
BERT 可解释性-从"头"说起

一、背景介绍
搜索场景下用户搜索的 query 和召回文章标题(title)的相关性对提升用户的搜索体验有很大帮助。query-title 分档任务要求针对 query 和 title 按文本相关性进行 5 个档位的分类(1~5 档),各档位从需求满足及语义匹配这两方面对 query-doc 的相关度进行衡量,档位越大表示相关性越高,如 1 档表示文本和语义完全不相关,而 5 档表示文本和语义高度相关,完全符合 query 的需求。

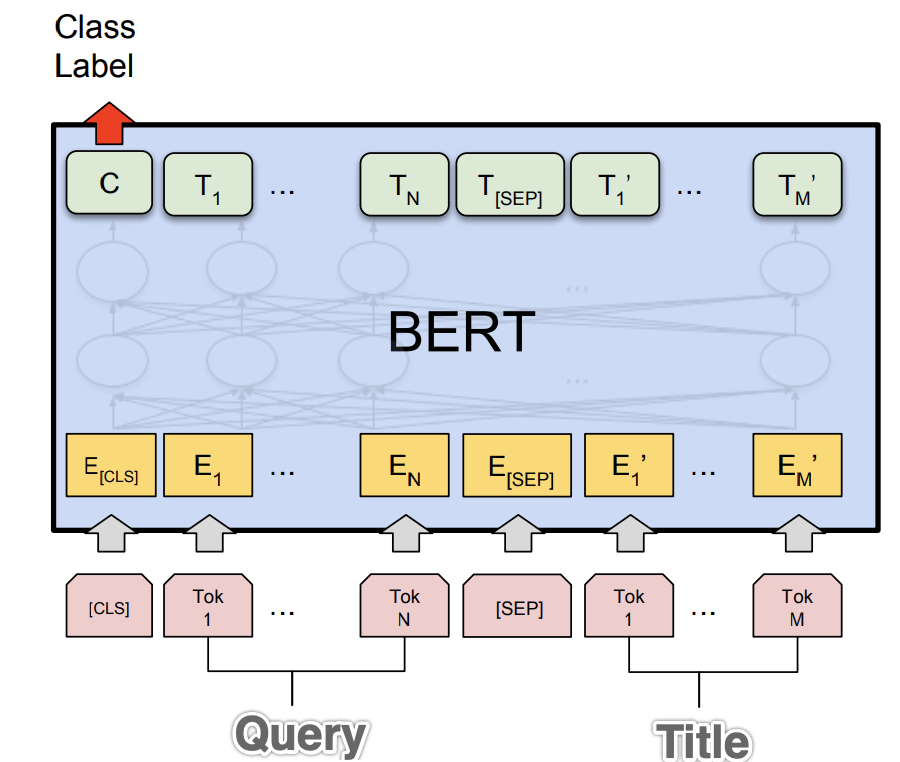
我们尝试将 Bert 模型应用在 query-title 分档任务上,将 query 和 title 作为句对输入到 bert 中,取最后一层 cls 向量用做 5 分类(如上图),最后得到的结果比 LSTM-Attention 交互式匹配模型要好。虽然知道了 bert能解决这个问题,我们更好奇的是"为什么":为什么 bert 的表现能这么好?这里面有没有可解释的部分呢?
因为 Multi-head-attention 是 bert 的主要组成部分,所以我们从"头"入手,希望弄清楚各个 head 对 bert 模型有什么作用。为了研究某个 head 对模型的影响,我们需要比较有这个 head 和没有这个 head 模型的前后表现。这里定义一下 HEAD-MASK 操作,其实就是针对某个 head,直接将这个 head 的 attention 值置成 0,这样对于任何输入这个 head 都只能输出 0 向量。
通过 HEAD-MASK 操作对各个 head 进行对比实验,发现了下面几个有趣的点
- attention-head 很冗余/鲁棒,去掉 20%的 head 模型不受影响
- 各层 transformer 之间不是串行关系,去掉一整层 attention-head 对下层影响不大
- 各个 head 有固定的功能
- 某些 head 负责分词
- 某些 head 提取语序关系
- 某些 head 负责提取 query-title 之间 term 匹配关系
下面我们开始实验正文,看看这些结论是怎么得到的
二、Bert 模型 Attention-Head 实验
attention-head 是 bert 的基本组成模块,本次实验想要研究各个 head 都对模型作出了什么贡献。通过 Mask 掉某个 head,对比模型前后表现的差异来研究这个 head 对模型有什么样的作用(对训练好的 bert 做 head-mask,不重新训练,对比测试集的表现)。
bert-base 模型共 12 层每层有 12 个 head,下面实验各个 head 提取的特征是否有明显的模式(Bert 模型为在 query-title 数据上 finetune 好的中文字模型)
2.1 Attention-Head 比较冗余
标准大小的 bert 一共有 12*12 共 144 个 head.我们尝试对训练好的 bert 模型,随机 mask 掉一定比例的 head,再在测试数据集上测试分档的准确率(五分类)。
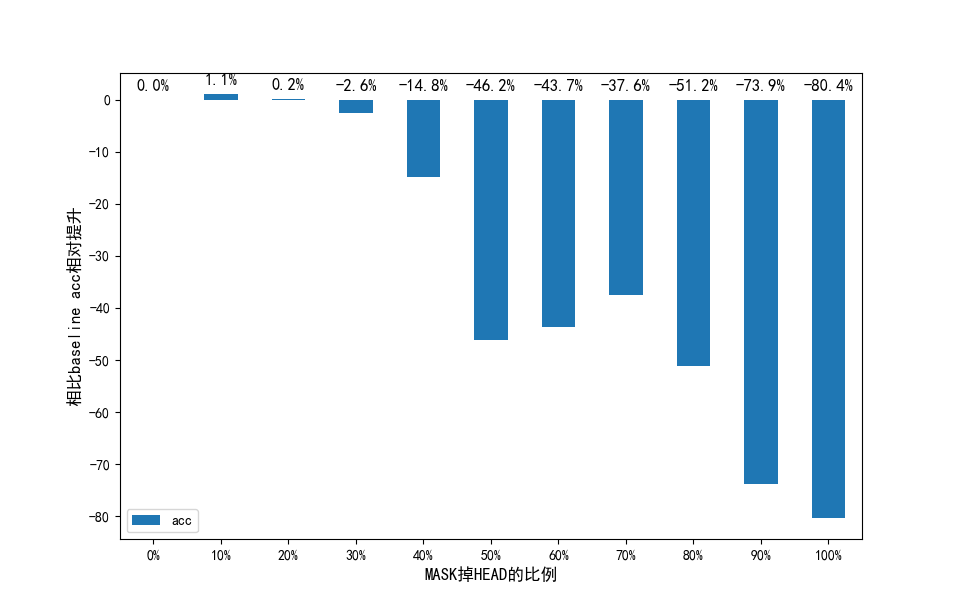
下图的柱状图的数值表示相比于 bseline(也就是不做任何 head-mask)模型 acc 的相对提升,如+1%表示比 baseline 模型的 acc 相对提高了 1%,从下面的图可以看到,随机 mask 掉低于 20%的 head,在测试数据集上模型的 acc 不会降低,甚至当 mask 掉 10%的 head 的时候模型表现比不做 head mask 的时候还提升了 1%。当 mask 掉超过一定数量的 head 后,模型表现持续下降,mask 掉越多表现越差。

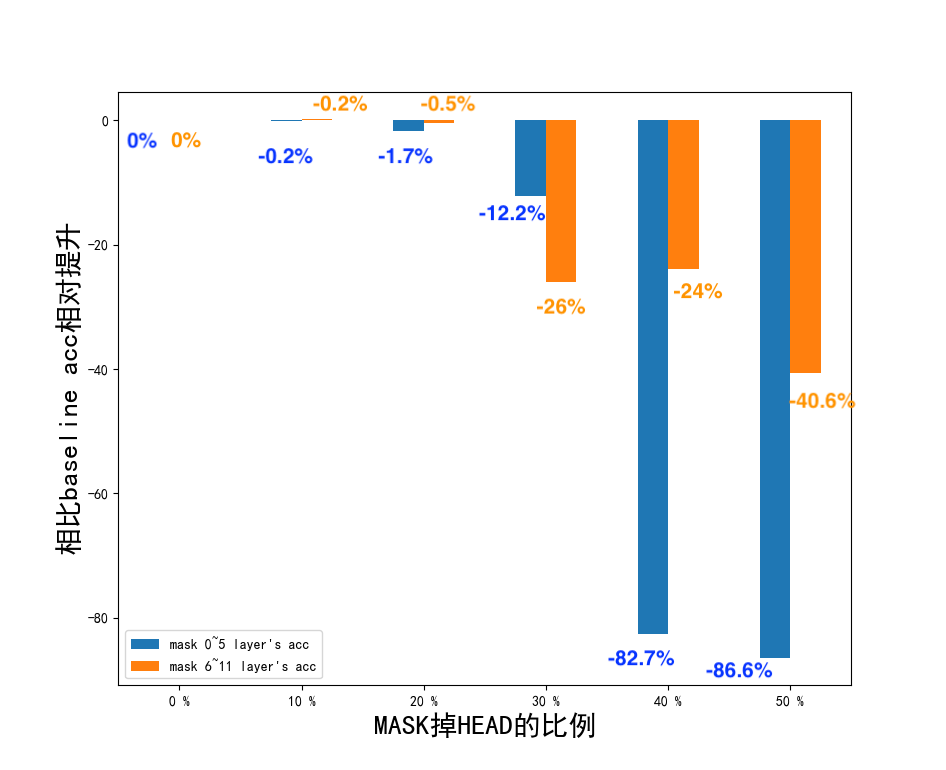
同时为了弄清楚底层和高层的 transformer 哪个对于 query-title 分类更加的重要,分别对底层(layer0 ~ layer5 )和高层(layer6~layer11)的 head 做 mask, 去掉的 head 比例控制在 0~50%(占总 head 数量)之间,50%表示去掉了底层或者是高层 100%的 head 下面的图很清晰的说明了底层和高层的 attention-head 关系,橙色部分表示只 mask 掉高层(6 - 11 层)的 head,蓝色部分表示只 mask 掉底层(0 - 5 层)的 head。
显然高层的 attention-head 非常的依赖底层的 head,底层的 attention-head 负责提取输入文本的各种特征,而高层的 attention 负责将这些特征结合起来。具体表现在当 mask 掉底层(0~5 层)的 80%的 head(图中横坐标为 40%)和 mask 掉底层的 100%的 head(图中横坐标为 50%)时,模型在测试数据集上表现下降剧烈(图中蓝色部分),说明了去掉大部分的底层 head 后只依赖高层的 head 是不行的,高层的 head 并没有提取输入的特征。相反去掉大部分高层的 head 后模型下降的并没有那么剧烈(图中橙色部分),说明了底层的 head 提取到了很多对于本任务有用的输入特征,这部分特征通过残差连接可以直接传导到最后一层用做分类。

这个结论后面也可以用于指导模型蒸馏,实验结果表明底层的 transformer 比高层的 transformer 更加的重要,显然我们在蒸馏模型时需要保留更多的底层的 head
那么对于模型来说是否有某些层的 head 特别能影响 query-title 分类呢?假设将 bert 中所有的 attention-head 看做一个 12*12 的方阵,下面是按行 mask 掉一整行 head 后模型在测试数据上的表现,柱状图上的数值表示相比 baseline 模型的相对提升。


可以看到 mask 掉第 5 层~第 9 层的 head 都模型都有比较大的正面提升,特别是当去掉整个第 8 层的 attention-head 的时候测试数据准确率相对提升了 2.3%,从上图可以得到两个结论:
- Bert 模型非常的健壮或者是冗余度很高
- Bert 模型各层之间不是串行依赖的关系,信息并不是通过一层一层 transformer 层来传递的
bert 模型非常的健壮或者是冗余度很高,直接去掉一整层的 attention-head 并不会对模型的最终表现有太大的影响。 直接去掉整层的 attention-head 模型表现并没有大幅度的下降,说明各层提取的特征信息并不是一层一层的串行传递到分类器的,而是通过残差连接直接传导到对应的层。
2.2 某些 head 负责判断词的边界(使得字模型带有分词信息)
在我们的 query-title 分档场景中,发现词粒度的 bert 和字粒度的 bert 最终的表现是差不多的,而对于 rnn 模型来说字粒度的 rnn 很难达到词粒度 rnn 的效果,我们希望研究一下为什么词粒度和字粒度的 bert 表现差不多。
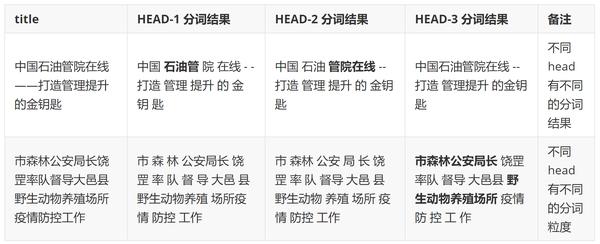
使用的 bert 可视化工具bert_viz^{[2]}观察各层 attention-head 的 attention 权重分布,可以发现某些 head 带有很明显的分词信息。推测这部分 attention-head 是专门用于提取分词信息的 head。当当前的字可能是词的结尾时,att 权重会偏向 sep,当这个字为词的结尾可能性越大(常见的词结尾),sep 的权重会越高。当当前字不是词结尾时,att 会指向下一个字。这种模式非常明显,直接拿这个 attention-head 的结果用于分词准确率为 70%。
下面 gif 为我们模型中第 1 层第 3 个 head 的 attention 分布权重图,可以发现 attention 权重很明显带有词的边界信息,当当前的字是结尾时 attention 权重最大的 token 为"SEP",若当前字不是结尾时 attention 权重最大的为下一个字。

这种用于提取分词信息的 head 有很多,且不同的 head 有不同的分词粒度,如果将多个粒度的分词综合考虑(有一个 head 分词正确就行),则直接用 attention-head 切词的准确率在 96%,这也是为什么词粒度 bert 和字粒度 bert 表现差不多的原因。

猜测字粒度 bert 带词边界信息是通过 bert 的预训练任务 MLM 带来的,语言模型的训练使得 bert 对各个字之间的组合非常的敏感,从而能够区分词的边界信息。
2.3 某些 head 负责编码输入的顺序
我们知道 bert 的输入为 token_emb+pos_emb+seg_type_emb 这三个部分相加而成,而文本输入的顺序完全是用 pos_emb 来隐式的表达。bert 中某些 head 实际上负责提取输入中的位置信息。这种 attention-head 有明显的上下对齐的模式,如下图:


原输入: query="京东小哥", title="京东小哥最近在干嘛",bert 模型判定为 4 档
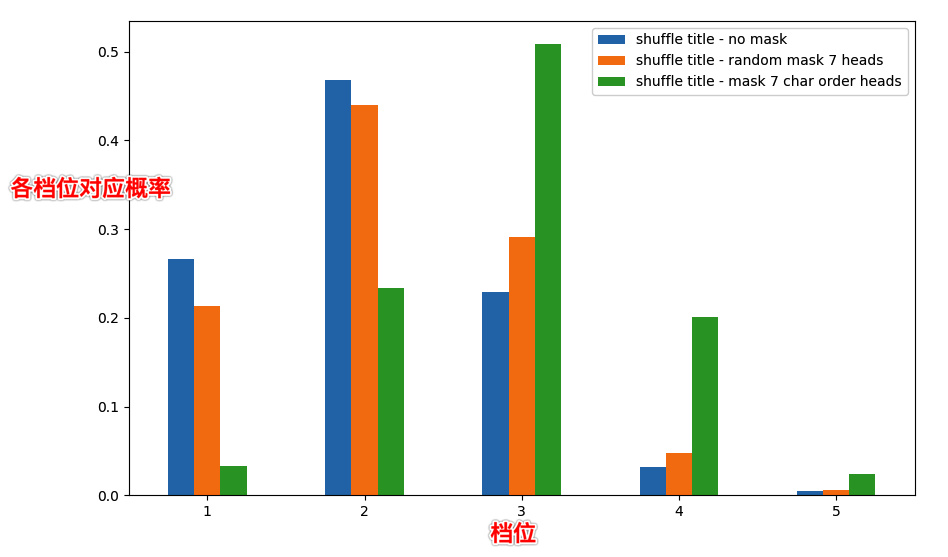
将 title 顺序打乱: query="京东小哥", title="近东嘛最都在干哥小京",bert 模型判定为2 档 将 title 顺序打乱: query="京东小哥", title="近东嘛最都在干哥小京",mask 掉 7 个怀疑用于提取语序的 head,bert 模型判定为3 档
下面的图分别对比了不做 mask,随机 mask 掉 7 个 head(重复 100 次取平均值),mask 掉 7 个特定的 head(怀疑带有语序信息的 head) 从下面的图看到,mask 掉 7 个特定的 head 后整体分档提升为 3 档,而随机 mask 掉 7 个 head 结果仍然为 2 档,且档位概率分布和不 mask 的情况差别不大。
这个 case 说明了我们 mask 掉的 7 个特定的 head 应该是负责提取输入的顺序信息,也就是语序信息。将这部分 head mask 掉后,bert 表现比较难察觉到 title 中的乱序,从而提升了分档。

2.4 某些 head 负责 query 和 title 中相同部分的 term 匹配
query 和 title 中是否有相同的 term 是我们的分类任务中非常关键的特征,假如 query 中大部分 term 都能在 title 中找到,则 query 和 title 相关性一般比较高。如 query="京东小哥"就能完全在 title="京东小哥最近在干嘛"中找到,两者的文本相关性也很高。我们发现部分 attention-head 负责提取这种 term 匹配特征,这种 head 的 attention 权重分布一般如下图,可以看到上句和下句中相同 term 的权重很高(颜色越深表示权重越大)。


其中在第 2~第 4 层有 5 个 head 匹配的模式特别明显。我们发现虽然 bert 模型中 attention-head 很冗余,去掉一些 head 对模型不会有太大的影响,但是有少部分 head 对模型非常重要,下面展示这 5 个 head 对模型的影响,表格中的数值表示与 baseline 模型的 acc 相对提升值。
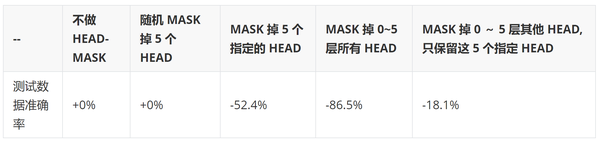

利用测试数据作为标准,分别测试随机 mask 掉 5 个 head 和 mask 掉 5 个指定的 head(这些 head 在 attention 可视化上都有明显的 query-title 匹配的模式)。从结果可以看到去掉这些负责 query-title 匹配的 head 后模型表现剧烈下降,只去掉这 5 个 head 就能让模型表现下降 50%。甚至 mask 掉 0~5 层其他 head,只保留这 5 个 head 时模型仍维持 baseline 模型 82%的表现,说明了 query-title 的 term 匹配在我们的任务中是非常重要的。
这也许是为什么双塔 bert 在我们的场景下表现会那么差的原因(Bert+LSTM 实验中两个模型结合最后的表现差于只使用 Bert, Bert 的输入为双塔输入),因为 query 和 title 分别输入,使得这些 head 没有办法提取 term 的匹配特征(相当于 mask 掉了这些 head),而这些匹配特征对于我们的分类任务是至关重要的
2.4.1 finetune 对于负责 term 匹配 attention-head 的影响
在 query-title 分档任务中 query 和 title 中是否有相同的 term 是很重要的特征,那么在 finetune 过程中负责 query-title 中相同 term 匹配的 head 是否有比较明显的增强呢?
下面以 case 为例说明: query="我在伊朗长大" title="假期电影《我在伊朗长大》"
下图展示了 query-title 数据***finetune 前*****某个**负责 term 匹配的 head 的 attention 分配图


在没有 finetune 前,可以看到某些 head 也会对上下句中重复的 term 分配比较大的 attention 值,这个特质可能是来自预训练任务 NSP(上下句预测)。因为假如上句和下句有出现相同的 term,则它们是上下句的概率比较大,所以 bert 有一些 head 专门负责提取这种匹配的信息。
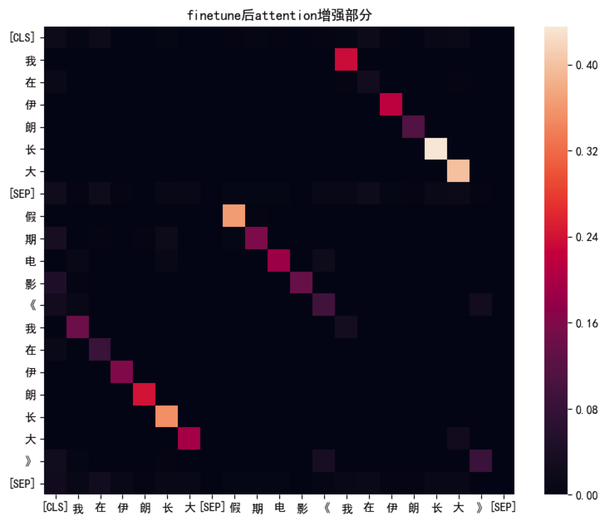
除了上下句相同的 term 有比较大的注意力,每个 term 对自身也有比较大的注意力权重(体现在图中对角线上的值都比较大) 为了更直观的看训练前后哪部分的 attention 值有比较大的改变,分别展示训练后 attention增强(微调前-微调后>0)和训练后 attention减弱(微调前-微调后<0)的 attention 分配图。可以观察到比较明显的几个点:
- query 和 title 中 term 匹配的 attention 值变大了 从下图可以看到, query 和 title 中具有相同 term 时 attention 相比于训练前是有比较大的增强。说明在下游任务(query-title 分档)训练中增强了这个 head 的相同 term 匹配信息的抽取能力。

- term 和自身的 attention 变小了 模型将重点放在找 query 和 title 中是否有相同的 term,弱化了 term 对自身的注意力权重
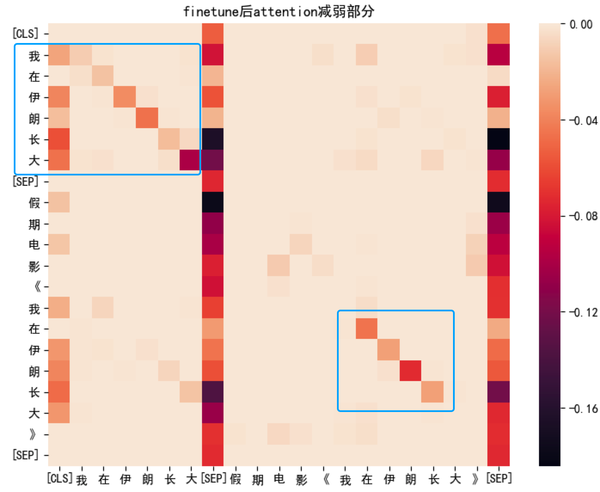

- 分隔符 sep 的 attention 值变小了。 有论文指出当某个 token 的 attention 指向 sep 时表示一种不分配的状态(即此时没有找到合适的 attention 分配方式),在经过 finetune 后 term 指向 sep 的权重变小了,表示经过 query-title 数据训练后这个 head 的 attention 分配更加的明确了。
2.4.2 是否有某个 head 特别能影响模型
从上面的实验可以看到,bert 模型有比较多冗余的 head。去掉一部分这些 head 并不太影响模型,但是有少部分 head 特别能影响模型如上面提到的负责提取上下句中 term 匹配信息的 head,只去掉 5 个这种 head 就能让模型的表现下降 50%。那么是否有某个 head 特别能影响结果呢?
下面实验每次只 mask 掉一个 head,看模型在测试数据中表现是否上升/下降。下图中将 bert 的 144 个 head 看作 12X12 的矩阵,矩阵内每个元素表示去掉这个 head 后模型在测试数据上的表现。其中 0 表示去掉后对模型的影响不太大。元素内的值表示相对于 baseline 的表现提升,如+1%表示相比 baseline 的 acc 提高了 1%。


可以看到对于 bert 的大部分 head,单独去掉这个 head 对模型并不会造成太大的影响,而有少部分 head 确实特别能影响模型,比如负责上下句(query-title)中相同 term 匹配的 head。即使去掉一个这种 head 也会使得模型的表现下降。同时注意到高层(第 10 层)有一个 head 去掉后模型表现变化也很大,实验发现这个 head 功能是负责抽取底层 head 输出的特征,也就是 3-4 层中 head 抽取到输入的 query-title 有哪些相同 term 特征后,这部分信息会传递到第 10 层进一步进行提取,最后影响分类。
2.4.3 高层 head 是如何提取底层 head 特征-一个典型 case
上图中,在第 10 层有一个 head 去掉后特别能影响模型,观察其 attention 的分布,cls 的 attention 都集中在 query 和 title 中相同的 term 上,似乎是在对底层 term 匹配 head 抽取到的特征进一步的提取,将这种匹配特征保存到 cls 中(cls 最后一层会用于分类)。


在没有做任何 head-mask 时, 可以看到 cls 的 attention 主要分配给和 query 和 title 中的共同 term "紫熨斗",而 mask 掉 5 个 2~4 层的 head(具有 term 匹配功能)时, 第 10 层的 cls 注意力分配明显被改变,分散到更多的 term 中。


这个 case 展示了高层 attention-head 是如何依赖底层的 head 的特征,进一步提取底层的特征并最后作为重要特征用于 query-title 分类。
结语
本文主要探讨了在 query-title 分类场景下,bert 模型的可解释性。主要从 attention-head 角度入手,发现 attention 一方面非常的冗余,去掉一部分 head 其实不会对模型造成多大的影响。另外一方面有一些 head 却非常的能影响模型,即使去掉一个都能让模型表现变差不少。同时发现不同的 head 实际上有特定的功能,比如底层的 head 负责对输入进行特征提取,如分词、提取输入的语序关系、提取 query 和 title(也就是上下句)中相同的 term 信息等。这部分底层的 head 提取到的特征会通过残差连接送到高层的 head 中,高层 head 会对这部分特征信息进行进一步融合,最终作为分类特征输入到分类器中。
本文重点讨论了哪些 head 是对模型有正面作用,也就是去掉这些 head 后模型表现变差了。但是如果知道了哪些 head 为什么对模型有负面作用,也就是为什么去掉某些 head 模型效果会更好,实际上对于我们有更多的指导作用。这部分信息能够帮助我们在模型加速,提升模型表现上少走弯路。
参考文献
[1] Clark K, Khandelwal U, Levy O, et al. What Does BERT Look At? An Analysis of BERT's Attention[J]. arXiv preprint arXiv:1906.04341, 2019.
[2] Vig J. A multiscale visualization of attention in the transformer model[J]. arXiv preprint arXiv:1906.05714, 2019.
作者:vincehou,腾讯 TEG 应用研究员
更多干货尽在腾讯技术,官方QQ交流群已建立,交流讨论可加:957411539。
