
决策树的生成之ID3与C4.5

1 基本概念
在正式介绍决策树的生成算法前,我们先将上一篇文章中介绍的几个概念重新梳理一下;并且同时再通过一个例子来熟悉一下计算过程,以便于后续更好的理解决策树的生成算法。
1.1 信息熵
设X是一个取值为有限个的离散型随机变量(例如前一篇引例中可能夺冠的16只球队),其概率分布为P(X=x_i)=p_i,\;i=1,2,...,n(每个球队可能夺冠的概率),则随机变量X的信息熵定义为:
H(X)=-\sum_{i=1}^np_i\log{p_i}\;\;\;(1) \\
其中,若p_i=0,则定义0\log0=0;且通常\log取2为底或e为底时,其熵的单位分别称为比特(bit)或纳特(nat)。如无特殊说明,默认2为底。
1.2 条件熵
设有随机变量(X,Y),其联合概率分布分P(X=x_i,Y=y_i)=p_{ij},\;i=1,2,...,n;\;j=1,2,...,m,条件熵H(Y|X)表示在已知随机变量X的条件下,随机变量Y的不确定性,其定义为
H(Y|X)=\sum_{i=1}^np_iH(Y|X=x_i)\;\;\;(2) \\
其中,p_i=P(X=x_i),i=1,2,...,n
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称之为经验熵(empirical entropy)和经验条件熵(empirical coditional entropy)。(P.s. 暂时看不懂没关系,请看后面计算示例)
1.3 信息增益
从上一篇文章的内容可知,所谓信息增益指的就是事物U的信息熵H(U),在引入外部信息I后的变化量:H(U)-H(U|I)。因此,我们将特征A对训练数据集D的信息增益d(D,A)定义为:集合D信息熵H(D)与特征A给定条件下D的条件熵H(D|A)之差,即
g(D,A)=H(D)-H(D|A)\;\;\;(3) \\
设训练集为D,|D|表示所有训练样本总数;其中有K个类别C_k,k=1,2,...,K;\;|C_k|为属于类C_k的样本总数,即\sum_{k=1}^K|C_k|=|D|;设特征A有n个不同的取值{a_1,a_2,...,a_n},根据特征A的取值将D划分为n个子集D_1,D_2,...,D_n,|D_i|为子集D_i中的样本个数,即\sum_{i=1}^n|D_i|=|D|;同时记子集D_i中,属于类C_k的样本集合为D_{ik},即D_{ik}=D_i\bigcap C_k,|D_{ik}|为D_{ik}的样本个数。(P.s. 都是概念定义,可稍后带入下面的例子会更加清晰) 则有如下定义: (1)数据集D的经验熵H(D)为
H(D)=-\sum_{k=1}^K\frac{|C_k|}{|D|}\log_2\frac{|C_k|}{|D|}\;\;\;(4) \\
(2)特征值A对数据集D的经验条件熵H(D|A)为
H(D|A)=\sum_{i=1}^n\frac{|D_i|}{|D|}H(D_i)=-\sum_{i=1}^n\frac{|D_i|}{|D|}\sum_{k=1}^K\frac{|D_{ik}|}{|D_i|}\log_2{\frac{D_{ik}}{D_i}}\;\;\;(5) \\
(3)信息增益
g(D,A)=H(D)-H(D|A)\;\;\;(6) \\
1.4 计算示例
如果仅看上面的公式肯定会很模糊,下面我们进行举例说明(将公式同下面的计算式子对比着看会更容易理解)。下表是一个由15个样本组成的贷款申请训练数据集。数据包括4个特征,最后一列表示是否通过申请,即每个样本对于的类标。
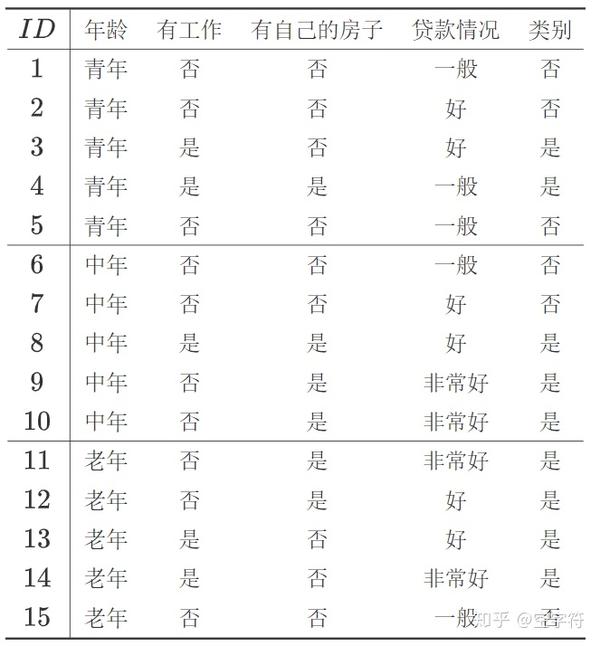

(1)计算H(D),根据公式(4)有:
H(D)=-(\frac{9}{15}\log_2\frac{9}{15}+\frac{6}{15}\log_2\frac{6}{15})=0.971 \\
(2)计算条件熵 由上表我们可以知道,数据集有4个特征(年龄、工作、房子、贷款)A_1,A_2,A_3,A_4;接下来我们计算D分别在4个特征条件下的熵H(D|A_i)。
- 在知道外部信息年龄的情况下,根据公式(5)有:
\begin{aligned} H(D|A_1)=&\left[\frac{5}{15}H(D_1)+\frac{5}{15}H(D_2)+\frac{5}{15}H(D_3)\right]\\[2ex] =&-\frac{5}{15}(\frac{2}{5}\log{\frac{2}{5}}+\frac{3}{5}\log{\frac{3}{5}})\\[2ex] &-\frac{5}{15}(\frac{3}{5}\log{\frac{3}{5}}+\frac{2}{5}\log{\frac{2}{5}})\\[2ex] &-\frac{5}{15}(\frac{4}{5}\log{\frac{4}{5}}+\frac{1}{5}\log{\frac{1}{5}})\\[2ex] =&0.888 \end{aligned} \\
这里的D_1,D_2,D_3分别是A_1取值为青年,中年,老年时训练样本对应划分后的子集。
\begin{aligned} H(D|A_2)=&\frac{5}{15}H(D_1)+\frac{10}{15}H(D_2)\\[2ex] =&-\frac{5}{10}\times0\\[2ex] &-\frac{10}{15}(\frac{4}{10}\log{\frac{4}{10}}+\frac{6}{10}\log{\frac{6}{10}})\\[2ex] =&0.647 \end{aligned} \\
这里的D_1,D_2分别是A_2取值为是或否时训练样本对应划分后的子集。
\begin{aligned} H(D|A_3)=&\frac{9}{15}H(D_1)+\frac{6}{15}H(D_2)\\[2ex] =&-\frac{9}{15}(\frac{3}{9}\log{\frac{3}{9}}+\frac{6}{9}\log{\frac{6}{9}})\\[2ex] =&0.551 \end{aligned} \\
这里的D_1,D_2分别是A_3取值为是或否时训练样本对应划分后的集。
\begin{aligned} H(D|A_4)=&\left[\frac{5}{15}H(D_1)+\frac{6}{15}H(D_2)+\frac{4}{15}H(D_3)\right]\\[2ex] =&-\frac{5}{15}(\frac{4}{5}\log{\frac{4}{5}}+\frac{1}{5}\log{\frac{1}{5}})\\[2ex] &-\frac{6}{15}(\frac{2}{6}\log{\frac{2}{6}}+\frac{4}{6}\log{\frac{4}{6}})\\[2ex] =&0.608 \end{aligned} \\
这里的D_1,D_2,D_3分别是A_4取值为一般,好,非常好时训练样本对应划分后的子集。
(3)计算信息增益
\begin{aligned} g(D,A_1)=0.971-0.888=0.083\\[1ex] g(D,A_2)=0.971-0.647=0.324\\[1ex] g(D,A_3)=0.971-0.551=0.420\\[1ex] g(D,A_4)=0.971-0.608=0.363\\[1ex] \end{aligned} \\
到目前为止,我们已经知道了在生成决策树的过程中所需要计算的关键步骤信息增益,接下来我们就开始正真的生成一颗决策树。
2 决策树的生成
在前一篇文章中的末尾我们总结出构建决策树的核心思想就是:每次划分时,要选择使得信息增益最大的划分方式,以此来递归构建决策树。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。因此,对于决策树生成的一个关键步骤就是选取对训练数据具有分类能力的特征,这样可以提高决策树学习的效率,而通常对于特征选择的准则就是我们前面谈到的信息增益。
2.1 ID3算法
ID3(Interactive Dichotomizer-3)算法的核心思想是在选择决策树的各个节点上,利用信息增益来作为选择特征的标准,从而递归地构建决策树。其过程可以概括为:从根节点开始,计算所有可能划分下的信息增益;然后选择信息增益最大的特征作为划分特征,由该特征的不同取值建立子节点;最后对子节点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有可以选择为止。例如根据上面1.4小节的计算结果可知,首先应该将数据样本以特征A_3(有无自己房子)作为划分方式对数据集进行第一次划分。
训练步骤如下:
输入:训练数据集D,特征集A,阈值\varepsilon;
输出:决策树
(1)若D中所有实例属于同一类C_k(即此时只有一个类别)则T为单节点树,将C_k作为该节点的类标记,返回T;
(2)若A=\emptyset,则T为单节点树,并将D中实例数最大的类C_k作为该节点的类标记,返回T;
(3)否则,计算A中各特征对D的信息增益,选择信息增益最大的特征A_g;
(4)如果A_g的信息增益小于阈值\varepsilon,则置T为单节点树,并将D中实例数最大的类C_k最为该节点的类标记,返回T;
(5)否者,对A_g的每一个可能值a_i,依A_g=a_i将D分割为若干非空子集建立为子节点;
(6)对于第i个子节点,以D_i为训练集,以A-\{A_g\}为特征集,递归地调用(1)-(5),得到子树T_i,返回T_i
2.2 生成示例
下面用ID3算法对上表中的数据集进行学习:
易知该数据集不满足步骤(1)(2),所以开始执行步骤(3)。同时,根据前面1.4小节是计算结果可知,对于特征A_1,A_2,A_3,A_4来说,在A_3的条件下信息增益最大,所以应该选择特征A_3作为根节点。
\begin{aligned} g(D,A_1)=0.971-0.888=0.083\\[1ex] g(D,A_2)=0.971-0.647=0.324\\[1ex] g(D,A_3)=0.971-0.551=0.420\\[1ex] g(D,A_4)=0.971-0.608=0.363\\[1ex] \end{aligned} \\
本例中未设置阈值,所以执行步骤(5),将训练集D安装A_3的取值划分为两个子集D_1,D_2,如下表
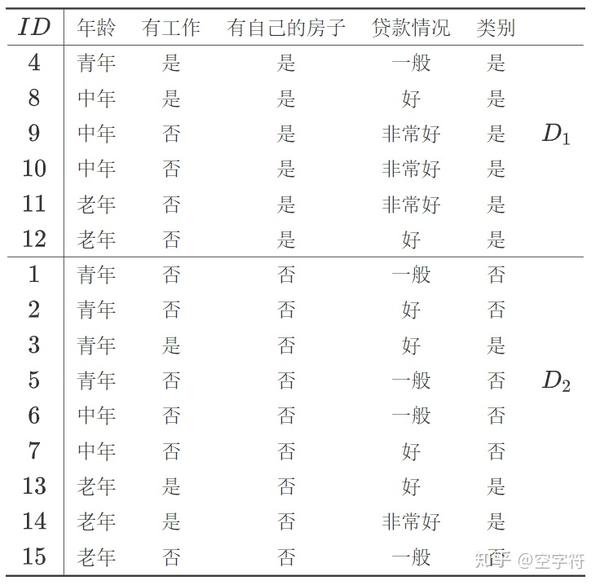

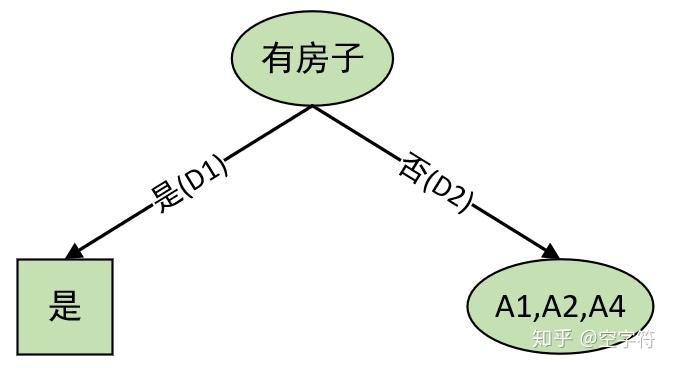
开始执行步骤(6),由于D_1满足步骤(1)中的条件,所以它成为一个叶节点,节点的类标记为“是”。则此时的决策树如下:

易知D_2不满足步骤(1)(2)中的条件,所有对D_2执行步骤(3),此时D_2需要从特征A-\{A_g\}中即A_1,A_2,A_4中选择新的特征,并计算信息增益:
\begin{aligned} H(D_2)=-\left[\frac{2}{3}\log{\frac{2}{3}}+\frac{1}{3}\log{\frac{1}{3}}\right]=0.918 \end{aligned} \\\begin{aligned} H(D_2|A_1)=&-\frac{4}{9}(\frac{3}{4}\log{\frac{3}{4}}+\frac{1}{4}\log{\frac{1}{4}})-\frac{3}{9}(\frac{2}{3}\log{\frac{2}{3}}+\frac{1}{3}\log{\frac{1}{3}})=0.667\\[2ex] H(D_2|A_2)=&-\frac{6}{9}(1\cdot\log{1})-\frac{3}{9}(1\cdot\log{1})=0\\[2ex] H(D_2|A_4)=&-\frac{4}{9}(1\cdot\log{1})-\frac{4}{9}(\frac{2}{4}\log{\frac{2}{4}}+\frac{2}{4}\log{\frac{2}{4}})=0.444\\[2ex] \end{aligned} \\\begin{aligned} g(D_2|A_1)=0.918-0.667=0.251\\[1ex] g(D_2|A_2)=0.918-0.000=0.918\\[1ex] g(D_2|A_4)=0.918-0.444=0.474\\[1ex] \end{aligned} \\
计算后发现信息增益最大的特征是A_2,所以执行步骤(5),将D_2划分为两个子集D_{21},D_{22},如下表:
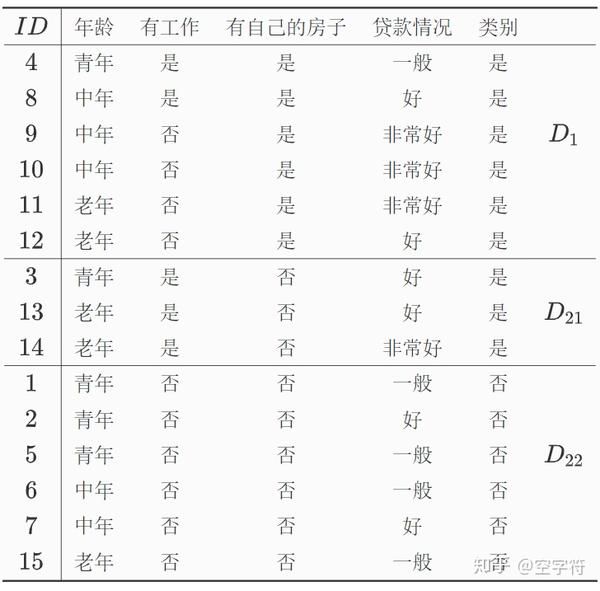

由划分后的结果可知,D_{21},D_{22}均满足步骤(1)中的条件,所以两部分均为叶节点,节点的类标记分别为“是”和“否”,到此递归结束;最终生成的决策树如下图所示:
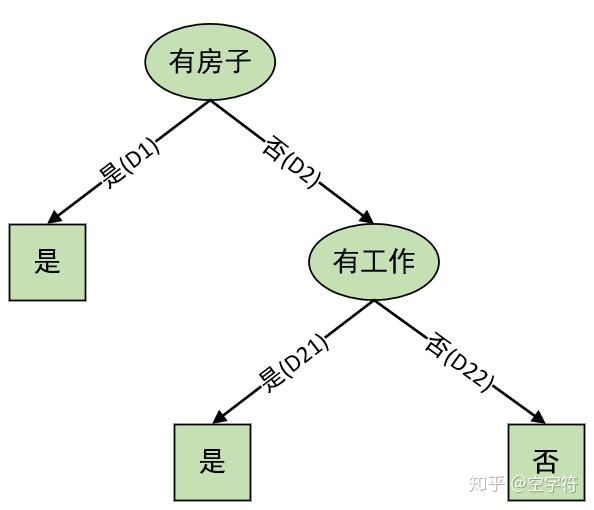

如上就是整个决策树的生成过程,但同时我们也可以清楚的看到,ID3算法极易导致过拟合。原因就在于,如果单纯以g(D,A)作为标准的话,会存在偏向于选择取值较多的特征(比如上面的A_1,A_4)虽然在这个例子中不存在。但是我们仍可以从直观上理解为什么ID3会偏向于选取特征值取值较多的特征。由于g(D,A)的直观意义是D被A划分后不确定性的减少量,可想而知当A的取值很多时D会被划分成很多分,于是其不确定性自然会减少很多,从而ID3算法会倾向于选择取值较多的特征作为划分依据。可以想象如果这样做的话,我们最终得到的决策树将会是一颗很胖很矮的决策树树,进而导致了模型的过拟合现象。
2.3 C4.5算法
为了解决ID3算法的弊端,从而产生了C4.5算法。C4.5算法与ID3算法相似,不同之处仅在于C4.5算法在选择特征的时候采用了信息增益比作为标准。具体为,特征A对训练集D的信息增益比g_R(D,A)定义为其信息增益g(D,A)与其训练集D关于特征A的信息熵熵H_A(D)之比,即
g_R(D,A)=\frac{g(D,A)}{H_A(D)}\;\;\;(7) \\
其中,H_A(D)=-\displaystyle\sum_{i=1}^n\frac{|D_i|}{|D|}\log_2{\frac{|D_i|}{|D|}},n是特征A取值的个数。
如在前面的例子中,对于选取根节点时,其增益比计算如下:
\begin{aligned} g(D,A_1)=0.971-0.888=0.083\\[1ex] g(D,A_2)=0.971-0.647=0.324\\[1ex] g(D,A_3)=0.971-0.551=0.420\\[1ex] g(D,A_4)=0.971-0.608=0.363\\[1ex] \end{aligned} \\\begin{aligned} H_{A_1}(D)&=-\sum_{i=1}^3\frac{|D_i|}{|D|}\log{\frac{|D_i|}{|D|}}\\[2ex] &=-(\frac{5}{15}\log{\frac{5}{15}}+\frac{5}{15}\log{\frac{5}{15}}+\frac{5}{15}\log{\frac{5}{15}})=1.585\\[2ex] H_{A_2}(D)&=-(\frac{10}{15}\log{\frac{10}{15}}+\frac{5}{15}\log{\frac{5}{15}})=0.918\\[2ex] H_{A_3}(D)&=-(\frac{9}{15}\log{\frac{9}{15}}+\frac{6}{15}\log{\frac{6}{15}})=0.971\\[2ex] H_{A_4}(D)&=-(\frac{5}{15}\log{\frac{5}{15}}+\frac{6}{15}\log{\frac{6}{15}}+\frac{4}{15}\log{\frac{4}{15}})=1.566\\[2ex] \end{aligned} \\
所以有:
\begin{aligned} g_R(D,A_1)=\frac{0.083}{1.583}=0.052\\[2ex] g_R(D,A_2)=\frac{0.324}{0.918}=0.353\\[2ex] g_R(D,A_3)=\frac{0.420}{0.971}=0.433\\[2ex] g_R(D,A_4)=\frac{0.363}{1.566}=0.232\\[2ex] \end{aligned} \\
训练步骤如下:
输入:训练数据集D,特征集A,阈值\varepsilon; 输出:决策树
(1)若D中所有实例属于同一类C_k,则T为单节点树,并将C_k作为该节点的类标记,返回T;
(2)若A=\emptyset,则T为单节点树,并将D中实例数最大的类C_k作为该 几点的类标记,返回T;
(3)否则,计算A中各特征对D的信息增益比,选择信息增益比最大的特征A_g;
(4)如果A_g的信息增益比小于阈值\varepsilon,则置T为单节点树,并将D中实例数最大的类C_k最为该节点的类标记,返回T;
(5)否者,对A_g的每一个可能值a_i,依A_g=a_i将D分割为若干非空子集建立为子节点;
(6)对于第i个子节点,以D_i为训练集,以A-\{A_g\}为特征集,递归地调用(1)-(5),得到子树T_i,返回T_i
从以上训练步骤可以看出,C4.5算法与ID3算法的唯一为别就是选择的标准不同,而其它的步骤均为一样。
3 总结
在本篇文章中,我们首先回顾了决策树中几个基本的概念并进行了演算示例;接着介绍了如何通过信息增益这一划分标准(即ID3算法)来构造生成决策树,并以一个真实的例子进行了演算;最后我们通过引入信息增益比(即C4.5算法)来解决ID3算法所存在的弊端。在接下来的一篇,我们将继续学习决策树的生成与剪枝算法。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1] 《统计机器学习(第二版)》李航,公众号回复“统计学习方法”即可获得电子版与讲义
[2]《Python与机器学习实战》何宇健
[3] 示例代码 : https://github.com/moon-hotel/MachineLearningWithMe
