 V(S) (Value function)的定义吗?这里重复一下:
【定义式】
马尔科夫奖励过程的某一状态(S)的价值函数V(S)是从这个状态开始的未来期望累计回报:
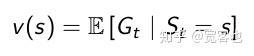
听着很简单,可是未来那么多不确定,你怎么让我算价值函数?所以引入了贝尔曼方程(Bellman Equation)。
【定义式】
如何简化马尔科夫奖励过程的价值函数呢?我们可以把价值函数分解为两部分:
*即时奖励 R_{t+1}
*加了权重 \gamma 的后续状态的价值函数 \gamma v(S_{t+1})
其数学表达式是
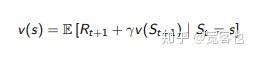
话句话说,贝尔曼方程只往前考虑一步。在某个状态下,我做了一个行动,得到了立即回报。我就可以将这个立即回报加上未来后续状态的价值函数做为我的总体回报。也就是上式中的 R_{t+1}+\gamma v(S_{t+1}) 。对这个总体回报求期望,就得出了状态 s 的价值函数。推导过程呢,就是这个样子喋:
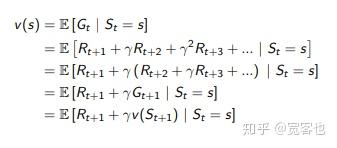

还不懂?老段子拿来再解释一下。比如说,你(强化学习里的代理agent)在某个时刻非常有幸的点开了我的这篇文章。我们把这个称为你当前的状态 S 。在你点开的一瞬间,你的脑海里出现了无数个可能。

如果你选择读完这篇文章,你得到了一个正的即时奖励(立即回报) R_{t+1}。恭喜你,你离迎娶白富美,当上CEO更近了一步。你的未来收益是加了权重 \gamma 的后续状态的价值函数 \gamma v(S_{t+1})。为方便解释,我们定义它为后续价格函数1.
你也可能觉得我废话太多,瞅了一眼,就决定去看个剧,玩个游戏。恭喜你,你离成为游戏主播,明星编剧更近了一步。但是你离成为机器学习大拿的道路越来越远。你得到了一个负的立即回报 R_{t+1}。你的未来收益还是加了权重 \gamma 的后续状态的价值函数 \gamma v(S_{t+1})。为方便解释,我们定义它为后续价格函数2.
注意,此后续状态的价值函数2,并非彼后续价格函数1。毕竟多读一篇文章,使我离梦想更近了一步。后续价格函数1的期望值很大概率上比后续价格函数2的期望值要高。所以贝尔曼方程就是我们在当前时刻的某一个决策给我们带来的立即回报 R_{t+1}(一般是已知的)加上此决策下的未来后续回报\gamma v(S_{t+1})的期望和。这里不要忘了给后续回报加上权重。别嫌麻烦,重要知识点强调一下,所以这就是贝尔曼方程(Bellman Equation):
