
用于时间序列预测的深度Transformer模型:流感流行病例

用于时间序列预测的深度Transformer模型:流感流行病例
题目:
Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case
作者:
Neo Wu, Bradley Green, Xue Ben, Shawn O'Banion
来源:
Machine Learning
Submitted on 23 Jan 2020
文档链接:
https://arxiv.org/pdf/2001.08317v1.pdf
摘要
本文提出了一种时间序列预测的新方法。时间序列数据普遍存在于许多科学和工程学科中。时间序列预测是时间序列数据建模中的一项重要任务,也是机器学习的一个重要领域。在这项工作中,我们开发了一种新的方法,使用基于Transformer的机器学习模型来预测时间序列数据。这种方法利用自我注意机制从时间序列数据中学习复杂的模式和动态。此外,它是一个通用的框架,可以应用于单变量和多变量时间序列数据,以及时间序列嵌入。使用流感样疾病(ILI)预测作为案例研究,我们表明,我们的方法产生的预测结果可以与最新的预测结果相媲美。
英文原文
In this paper, we present a new approach to time series forecasting. Time series data are prevalent in many scientific and engineering disciplines. Time series forecasting is a crucial task in modeling time series data, and is an important area of machine learning. In this work we developed a novel method that employs Transformer-based machine learning models to forecast time series data. This approach works by leveraging self-attention mechanisms to learn complex patterns and dynamics from time series data. Moreover, it is a generic framework and can be applied to univariate and multivariate time series data, as well as time series embeddings. Using influenza-like illness (ILI) forecasting as a case study, we show that the forecasting results produced by our approach are favorably comparable to the state-of-the-art.
基于Transformer的预测模型体系结构。
具体来说,我们的贡献如下:
- 我们开发了一个通用的基于转换器的时间序列预测模型。
- 我们证明了我们的方法是对状态空间模型的补充。它可以模拟观测数据。使用嵌入作为代理,我们的方法也可以建模状态变量和系统的相空间。
- 以ILI预测为例,我们证明了基于转换者的模型能够利用各种特征准确预测ILI流行率。
- 我们证明,在ILI案例中,我们的基于变压器的模型能够获得最先进的预测结果。
我们基于转换器的ILI预测模型遵循原始的Transformer架构(Vaswani et al., 2017),包括编码器和解码器层。
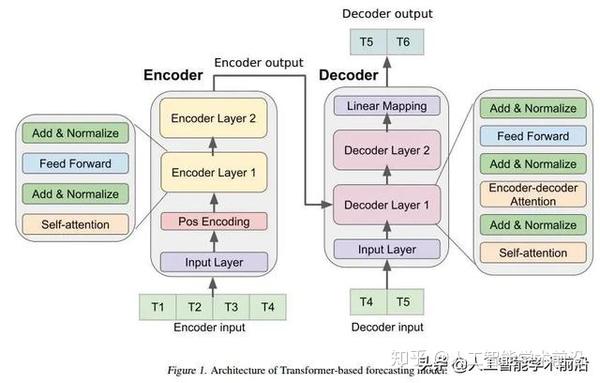

Encoder:编码器由输入层,位置编码层和四个相同的编码器层的堆栈组成。输入层通过完全连接的网络将输入时间序列数据映射到维dmodel的向量。这一步对于模型采用多头注意力机制至关重要。通过将输入向量与位置编码向量逐元素相加,可使用具有正弦和余弦函数的位置编码对时间序列数据中的顺序信息进行编码。所得的向量被馈送到四个编码器层。每个编码器层都包含两个子层:一个自我注意子层和一个完全连接的前馈子层。每个子层之后是归一化层。编码器生成dmodel维向量,以馈送到解码器。
Decoder:我们采用类似于原始Transformer架构的解码器设计(Vaswani et al。,2017)。解码器还由输入层,四个相同的解码器层和输出层组成。解码器输入从编码器输入的最后一个数据点开始。输入层将解码器输入映射到dmodel维向量。除了每个编码器层中的两个子层之外,解码器还插入一个第三子层,以在编码器输出上应用自我关注机制。最后,有一个输出层,它将最后一个解码器层的输出映射到目标时间序列。我们在解码器的输入和目标输出之间采用了预视掩蔽和一位置偏移,以确保对时序数据点的预测仅取决于先前的数据点。
实验结果
数据集
我们利用了CDC(CDC)从2010年到2018年的国家和州级别的ILI历史数据。
实验结果分析
我们将结果与ARGONet的ILI预测数据进行了比较(Lu等,2019),这是文献中最先进的ILI预测模型。图6和图7显示了ARGONet的相关性和RMSE值以及我们的变压器结果。总体而言,基于Transformer的模型与ARGONet的性能相同,平均相关性略有改善(ARGONet:0.912,Transformer:0.931),平均RMSE值略有下降(ARGONet:0.550,Transformer:0.593)
图6:ARGONet和transformer模型的皮尔逊相关。
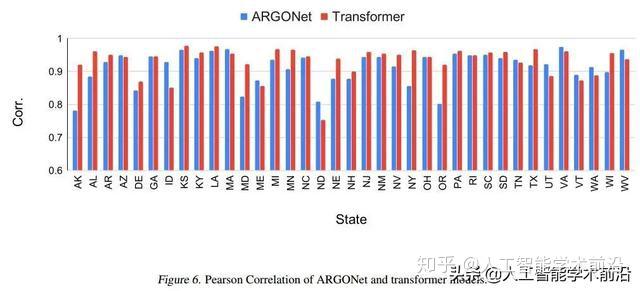

图7:ARGONet和transformer模型的RMSE。
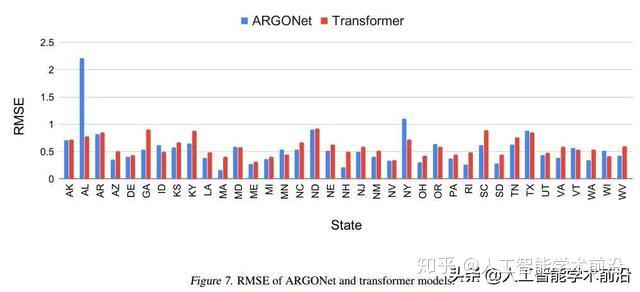

表1.与基准模型相对变化的模型性能摘要


在三种深度学习方法中,相关系数非常相似,基于transformer的模型略高于LSTM和Seq2Seq的注意模型。在RMSE方面,Transformer模型优于attention模型的LSTM和Seq2Seq,相对RMSE分别下降27%和8.4%。
该分析表明,注意机制有助于预测性能,因为带有注意和变压器的Seq2Seq模型优于普通的LSTM模型。
此外,变压器比Seq2Seq具有更好的预测性能,说明变压器的自注意机制比Seq2Seq使用的线性注意机制能更好地捕捉数据中的复杂动态模式。
结论
在这项工作中,我们提出了一种基于变压器的方法来预测时间序列数据。与其他序列对齐的深度学习方法相比,我们的方法利用自我注意力机制对序列数据进行建模,因此可以从时间序列数据中学习各种长度的复杂依赖关系。
而且,这种基于变压器的方法是用于对各种非线性动力学系统进行建模的通用框架。如ILI案例所示,此方法可以通过时间延迟嵌入对观察到的时间序列数据以及状态变量的相空间进行建模。它也是可扩展的,可用于对单变量和多变量时间序列数据进行建模,而对模型实现的修改最少。
最后,尽管当前的案例研究集中在时间序列数据上,但我们假设我们的方法可以进一步扩展为对由时间和位置坐标索引的时空数据进行建模。自我注意机制可以概括为学习时空空间中两个任意点之间的关系。这是我们计划将来探索的方向。