
使用mmdetection2.0实现SOLOV2-全新的实例分割框架

使用mmdetection2.0实现SOLOV2-全新的实例分割框架
本文由林大佬原创,转载请注明出处,来自腾讯、阿里等一线AI算法工程师组成的QQ交流群欢迎你的加入: 1037662480
笔者近日在做一些实例分割到tensorrt的操作,发现,对于许多二阶段的实例分割算法,转换到另一个推理平台很麻烦,主要是这里面存在RPN的一些操作,即便是类似于CenterMask这样的模型,也需要先获取box,然后经过ROIAlign和ROIPool来得到需要的mask,这个过程不仅计算繁琐,而且很难导出到我们想要的模型格式,比如ONNX就不支持这里面的很多op。当我看到这张图的时候,我发现,SOLOV2的性能似乎比maskrcnn差不多,推理速度只要一半,并且速度和精确度都超过了BlendMask。今天我们就用mmdetection 2.0的版本来实现一个SOLOV2.
就目前来讲,很多实例分割算法存在的问题弊端主要是:
- 速度太慢了,比如Maskrcnn,虽然声名远扬,但是要把它部署到realtime,还是很困难的;
- 精度不够,比如Yolact,即便是Yolact++,其精度其实也只能说差强人意,连MaskRCNN都比不上的实力分割,速度再快,也会限制它的使用场景;
- BlendMask,CenterMask这类的算法,都差不多,基于FCOS构建,本质上没啥区别,还是和MaskRCNN整体流程差不多,只不过检测器变了而已,对于部署来说依旧很麻烦。
当然本文要解决的问题并不是部署问题,而是告诉大家,我们有一个速度更快,精度更好的模型,而且部署相对来说可能更好一点。那么第一步是不是得用python实现一波呢?
SOLOV2
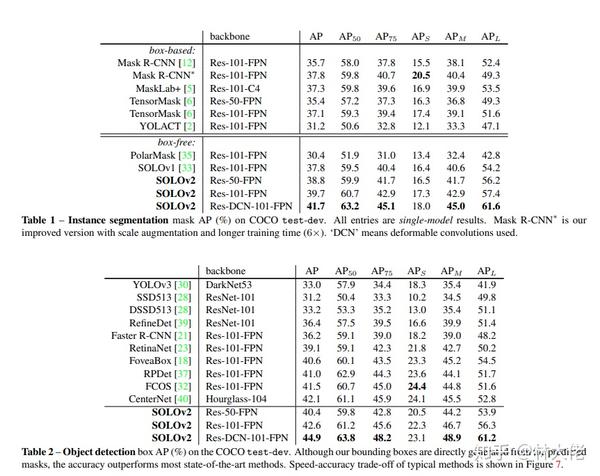
对于SOLO系列算法,具体的来龙去脉就不赘述了。先放一个指标对比:

对于V2来讲,变化最大的可能就是这个动态的mask head:
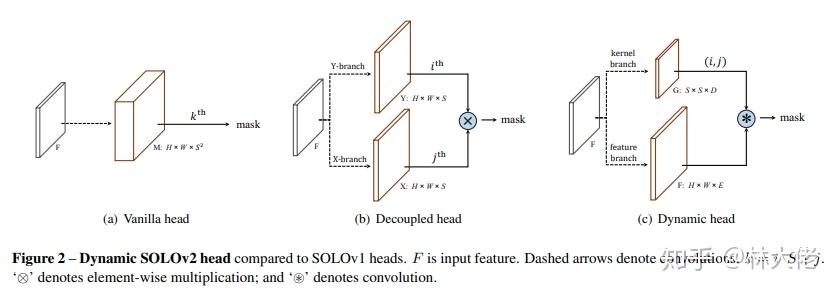

class SOLOV2Head:
....
def forward(self, feats, eval=False):
new_feats = self.split_feats(feats)
featmap_sizes = [featmap.size()[-2:] for featmap in new_feats]
upsampled_size = (feats[0].shape[-2], feats[0].shape[-3])
kernel_pred, cate_pred = multi_apply(self.forward_single, new_feats,
list(range(len(self.seg_num_grids))),
eval=eval)
# add coord for p5
x_range = torch.linspace(-1, 1, feats[-2].shape[-1], device=feats[-2].device)
y_range = torch.linspace(-1, 1, feats[-2].shape[-2], device=feats[-2].device)
y, x = torch.meshgrid(y_range, x_range)
y = y.expand([feats[-2].shape[0], 1, -1, -1])
x = x.expand([feats[-2].shape[0], 1, -1, -1])
coord_feat = torch.cat([x, y], 1)
feature_add_all_level = self.feature_convs[0](feats[0])
for i in range(1,3):
feature_add_all_level = feature_add_all_level + self.feature_convs[i](feats[i])
feature_add_all_level = feature_add_all_level + self.feature_convs[3](torch.cat([feats[3],coord_feat],1))
feature_pred = self.solo_mask(feature_add_all_level)
N, c, h, w = feature_pred.shape
feature_pred = feature_pred.view(-1, h, w).unsqueeze(0)
ins_pred = []
for i in range(5):
kernel = kernel_pred[i].permute(0,2,3,1).contiguous().view(-1,c).unsqueeze(-1).unsqueeze(-1)
ins_i = F.conv2d(feature_pred, kernel, groups=N).view(N,self.seg_num_grids[i]**2, h,w)
if not eval:
ins_i = F.interpolate(ins_i, size=(featmap_sizes[i][0]*2,featmap_sizes[i][1]*2), mode='bilinear')
if eval:
ins_i=ins_i.sigmoid()
ins_pred.append(ins_i)
return ins_pred, cate_pred对于mask的head大概可以通过这个实现,(code credit @Epiphqny).
论文中solov2最高可以达到42.6的 AP,我们实际训练下来可以达到接近40 AP的水平,这个水平大大的超越同样backbone的其他实例分割方法。
Results
我们在一些开源的SOLO上,将代码迁移到了mmdetection最新的2.0版本下。最新的测试结果如下:










这个效果总的来说还是非常不错的。我们已经将代码部署到了神力平台,如果你对实例分割感兴趣可以下载我们的code跑一跑,同时也希望你能加入我们的社群一起讨论交流最前沿的计算机视觉问题。
这个效果总的来说还是非常不错的。我们已经将代码部署到了神力平台,如果你对实例分割感兴趣可以下载我们的code跑一跑,同时也希望你能加入我们的社群一起讨论交流最前沿的计算机视觉问题。
http://manaai.cn/aicodes_detail3.html?id=61
如果你想学习人工智能,对前沿的AI技术比较感兴趣,可以加入我们的知识星球,获取第一时间资讯,前沿学术动态,业界新闻等等!你的支持将会鼓励我们更频繁的创作,我们也会帮助你开启更深入的深度学习之旅!

