事实表与维度表



前文介绍了一维表和二维表的异同及相互转换
今天再来解释一下事实表与维度表
先来看下表。回忆下,这是一维表二维表?
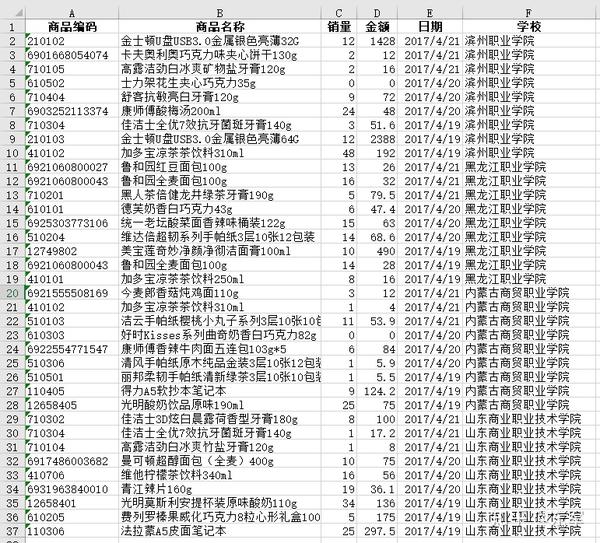

单行记录就能锁定全部信息,个别列存在数量重复,没二话,显然是一维表
那是不是结账系统里的订单表就是这副样子?
如果你没有接触过数据库,想当然一下,估计答案多半是肯定的——系统里的一维表就是长这样子
先不告诉你究竟对不对,咱先来看这么个场景
如果有个学校更名了,“山东商业职业技术学院”要改成“山东商贸学院”,怎么改?
会不会有人告诉我,用鼠标键盘一个个找出来改?
你还别笑,不管是谁第一次接触表格,可不就这样的修改的吗
但系统里的一维表,往往有成千上万行,靠人工查找修改,无疑愚公移山
那“查找替换”呢?
不错,“查找替换”起码比刚才那位人眼查找手工修改要强
但请记住,我们面对的不是普通的人工制表,几百行记录,查找替换耗时可忽略不计; 而系统生成的一维表,都是成千上万行,别说是查找替换,即便是平时双击打开一张电子表,打开速度都会受文件大小的影响
一张100K的表格可能是秒开,10M的表格也许会等上几秒,而打开100M的表格,慢得会让你以为死机了
如何避免因文件过大而产生的效率降低?那就把业务表里这种有大量重复的数据单独拎出来,放到另一张表里,通过表关联把二者连接在一起(如何提高表格运行效率,属于数据库范畴,涵盖了很多知识点。这里只是打个花式比喻,不必较真)

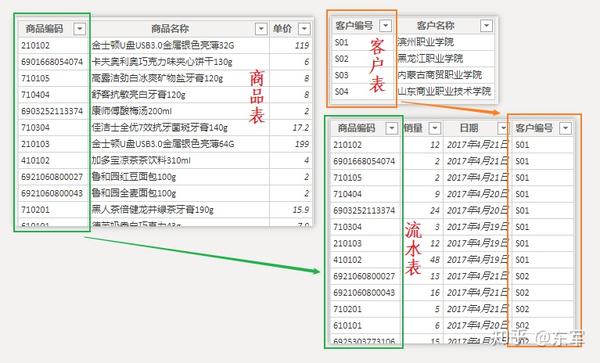
上图可见,流水表里把大量汉字换成字母/数字编码,将对表格大小起到重要作用
修改信息时也只要在维度表定位、变更一条记录即可,而不必在流水表里进行全表扫描。尤其在海量流水记录面前,效率高低立判
咱们这里不搞学究,没必要死抠概念术语,尽量从理解的基础上去领悟
像这种把流水表里大量重复数据拎到一边单独存放的案例,还有很多,比如
表示时间:日期-年-月-日-季-周(是不是有点像日期表)
表示地点:国-省/州-市-区县-镇-村
品类:用途-品牌-包装
…………
类似上面这些具有独立属性或层次结构的信息,我们将其称之为数据的维度
一个数据,可以属于不同维度,在不同维度上根据层次结构进行汇总统计(聚合)
为什么把它称为“维度”,见下图
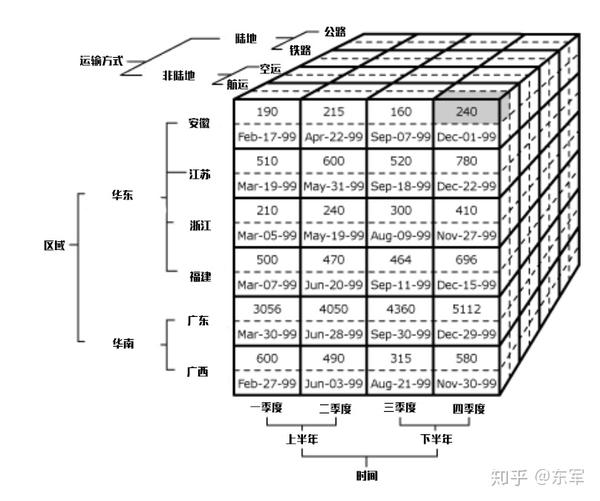

为了计算长度、面积或体积,我们把物体长宽高各维度相乘
同样,为了计算报表中值的数量,也可以通过报表的独立属性和层次结构中的成员数目相乘,那么“独立属性”和“层次结构”,就是报表的维度
搞清了“维度表”,那“事实表”也就不难理解了

事实表:表格里存储了能体现实际数据或详细数值,一般由维度编码和事实数据组成
维度表:表格里存放了具有独立属性和层次结构的数据,一般由维度编码和对应的维度说明(标签)组成
现实工作中,维度表要设多广多深,没有固定,看具体业务场景和数据规模
比如制造业,生产现场的时间维度可能要精确到秒
再比如销售,地区维度除了省市区,可能还要加个大区概念(华北、华东等)
证券行业里,板块、行业、概念等,都可以作为维度来拓展
没有通吃全行业的套路,一个行业 一套章法,沉浸于自己熟悉的业务领域,多学多练多交流
