
前端搞基建|小爝 - 如何推动基础架构项目落地


下期预告
下周六 - 6-20,是第十期 - 跨端跨栈 https://www.huodongxing.com/go/tl10
下下周六 - 6-27,是第十一期 - 女生专场 https://www.huodongxing.com/go/tl11
另外,每一期都提供了全年的联票,可以看所有场次的录播视频,包括下半年到年底的所有直播视频
本文是第一场讲师 - 小爝的讲稿文字版,给大家带来的分享是《如何推动基础架构项目落地》,今天的 PPT 风格是市面上失传了很久的高桥风PPT,绝对养眼看得清,来听听他的观点,视频及 PPT 未来在公众号放出。
正文开始
一、自我介绍


首先做一下自我介绍,我是来自新浪移动基础前端组的付强,我网名叫小爝,如果经常上知乎的朋友可能对我比较熟悉,不熟悉的朋友也没有关系,我简单的做一下我个人的经历介绍,目的是为了让大家了解我之前的背景,让大家更好的带入到我今天要讲的主题中。
我其实在前端开发行业工作了已经有 11 年了,从 15 年开始,不怎么写业务代码了,当然不是不写,而是写的少了,带过一阵子前端团队,也带过一阵子后端团队,组建过虚线或者实线的前端基础组。
客观上来讲,做过的一些产品现在大家可能还会在线上遇到,比如 PPT 里列的一些 LOGO 代表产品。而我最近的2段工作经历是国美和新浪,都是前端 Team 负责人,新浪现在是基础前端团队的 Leader,今天的主要内容也是围绕我在新浪做的一些基础建设工作的体会和心得吧。
二、基建经历


接下来讲的就是我的一些基建经历,其实我从15年之前,大部分时间还是一直在写业务的,从PC到移动的时代我也赶上了,从大家都经常用的 Nginx Combine 服务到 Grunt 或者 Gulp 打包,再到 SeaJS 或者 CommonJS 模块化的时代,最后再回归到现在的 webpack,Rollup 的时代。每个时间点都有前端自己关注和要去学习的东西,开始大家叫他们前端工程化,后来又有一阵子,人们叫前端统一开发环境,还有一阵子社区还特别流行 GUI 的工程化环境。然后到现在就又搞到走 CI/CD 的服务端 build 打包,总之各种玩法都经历过实践过,放到今天这个分享会的大主题下,我理解都算是前端基础架构的一部分。
我走上这条路其实也是从学习和翻译 SeaJS 代码开始的,自己做了个小轮子给新浪当时的 Team 来用,GitHub 可以搜索 Lithe.js,然后对应又了一套 Gulp 的 build 插件,以及对应的项目脚手架。在 13 年,14 年来看那时候很潮了,后来我记得 15 年的时候还在用国美用过一阵子,到了 16 年就全部被 webpack 替代了。
而 17 年到 20 年我回到新浪后,就又开始专注鼓捣前端基础建设,从 Node.js 的落地到周边基建,再到前端监控,打包上线流程的各种系统开发,最后再到容器化服务和 CI/CD 结合,基本各个领域都有所实际的尝试了。
三、团队介绍


做完了自我介绍,下边开始说一下我们团队的介绍,当然钱多,活少,离家近是开玩笑的,不过新浪确实不怎么加班倒是真的。这算题外话就不展开了。
我所在的团队叫新浪移动技术团队下面的基础FE。主要团队负责有2个产品,一个手机新浪网,一个新浪新闻 App,前端 Team 也分成了 2 个大组,一个组主要负责业务承接和开发,一个组,也就是我这边,负责内部系统和前端基础建设的开发。
我们团队现在有 9 个人,可能大家会比较好奇,尤其一些没有基础建设团队的公司,可能想不出来我们每天都在干点啥,KPI是怎么订的,如何拿结果,其实这个也是我们一直在探索的一个事情。我的 Team 一开始也并不是叫基础架构组,也是会写业务的,只是今年改了名字而已。
我们的主要职责,除了维护原来的长线业务之外,更多的是帮助开发处理一些产品帮不了,解决不了的内部问题。
我这么说可能还是太抽象,说具象一点就是我来这边 2 年多了,和产品打交道的时间基本没有,我个人也没有做过和业务相关的太多开发,更多的是去写一些业务需要调用的组件和服务。
当然这里包括了前端和后端的各种服务,有 BFF 层,也有框架脚手架,命令行工具,有统一的监控日志sdk,也会经常帮业务同学去做日志统计,分析和排查问题,解决 bug 等等。同时也会定期的,有 deadline 的输出一些内部后台系统,用来帮助业务更好的服务开发,运营以及编辑同学们。和业务团队的最大区别是我们不对接具体产品需求,因为我们做的东西产品不了解,我们技术开发自己就是产品经理。
四、如何建设基建团队


在开始讲实际案例之前,我我单独拿出来这个小主题给大家讲一讲我的个人经验,既如何建设基建团队。是因为确实不少的公司可能是没有明确做过或者专门组件过这种类型的团队。整体我分了 4 个小部分:
- 前端基础建设团队需要什么样的人。
- 前端基础建设团队需要做什么样的事。
- 前端基础建设团队需要掌握什么技能。
- 前端基础建设团队什么性格的人做更合适。
如果你想自己在自己的公司内部搭建一个基础架构组,这几个问题,也许能帮助你开始第一步的探索。
1、需要什么样的人?


首先,要组建一个基础前端团队,选择合适的员工可能是成功开始的第一步,首先他需要能够折腾,在平时的业务开发过程中,善于总结和喜欢分享,知道好的代码什么样,不好的代码什么样,有一定的抽象能力,时刻关注新鲜技术。
很多人可能觉得,这个要求和普通前端招聘的要求一样哎,但是不然,除了以上条件,还需要他们有一定时长的业务开发经历,如果把年限拉的长一些,比如3年工作经历,还能够保持折腾的心态,那么这个人一定很适合做基础前端研发。
那么我们团队有没有应届生和实习生这种水平的同学呢,肯定是会有的。但是基建团队的大部分组成人员还是需要以上这些条件的人来组成,因为毕竟实习生,应届生们的业务项目经验太少,他们做项目实施还可以,但是推动落地能力会非常的不顺利。因为他们可能体会不到业务真正的痛点和难处,沟通能力也可能有一些不足,毕竟人微言轻。并且最致命的是,经验少的同学可能无法理解为什么要这么做抽象,而不是那么做抽象,没有自己思考的过程。
比如我们需要做一个 IM 的 SDK,有经验的人会把消息部分和业务部分天然解耦合,消息部分又会分成多个层次的抽象实现,比如长连接,轮询,Flash,WS,MQTT 等等不同的适配层。至少一开始的架构是这个样子的,再慢慢扩展,而没有一定工作年限和经验的人,很可能就无法理解这里面的点。又比如很多人知道截流和防抖,但是在什么场景下落地这些细枝末节,没有一定工作经验的同学是做不来的,并且代码可能写完,整体的扩展性不足。
2、需要做什么样的事?


说完了需要什么样的人,我们来谈谈基建组的人每天都要做什么事。
刚才举例了 IM SDK,其实这只是一个点,很多前端的基础 SDK,在我这边都是基础团队负责的。比如埋点统计,性能统计收集,错误统计收集等基础库,UI相关的一系列 Vue Components,Hybrid开发中封装好的的 JSBridge 和 API 开发,联调等等。这些都是提供给业务团队的弹药,需要配套有测试,文档和 Demo 的产出,并定期更新维护和宣讲。
除了这些基础组件和 SDK,还有什么事要做呢?比如我们的工程化相关的建设,一开始也说了,代码的打包上线,CI
/CD 的实现和规范,代码上线前的自动化测试和检查,甚至编译时注入一些 Polyfill 代码,最后还有相关不同类型的项目脚手架,Cli 工具开发等等。
除了上面这些,还有没有别的事要做呢?当然还有了,比如我们内部使用的后台系统,比如运营后台,活动后台等等,还有我们自己自研的工具平台,比如 APP Scheme 管理平台,Hybrid 包下发平台,Etcd 配管平台,自动化测试后台等等。
除了这些平台工作的维护,我们还能做什么呢?比如新技术,新工具的调研,新业务场景下的新组件开发,架构设计,性能优化,都会有专门的同学去跟。在业务迭代时的一些基础组件的 Bugfx 等等。
当然,最后还有我们团队是有独立的开发后端服务的能力的,那么对应的 Web 框架,自建的一些 RPC 系统服务,日志服务,线上监控等一整套 Node.js 的解决方案,我们也是有落地和积累的,并且会维护一部分线上的 API 服务,业务模板页面等。
当然了,如果业务同学的业务压力比较大,基础团队也要上去帮忙写业务,或者做轮岗的,总之为业务开发服务,给业务技术赋能,就是基础团队要做的事。
3、需要掌握什么技能?


刚才说了人和事,现在说一些必备的技能,首先,基础建设团队的人不能给自己设限,这里的限制分2个层面:
一,语言层面不设限,比如 Python,PHP,JS,Java,OC,C++,如果需要你上,你都能很快理解并且上手写,至少照猫画虎能上手干活,这是我最直接得对我下面的人要求,大家要先成为一名程序员,再成为一名前端程序员。
二,领域层面不设限,比如前后端和客户端技能的不设限。我们有时候需要写后台服务,那么我们可能需要学习一些运维知识,后端语言工具,而有时候我们需要做些真机监控的工具,那就要学 Java 或者 Python,去真机上操作手机指令,进行客户端系统层面得拦截,这些技能都是基础建设团队工作需要的。
只有不设限,才能开眼界,眼界开了,工具才能变多,才能更好的体现出团队和别人不一样的地方。成长速度也会变快,学习的压力始终是基础建设团队的第一 KPI,保证能够做到别人做不到的事。
还有一点就是面向研发团队开发内部技术类产品。需要每个人都要有一些产品的基本技能,如画一些简单的 UE 交互,自己出点设计稿,然后还可以自己梳理需求并做拆解实现,这个能力我在我的团队中也会刻意去锻炼大家。
4、需要什么性格的人?


刚才说了爱折腾的性格,其实只是一个小的方面,性格映射到写代码上来说,我觉得最直观的可以分成两种:激进派和保守派。
激进派喜欢在 code 里炫技,各种地方都尝试用最新的api实现,FP,Ioc,OOP,TS各种工具,概念,语言特性能不能用,适合不适合用,都往上套。而保守派则喜欢朴实的代码风格,以实现功能为准,手快活好。
团队里通常这两种人都需要,但基础架构组更需要哪个性格的人呢?我觉得这个问题是不分对错的,如果炫技可以让性能更好,维护性更好,那我是很支持的,如果朴素一点就 OOP 加简单的模块划分,来维护也是可以做到代码简洁漂亮。
重要的是这两种性格的人如何配合,如何互相学习。我其实是不太愿意遵守代码规范写代码的人,当然这是我个人内心的想法,真写起来还是要遵守。但是我更希望写代码得时候能够有人和你进行碰撞,这样代码的质量和逻辑会更好,进步也会更快。
所以从上面来看,性格互补,不争强好胜,不嫌麻烦,有为人服务精神的同学更合适做基建。因为除了 coding 之外,如何让你的产品落地,让别人更喜欢用你的工具,没有换位思考能力的人是做不好这件事的。小到设计一个 API ,大到让别人接入你的系统,都需要那种时刻为团队共享利益出发的人,才能做的更好。
五、基建项目落地的方法论


前面讲完了,如何组建一个基础前端团队,下面我说一下落地的工具和产品,如何推广的一些技巧。
总结下来 5 个点,我一个一个展开来说说:
1、脸皮厚


这个我举个特别实际的例子。
我们去年开发了一个scheme的管理系统,帮助我们维护客户端内部的所有scheme的协议路径和参数配置,然后可以直接做成一个协议生成器,配合再出测试页和呼起落地页等功能,顺便连文档也直接支持了。
但是遇到一个问题,就是系统开发好了,怎么让客户端团队去使用。
第一步肯定是数据的录入维护,我们客户端内有大概60多个路由场景,每个路由带4,5个参数都是少的,还有通用的统计参数,公共参数等,所以整个数据源录入,我们前端自己做不行,也没有一手物料,容易录错,录丢。
但是客户端的业务又很忙,人家之前的wiki手写维护的好好滴,为什么要用你的系统啊。而且要去挨个核对之前的 Scheme 格式和参数。年前开发好第一个版本之后,年后系统里也一共没有录入几条数据。
为了解决问题,我的做法特别简单,除了拉人做宣讲(讲把wiki做成动态数据的好处),以及主动响应他们的录入时的一些交互需求之外。我还用了最原始,也最好用的一招,就是拉了一个专门维护数据的群,还有老板。然后每天早晨 10 点准时提醒,连续提醒了一周,没人理我我也每天都赔笑脸提醒,私聊提醒,最终在我的软磨硬泡下数据终于录完了。
很多人会说,人家不爱用是不是因为你的系统不好用?其实并不是,当数据全部录入后,客户端的反馈是很正面的,自己开发和测试自己的呼端协议,变的更方便了。不再需要前端给做测试页了,直接系统就可以生成二维码,很方便看效果,变更参数也更方便灵活了。整体的反馈很好,也都爱用了,而且还提了狠多修改建议。
所以厚脸皮是做基础建设落地项目的重中之重,我把他列到第一个,做其他的项目,无论是业务还是基建,我最长用也最好用的办法,就是每天给你打 call,群里 @,那最后一定可以推得动,当然方向一定要对。
2、亲耕策略


Personally,主要讲的是如果你作为一个项目落地的推进者,尤其是需要团队合作的项目。每个推广者必须自己熟悉并使用过,真正的体会这个工具或者系统解决了什么问题,站在业务方的视角,亲自用一用自己的系统,工具。
亲自去感受和思考是否真的解决了业务的问题,提高了生产效率。如果只是你觉得会这样,会那样,但是实际落地后,副作用可能比优点还要突出,那么就真的得不偿失了。
如何能够在落地项目前就避免这种情况呢?说到底还是要自己去实际的参与业务开发,从业务开发人员的视角,总结提炼出方法论和工具集。我认为亲耕策略是基础架构人员的必备核心能力。
3、轮岗


刚才说了亲耕策略,但是其实最好的一种理想状态就是轮岗。
让业务人员和架构人员能够按季度来进行工作内容的转换,那么就可以非常好的理解互相对彼此的作用。
比如我第一次调岗到一个组,本来去的时候是让我负责提升研发效率和对现有打包工具做优化的。但是我面对不熟悉的业务,根本也不知道提升的点在哪里,一头雾水。
然后我的选择就是先给我分两个实际的业务,我体验上一个月再说。在这一个月里,我会去看别的同事的代码,不同项目的组织形式和结构。自己写的时候会考虑如何在已有的结构上做设计和扩展更合理。
遇到效率问题会自己记录,并尝试解决。举个例子,比如当时(14 年初)开发完成的demo页,需要我们 build 完手工上传 FTP。这个地方很麻烦,还要新来的同学安装 FTP 工具,手工操作等。后来就被改造成了脚手架里自带的配置功能,build 完毕后加一个参数就直接上传到指定 FTP 目录了(支持配置FTP信息)。
很简单的一个点,但是实实在在提高了调试效率,就看有没有人发现和去做而已,不轮岗就很难发现。
4、奉献精神


如果有做过运维的同学一定很有这方面的体会。
基础运维服务理论上不出事就是应该的,因为你是基础服务,可是一旦出事就是大事。基础架构组的同学做的事情,都是在背后默默支撑的事情。平时如果领导并不是特别懂技术,虽然脏活累活都干了,但是出彩的永远还是业务。
可是做基建的同学们又必须有这个心态,奉献的心态。如果谁都不去做脏活,累活,难活,都去做简单的活,那么你的组织架构一定是不合理的,开发效率一定是上不去的,最后大家都在泥巴路里放飞自我了,我觉得这不是公司希望发生的情况,所以耐得住寂寞也是一种品质。
5、同理心


同理心这个事,比较好理解,在公司内部也是非常重要的一个推动事情的技巧。
几乎所有去跨部门沟通过的人都感受过这么一个情况。你的 KPI 不是别人的 KPI……那么我让对方配合的时候对方就会把优先级降到很低,甚至拖着就不给你做了。
这种情况太长见了,所以如何破局,用的就是同理心,如果别人来找你配合做一些代码改造,对自己短期没什么好处,反而近期会增加一些风险和成本。那么无论别人说的多么天花乱坠,这和我又有什么关系呢?
遇到这种情况,那么我们可以把自己当成业务人员,思考自己更关注的是什么?答案一般都是人力成本,deadline 这些问题。那么如果你的工具和系统,是可以直接提升对方KPI数据或者提高对方业务真正硬需求的时候,项目落地就是水到渠成得事。比如帮别人开发自动化的 Cli,比如帮别人开发通用业务组件,SDK 等又难又不好做的东西。
所以说技术是为业务服务的,架构人员要真的了解业务需要什么。然后实事求是得去为对方思考,这样才能接地气,达成双赢。
六、实际案例


前面说的都是一些方法论和我的个人经验,对错都是我自己的一个积累,可能很多人都要听烦了。
下边就是我们团队的一些实际案例,因为时间有限,我选了 6 个 case。每个 case 我尽量给大家讲明白,它是干啥的,对业务产生了什么作用,以及收益。
1、Node.js Web Framework


如何在前端部门 去落地 Node.js 服务,我当时刚到新浪的时候,算上我,做 Node.js 的只有2个人,所以基本可以说,我去新浪移动之前那边的 Node.js 服务基本是个空白。
后来我们也是从内部一些简单服务下手,比如前面说的那些内部管理系统开始做起。框架也是从Expressjs到koa再到自研的Daruk框架。
除了内部系统外,我们18年还承接了手浪的高清图服务和看点服务的文章落地页。整个过程大概半年,从php重构成Node.js,再到灰度,到全量,每天的pv都是千万级。
所以这个过程不得不说是一个特别好的机会,让我实践了 Node.js 从内部走到外部,从管理系统到线上大流量服务的进化,而这些的第一步就是选择一个合适的web框架。
在做我们内部系统的时候我就发现开发koa或者express服务,都缺少一个规范的目录和开发隔离结构,还有就是对应的一些业务类库和工具,日志相关的建设。所以经过整理,我们内部开发了1.0版本的Daruk框架,就是我们自己的内部的基于koa2的web framework。
他包含文件目录按功能隔离,根据controller文件自动生成path路由,带定时任务功能,带统一日志功能,带中间件性能统计,全局错误拦截,优雅关闭等功能的一个加强版框架,当然1.0不是基于TS的版本。
后来我们开源的Daruk是我们内部1.0版本的升级版。基于纯ts开发的版本,并且对脚手架,周边常见模块,和文档做了补充的一个版本。
使用TS和独立web框架带来的好处很多,比如我们的框架代码和业务代码会更容易维护,简化业务开发等,并且因为强制要求使用TS开发,我们减少了更多的隐性bug。
因为最开始我们开发线上大流量服务的时候,最怕的就是我们因为js本身编写出错造成的低级bug无法被发现。我们转化为TS开发后,因为在编译时就会有检查,所以大大降低了这种低级bug的出现概率,让服务更稳定。
关于Daruk,大家可以直接去看文档和源码,虽然2.0我还没有写完,但是也已经开源了,如果你也想做一个TS的web框架,可以参考的地方应该蛮多的。
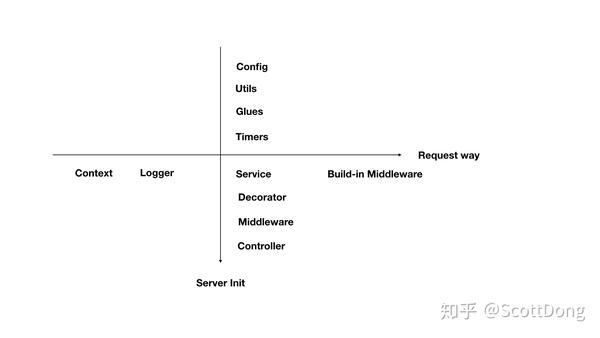

因为时间关系,我就只加了这一张图,简单的解释下整个Web服务的两条生命线,一条是横向的request链路,我们的web框架在context上增加了性能统计,日志打点还有一些内置的全局中间件。
另外一条线是纵向的server初始化链路,包含了本地目录模块的加载和配置,内置功能的自动初始化比如Timer和各种Glues的挂载以及运行,最后是局部中间件和路由的挂载。


当然我们除了web框架自研之外,我之前也说了,Node.js 层面的其他基础建设也是一穷二白,最后梳理完我们的服务上线流程和监控流程,看左边的顺序,首先是通过本地仓库的 CI 驱动代码上线,触发运维的 Docker 容器滚动和代码更新,上线完毕后我们有一套自己的全链路日志系统,通过在框架内的 Logger 模块实现配合相关的 SDK,中间件打点,把 Node.js 的业务标准日志从容器中,直接转发到对应的 Kafka,最后再使用公司运维部门统一的监控平台查看我们的线上服务日志。(日志标准化的好处)


最后我们看一下我们线上使用 Daruk 跑的几个服务和数据,有一些你们访问不了,因为是内网服务。这些后端服务完全是由我们前端基础组开发和支撑的,帮助公司解决了很多的实际问题,也因为把 PHP 做了切换,线上的性能和服务器也有所节约。
2、Hybrid Release System


这个系统我在我的知乎 Live 里也有讲过,这里可以带没听过的同学再简单过一次。


首先我们的APP里,离线包是通过 APP 拉取离线包配置,然后在本地解压缩后再去关联业务,实现的一套离线包下发流程。通过图片可以看出来 APP 在启动时,会拉取我们 PHP 服务的一个 Hybrid 配置 API,传递的参数是 env(环境),version(app版本),platform(App系统),然后我们的PHP配置API会从缓存中找已有的配置,通过这3个参数进行查询,如果失败了,会降级到我们的 Node.js 服务,也就是配管中心。进行查询和缓存的建立,最后返回给APP端。


这张图里就是我们的这个配置 API 的内容,我们可以简单看一下,data 中包含了所有请求 APP 版本,系统和环境下的离线包配置。每个离线包配置中带有 HB 的名字,HB 包的版本,下载地址,MD5 值,下载优先级以及 patch 信息。
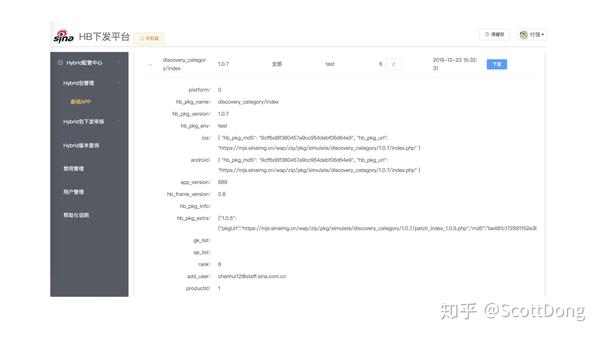

而如何把每个 HB 包的版本和不同的 APP 包版本,环境和平台做区分呢,依赖的就是我们的 Hybrid 下发平台,在这个平台里我们可以看到我们发的每一个 HB 包配置,操作人,平台下载地址,环境等信息。然后通过给这个 HB 包配置手工做 APP 版本关联,就是这个平台最主要的作用。
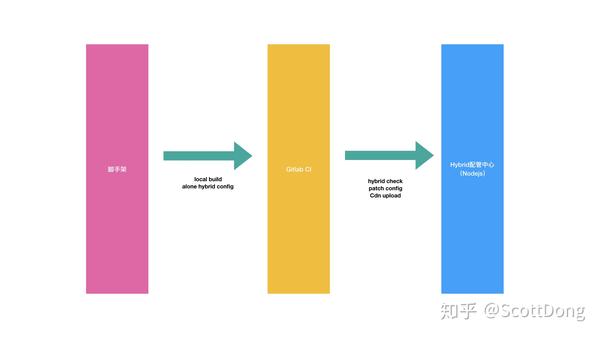

有同学可能不明白,那你这些 HB 包配置是怎么来的呢,他们的上线地址,操作人信息是如何拿到的。其实流程也比较简单,我们本地开发好一个 HB 业务后,通过脚手架进行打包,然后通过 GitLab CI 触发发包的 TAG,通过 TAG 驱动我们的 CI 进行 HB 包的上线,计算 Patch 信息,校验等步骤。然后把这些最后 CI 运行时拿到的信息,通过接口推送到 HB 下发平台的一个 API 中做入库保存。
这样我们每次在 CI 中打一次 TAG,走一次 Pipeline,就可以自动在 HB 下发平台中找到我们的推送配置了。
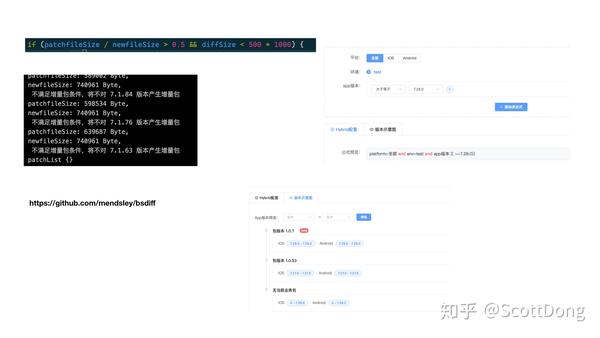

这里我跟大家说一下,我们计算 patch 的方法,条件就是如果计算 patch 的 size 比新生成的包 size 大一半,并且新生成的 patch 包小于 500KB 那么我们就会产生 patch 信息,客户端和前端都使用 bsdiff 算法进行的还原和 patch。
然后我们手工关联的部分是支持直接集成上一个 HB 包的信息的,也支持全APP版本的快捷选择,也支持使用表达式来进行勾选,非常的方便,同时也支持上线审核功能,权限管理功能等。
3、Gitlab CI/CD


说完HB后台的实现和功能后,大家可能会对我们的 CI/CD 流程感兴趣,下面我们就来讲一下我们的 GitLab CI/CD 是怎么实现,简单来说就是 TAG 触发 GitLab 流水线,然后流水线支持对不同的需求进行不同任务的调用,比如上线 test 和 online 我们流程上是有区分的,还有上线 H5 资源和 HB 资源我们流程上也是有区分得。
后边我说一下简单的实现流程和如何更好的管理自己的 CI 功能。


因为我们的 CI 是自己实现的,所以我们的 CI server 也是自己搭建的,通过内部 gitlab 的 token 把我们自己的 CI server 和 CI runner 与我们的项目进行关联,因为我们申请了 group token,所以全组的项目都会自动生成对应 ci runner,只需要增加 gitlab-ci.yml 就可以快速的使用相关任务了。
看右边的图,我们的一个 CI 任务运行时,其实执行代码都是基本一致的,首先安装一个内部的 npm 包,叫 ci-runner-script,这个包里包含了我们所有的 CI 任务能力的集合,或者说plugin集合。
然后通过执行这个包里面的cli命令,传入相关 GIT 环境变量信息,来判断需要执行什么 stages。
再通过读取源码中的脚手架配置文件,进行 CI 插件的初始化和运行,这样的好处非常明显,统一的任务功能我们架构组进行维护,而用不用的决定权在于每个项目的脚手架配置文件。


这里现实的就是我们的 CI 命令运行时做的事了,我们给 CI 定义了一个我们自己的生命周期,可以看 RUN 方法中的几个方法命名,然后又实例化了所有的 Plugin,每个 Plugin 里可以定义不同生命周期的钩子方法,每个钩子方法里会拿到上一个 Plugin 执行完毕后,需要传递的 context,这样就实现了 Plugin 之间信息的通讯和数据扭转,最后再通过开发不同的功能 Plugin,在 CI 各个生命周期做事情就可以了。
4、Scheme Data Center


这里讲的是一个如何管理 APP scheme 的系统,这个系统我就不说实现了,后端 Daruk,前端 Vue,整体项目设计不复杂,难点在于审核 Scheme 的时候,我们需要 JSON Diff 来做不同版本的 Scheme 提交时的差异识别,还有就是内置了一个短链接系统,用来生成 Scheme 测试页,还有内部有一套我们之前一直在用的动态表台组件,来驱动不同的 Scheme 的不同参数的录入和协议生成功能。


看图直观一些,这是我们的 Scheme 路由的录入界面,我们分了几类路由进行统一管理,录入的时候一级页面是路由和路由功能说明等信息,点进去二级页面就可以针对这个路由做参数的录入和文档补全。
http://i.scheme.sina.cn/scheme/callup?key=0ca2278a0503092044d8e695a869c9dd (二维码自动识别)
这张图左边是我们的协议生成器,整个表单都是通过录入的参数和协议进行了级联联动,选择一个路由,给路由所有参数进行展示,placeholder 写的就是录入时的例子,如果直接点生成 Scheme,就会出现每个字段例子最后拼成的scheme地址,可以方便客户端和测试人员测试,并且有二维码可以扫描,真机上调试功能非常方便。
整个系统不复杂,一般的公司 Scheme 没有这么多也不需要做,我们的目的有几个,一个是我们的 App 生命周期太长,需要一套标准文档输出给外部和合作部门,动态化方便管理。还有一个目的就是解决测试和联调的前端工作量,最后也是为了解决人员流动导致的文档丢失问题,我们后期还可以通过这个系统对外输出 API,提供给客户端人员做APP 自动化测试用。
5、FE Statistical


经历过刚才说的一系列 Node.js 项目之后,从一个前端转变成了全栈,其实对我个人有一个特别大的感悟就是前端的基础建设尤其是监控系统太弱了,所以我们后来又做了一系列的前端监控的前端 sdk,之后开发了一套路由中转系统,可以去收集不同类型的各种前端格式的日志,再进到咱们的 ClickHouse 存储,进行二次分析和监控。


我们一开始是做了不少竞品调研,比如腾讯的 BadJS,开源的 Sentry,还有收费的 Fundebug 等前端 SDK,吸取了他们的一些功能和特点,然后又根据 PageSpeed,Lighthouse,OneAPM 等这些性能分析工具的指标,对应给前端页面增加了性能相关的打点,统一进行了日志上报和收集。


下面给大家看一下我们收集来的日志之后都有什么纬度,首先错误收集相关的大家都比较熟悉了,还有性能相关的我们参考了 Lighthouse 中的几个关键指标来做打点,收集上报服务我们也是自动化的一套配置生成的动态 Node.js 服务。其实最有意思的应该是劫持监控收集,这个可以去知乎查一下我写过的一篇文章,面对前端劫持我们能做些什么的一个回答,好像是好几千的赞,详细的说明了这个系统的实现。
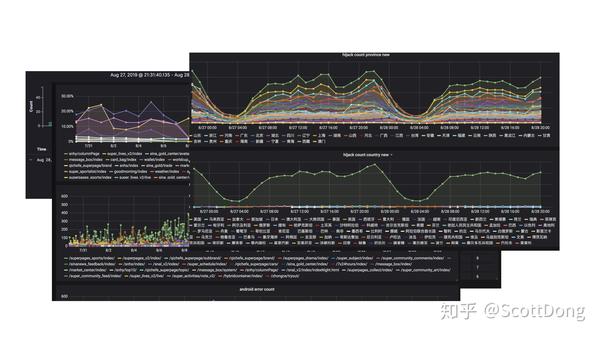

这里的几个图我列出来的是我们的 HB 和 H5 对应的一些性能指标和错误指标的曲线图,用的开源的 Grafana和ClickHouse 配合,大数据我们会有每天的定时任务去跑 SQL 做新聚合,做统计的一定会遇到的需求。
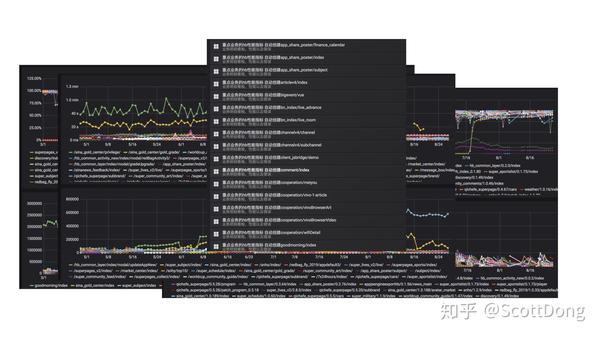

而这张图是我们的每一个 HB 业务包的相关日志打点图,这里要说的是我们的每个 HB 包的这些 Grafana 配置都是通过一套模板生成的,通过我们之前的 CI/CD 流程中的一个 Plugin,来进行自动创建的,每一个新 HB 包我们都有对应数据库保存,如果之前没有,我们则会去创建新的监控面板,非常方便,这也是动态化数据的好处,我们年底要写上次数,迭代次数,查看组件依赖等,对应都有数据累计,也是利用的 CI 统计。


这一页说的就是监控体系给我们带来的好处了,首先性能方面如果没有监控,我们就无法优化和量化优化成绩,观察性能走势。然后就是报错率和峰值的下降也可以从日志中追溯,最后就是反劫持的一些日志积累,因为有了自己的日志系统,能做的事情和可以统计分析的功能就太多啦。
这里有一个点,我们如何统计的 Scheme 呼起拦截量呢?很多人可能好奇,其实也很简单,我们发现常见的劫持方法,呼端都是通过 iframe 的 src 来驱动 Scheme 的发出,然后我们就把页面的 createElement 方法给改写了,如果有 iframe 元素被创建,那么我们就统计 src 的格式,如果是非正常协议就上报。
当然绕过方法也很多,我这里就不展开说了,成攻防战了,大家可以自己想想哈。
6、Universal framework


多端统一这个事,很多团队都有做,我这里分享的是,如何围绕 JSBridge 来实现的端内 HB 页面和端外 H5 页面一套代码,生成适配两端的一个实际经验。
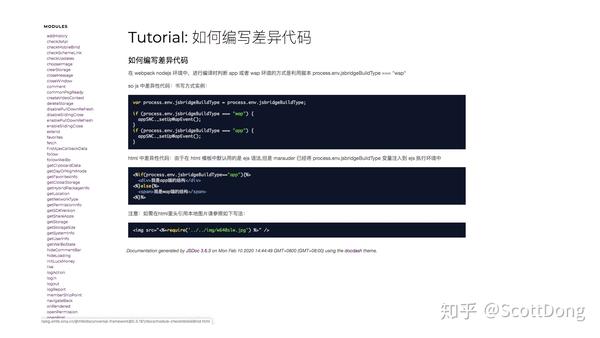

这张图是我们的 JSBridge 得文档首页,我们可以看到左边的一列是我们维护的基础 API,提供给了 JS 端上的一些能力实现。而右边这里我专门截取了如何编写差异代码的部分,其实也很简单,我们的脚手架里提供了编译时的一个变量,这个变量可以通过配置来改变,方便开发不同端的时候测试用。而写代码的时候,则可以直接通过判断编译时环境来进行条件判断了。
这里和运行时区分环境有一个很大的区别和好处,就是编译时我们做了语法解析,会删除这种判断中的冗余代码,让运行时的逻辑更少,而业务人员无感。
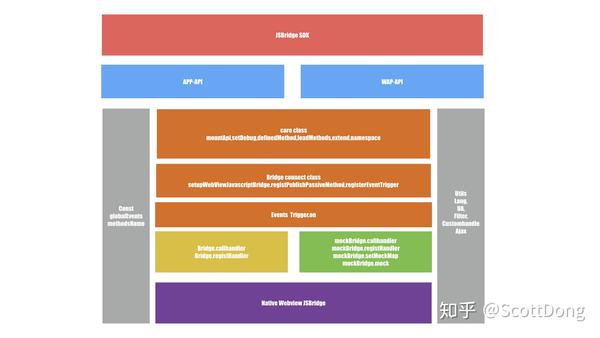

那么我们的 JSBridge 是如何抹平的这一套API的呢?
这张图是我们的 JSB 实现的架构图,我们只需要关注蓝色的部分,蓝色下面的部分是我们 JSB 内部的代码实现,解耦合和模块划分,这里不展开说了,比如我们支持 Mock 方式调试,支持jsb没初始化时,保存调用队列等功能。我们看蓝色的部分,这里是用户 API 和 JSB 的 Core 部分对接的 API 层,我们实现了一个挂载机制,如果编译时环境变量是 APP,那么我们的实现就挂载原始 JSBridge 中的消息通讯方式,如果是 WAP 端的环境变量,我们会在这一层挂载 WAP 端的抹平层 API,和编写业务代码一样,编译时区分运行时的逻辑,减少代码量。
七、总结


上面简单的讲完了几个例子后,我这里再次总结一下。
我们今天的主题是如何推动前端基础架构项目落地,而不是具体项目如何实现,因为时间原因,我也就不展开太多讨论,花费的大量篇幅,尤其是前面,可能更能帮到大家去做基础建设的落实。
最后,我还想说 3 个方面的讨论。
1、前端基础架构落地的必要条件
落地的必要条件还是因为业务需要,如果业务不需要,做了也没人用,但是有时候我们又不能被业务牵着鼻子走,比如我们的离线包发布系统,产品经理是不会管你这个东西怎么实现的,人家只是需要一个灵活的端内热更新功能,至于你怎么发版,如何管理,产品是思考不出来的,需要架构人员思考。那么我们作为基础建设的研发人员,就要有能力帮助产品和业务开发同学从系统层面解决这种实际问题。
2、基建和业务的关系
基础建设和业务的关系肯定是业务优先,但是业务又离不开基础建设的支撑,如何找好自己的定位呢,或者说,没人给你提需求的时候,你要如何发现需求呢?除了主动拉会让大家讨论平时工作中遇到的困难,进行梳理和总结,还要有一双善于发现问题的眼睛,多看多参与业务,互相紧密配合才行。
3、团队意义
这里说 2 个大实话,老板,尤其是技术团队的老板,和别的团队pk年终总结的时候,如果你的 Team 全都是业务产出,没有系统产出,这是非常可怕的一件事情。
基础架构团队为什么大公司都有,小公司没有,这是其中一个非常关键的原因,大公司技术团队除了低头赶路,还要抬头看路。梳理和总结内部服务系统,提升大团队开发效率,是必须要做的一件事。也是高层 Boss 考察下边技术Leader 能力的一个标尺,大家做过职级晋升的我就不多说了。
还有一个大实话就是,让团队小伙伴有一个主心骨,基础架构团队就是能干别人所不能,让团队有一个技术指路者吧,当然最终还是因为大型技术团队,尤其是多业务线的团队,需要一个这样的一部分集中处理开发团队内部技术问题的一群人。
至于其他的,我之前说的已经足够多啦,感谢大家今天来听我的分享。
Follow 小爝的更多动态
大家如果对小爝分享的内容很感兴趣,或者有疑问,都可以前去关注小爝的知乎哈,在知乎跟进小爝的动态,有非常多的高赞答案,特别有营养。

近两年 Scott 观察到前端行业已经完全进入竞争的深水区,各大小公司的前端 TL 刚刚上任,初带团队,针对前端工程师这个群体,应该怎么管人理事,搭台拿结果,帮带有成长,就成立了这个全国的前端技术主管学习交流群,在人的选用育留上互相学习成长,入群的门坎是你有实线或者虚线在带团队,请加 Scott 微信: codingdreamer 邀请入群.
