
ECCV2020 | 拓扑保持类增量学习 | TPCIL

本文提出了基于拓扑保持的类增量学习方法TPCIL。主要发现与技术贡献如下:
- 通过实验发现了知识蒸馏方法在解决遗忘问题时的”从头学起“现象;
- 建立了基于赫布竞争学习的通用图模型构建方式,可以涵盖之前自组织神经网络SOM(aaai文章链接)和神经气体Neural Gas(CVPR文章链接+知乎);
- 引入基于保持历史样本距离排序(近似)的正则化方式,比之前基于绝对距离保持的正则化方式更为有效。
文章作者:陶小语、常新远、洪晓鹏、魏星、龚怡宏
文章简介:
神经网络一般由固定的数据类别中训练得到分类结果,但实际应用中,允许模型增量地扩展并从新类的数据中学习是至关重要的,即类增量学习(class-incremental learning ,CIL)。CIL目的是在不遗忘旧类别的基础上学习新类别,进而构建一个统一的分类器。学习新类别时不利用旧类别的数据。直接在新类数据上微调(directly finetune)模型会导致旧类的灾难性遗忘(catastrophic forgetting),而利用知识蒸馏方法(knowledge distillation)会导致新旧类别不平衡的问题。并且在我们的实验中发现,知识蒸馏方法似乎是先遗忘了旧类,再从旧类部分样本数据中重新学习,即”从头学习(start-all-over)“(见图1)。这样需要额外训练更多轮,并很容易过拟合旧类的样本数据。
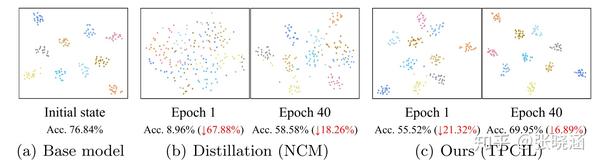

为此,我们提出了人脑启发的拓扑保持类增量学习模型。研究表明,人脑知识的遗忘是由视觉工作记忆的拓扑结构被破坏引起的;类似地,对于深层神经网络学习新类时,随着学习特征空间拓扑结构的破坏,也会出现灾难性遗忘现象。因此,我们保持CNN学习到的特征空间的拓扑结构来减少遗忘。利用赫布竞争学习(competitive Hebbian learning,CHL)构建弹性赫布图(elastic Hebbian graph,EHG)来建立特征空间的拓扑结构。在学习新类时,我们在EHG上引入拓扑保持损失(topology-preserving loss,TPL)对EHG表示的拓扑连接的变化进行惩罚。
拓扑保持类增量学习(TPCIL):
CNN增量地从一系列训练数据 X^1,X^2,...,X^{t},X^{t+1},..., 中学习参数 \theta ,其中 t+1 的模型只从 X^{t+1} 中学习 \theta^{t+1} 。令 G_t 表示session t 所构造的EHG,定义session t + 1 的总损失函数为 \ell(X^{t+1}, G^t; θ^{t+1}) = \ell_{CE}(X^{t+1}, G^t; θ^{t+1}) + λ \ell_{TPL}(G^t; θ^{t+1}) 。其中, \ell_{CE} 是标准的交叉熵损失 \ell_{CE}(X^{t+1}, G^t; θ^{t+1})=\sum_{(x,y)}{-\log \hat{p_y}(x)} 。
EHG可以被定义为无向图 G=<V,E> ,其中 V 是N个归一化特征空间的集合, E 是描述 V 中顶点的邻域关系的边集。模型更新过程如下:首先,随机选取N个点来初始化EHG。通过赫布竞争学习(CHL),将特征空间分成N个不相交的Voronoi单元,每个单元由一个顶点编码。相邻关系用顶点之间的连接来描述。然后,TPL项强制EHG维护顶点之间的关系。在学习了新的类之后,EHG通过插入新的顶点来扩展拓扑结构。最后由CHL更新所有的顶点,并在其中重新计算相似度。拓扑保持机制的可视化见图2。
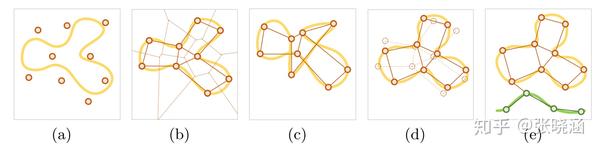

我们提出的TPCIL集成了一个CNN模型和一个EHG G^t ,其中 G^t 用来保持CNN的特征空间流形的拓扑。值得注意的是,CNN模型是用小批量梯度下降 (minibatch SGD)算法训练的,而 G^t 是用赫布竞争学习(CHL)算法构造和更新的。我们在训练了CNN的参数 \theta^t 后学习了G^t,然后用于下一个session的学习。
实验:
TPCIL与其他CIL方法的对比结果如图3所示。每条曲线都表示了每一阶段测试准确度的变化。绿色曲线为基线Ft-CNN,黄色曲线为上界Joint-CNN。橙色曲线表示TPCIL实现的精度,青色曲线、蓝色曲线和紫色曲线分别表示NCM、iCARL和EEIL的精度。对于所有数据集上的5和10个sessions进行训练,TPCIL方法性能大大优于其他CIL方法,并且是最接近上限(联合训练)方法的。
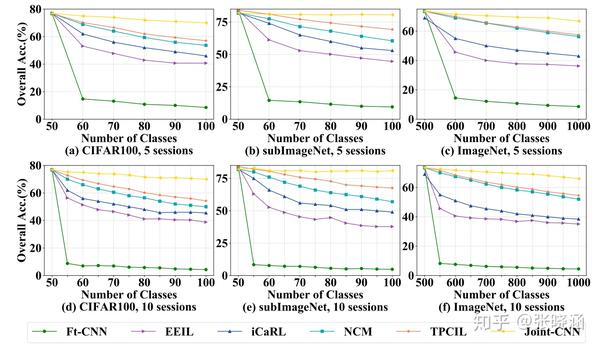

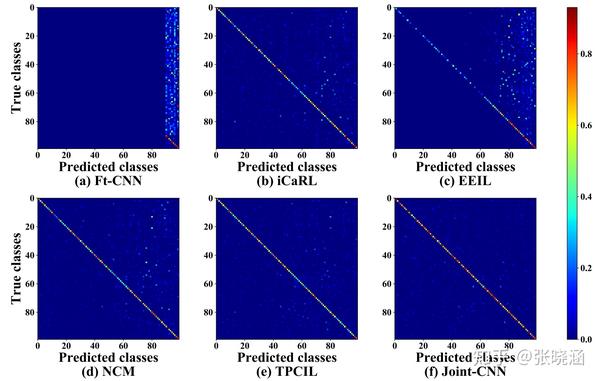
图4展示了不同方法的混淆矩阵在5个sessions设置下对CIFAR100的比较。横轴表示预测的类,而垂直轴是ground-truth类。右边的颜色条表示不同颜色对应的激活强度。我们的TPCIL (e)产生了一个更好的混淆矩阵,这是最接近联合cnn (f)上限的方法。

小结:
这项工作的重点是从一个新的、人脑认知启发的观点解决CIL任务灾难性遗忘问题。我们提出通过保持特征空间的拓扑结构来保留旧类知识。利用TPCIL方法,用EHG图来建模特征空间流形的拓扑,并使用TPL项来约束EHG,以惩罚拓扑的变化。大量的实验表明,所提出的TPCIL大大优于最先进的CIL方法。
论文引用信息:
Xiaoyu Tao, Xinyuan Chang, Xiaopeng Hong, Xing Wei and Yihong Gong. “Topology-Preserving Class-Incremental Learning.”Proceedings of the Europeon Conference on Computer Vision, ECCV, 2020.
BibTex:
@inproceedings{tao2020tpcil, title={Topology-Preserving Class-Incremental Learning}, author={Tao, Xiaoyu and Chang, Xinyuan and Hong, Xiaopeng and Wei, Xing and Gong, Yihong}, booktitle={Proceedings of the Europeon Conference on Computer Vision}, year={2020} }
主要参考文献:
[1]Martinetz, T.M.: Competitive hebbian learning rule forms perfectly topology pre- serving maps. In: International Conference on Artificial Neural Networks. (1993) 427–434.
[2]Martinetz, T., Schulten, K.: Topology representing networks. Neural Networks 7(3) (1994) 507–522.
[3]Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: icarl: Incremental classifier and representation learning. In: CVPR. (2017) 2001–2010.
[4]Castro, F.M., Mar´ın-Jim´enez, M.J., Guil, N., Schmid, C., Alahari, K.: End-to-end incremental learning. In: ECCV. (2018) 233–248.
[5]Hou, S., Pan, X., Loy, C.C., Wang, Z., Lin, D.: Learning a unified classifier incre mentally via rebalancing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2019) 831–839.
中文文字:张晓涵

