
人工智能-GPT-3

OpenAI在最近, 新提出的 GPT-3 在网络媒体上引起啦的热议。因为它的参数量要比 2 月份刚刚推出的、全球最大深度学习模型 Turing NLP 大上十倍,而且不仅可以更好地答题、翻译、写文章,还带有一些数学计算的能力。这样强大的深度学习,不禁让人产生一种错觉:真正的 AI 要来了吗?
OpenAI的一组研究人员最近发表了一篇论文,描述了GPT-3,这是一种具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍。该模型经过了将近0.5万亿个单词的预训练,并且在不进行微调的情况下,可以在多个NLP基准上达到最先进的性能。


由30多位合著者组成的团队描述了该模型和几个实验。
研究人员的目标是生产一种NLP系统,该系统可以很好地执行各种任务,而几乎不需要微调,并且以前的工作表明较大的模型可能是解决方案。
为了检验该假设,研究小组将其先前模型GPT-2的大小从15亿个参数增加到1750亿个。为了进行培训,团队收集了几个数据集,包括Common Crawl数据集和英语Wikipedia。

首先,GPT-3 最令人惊讶的还是模型体量,它使用的最大数据集在处理前容量达到了 45TB。根据 OpenAI 的算力统计单位 petaflops/s-days,训练 AlphaGoZero 需要 1800-2000pfs-day,而 OpenAI 刚刚提出的 GPT-3 用了 3640pfs-day。
研究者们希望 GPT-3 能够成为更通用化的 NLP 模型,解决当前 BERT 等模型的两个不足之处:对领域内有标记数据的过分依赖,以及对于领域数据分布的过拟合。GPT-3 致力于能够使用更少的特定领域,不做 fine-tuning 解决问题。
项目页面(目前没有代码只有生成样本和数据)和论文
paper链接:https://arxiv.org/abs/2005.14165
github链接:https://github.com/openai/gpt-3
2019 年初,OpenAI 发布了通用语言模型 GPT-2,能够生成连贯的文本段落,在许多语言建模基准上取得了 SOTA 性能。这一基于 Transformer 的大型语言模型共包含 15 亿参数、在一个 800 万网页数据集上训练而成。GPT-2 是对 GPT 模型的直接扩展,在超出 10 倍的数据量上进行训练,参数量也多出了 10 倍。
然而OpenAI 发布 GPT-3 模型,1750 亿参数量,足足是 GPT-2 的 116 倍。
GPT-3 在许多 NLP 数据集上均具有出色的性能,包括翻译、问答和文本填空任务,这还包括一些需要即时推理或领域适应的任务,例如给一句话中的单词替换成同义词,或执行 3 位数的数学运算。
GPT-3新闻生成,GPT-3生成的新闻我们很难将机器写的和人类写的区分。
-----------------------------------------------------------------------------------------------
据《华盛顿邮报》报道,经过两天的激烈辩论,联合卫理公会同意了一次历史性的分裂:要么创立新教派,要么则在神学和社会意义上走向保守。大部分参加五月份教会年度会议的代表投票赞成加强任命 LGBTQ 神职人员的禁令,并制定新的规则「惩戒」主持同性婚礼的神职人员。但是反对这些措施的人有一个新计划:2020 年他们将形成一个新教派「基督教卫理公会」。
《华盛顿邮报》指出,联合卫理公会是一个自称拥有 1250 万会员的组织,在 20 世纪初期是「美国最大的新教教派」,但是近几十年来它一直在萎缩。这次新的分裂将是该教会历史上的第二次分裂。第一次发生在 1968 年,当时大概只剩下 10% 的成员组成了「福音联合弟兄会」。《华盛顿邮报》指出,目前提出的分裂「对于多年来成员不断流失的联合卫理公会而言,来得正是时候」,这「在 LGBTQ 角色问题上将该教派推向了分裂边缘」。同性婚姻并不是分裂该教会的唯一问题。2016 年,该教派因跨性别神职人员的任命而分裂。北太平洋地区会议投票禁止他们担任神职人员,而南太平洋地区会议投票允许他们担任神职人员。


在 OpenAI 的测试中,人类评估人员也很难判断出这篇新闻的真假,检测准确率仅为 12%为机器编写。
根据 OpenAI 统计出来的数据;人类对 GPT-3 175B 模型生成的约 500 词文章的判断准确率为 52%,不过相比于 GPT-3 control 模型(没有语境和不断增加的输出随机性且只具备 1.6 亿参数的模型),GPT-3 175B 生成的文本质量要高得多。果然很暴力啊!


GPT-3 的造句能力
给出一个新单词及其定义,造出一个新句子。
OpenAI 研究者测试了 GPT-3 在这一任务上的能力:给出一个不存在的单词(如「Gigamuru」),令 GPT-3 使用它造句。
我们来看 GPT-3 的生成结果:


给出新单词「Gigamuru」(一种乐器)。
GPT-3 输出的数据:叔叔送了我一把 Gigamuru,我喜欢在家弹奏它。
再看一个动词例子:


给出新单词「screeg」(挥剑,击剑)。
GPT-3 输出的数据:我们玩了几分钟击剑,然后出门吃冰淇淋。
GPT-3语法纠错
给出一句带有语法错误的话,让 GPT-3 进行修改。




第一个例子中,原句里有两个并列的动词「was」和「died」,GPT-3 删除系动词「was」,将其修改为正确的句子。
第二个例子中,原句里 likes 后的 ourselves 是 we 的反身代词,而这里 like 这一动作的执行者是 Leslie,因此 likes 后即使要用反身代词,也应该是 himself,而另一个改法是将反身代词改成 we 的宾格 us,即「我们认为 Leslie 喜欢我们」。
GPT-3 做计算
GPT-3 可以执行简单的计算。
OpenAI 研究人员在以下 10 项任务中测试了 GPT-3 做简单计算的能力。
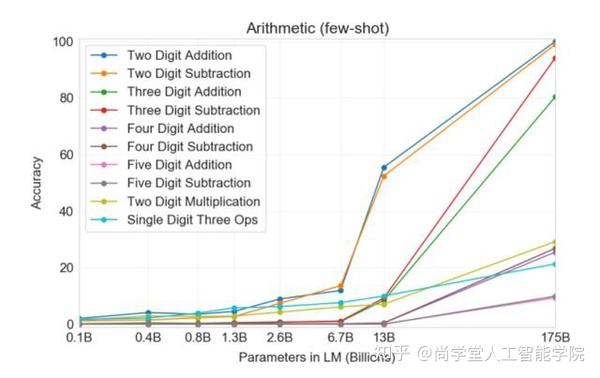
这十项任务分别是:两位数加减法、三位数加减法、四位数加减法、五位数加减法、两位数乘法,以及一位数混合运算。


用于测试 GPT-3 计算能力的十项任务。
在这十项任务中,模型必须生成正确的答案。对于每项任务,该研究生成包含 2000 个随机实例的数据集,并在这些实例上评估所有模型。
下图展示了 GPT-3(few-shot)在这十项计算任务上的性能。从图中可以看到,小模型的性能较差,即使是拥有 130 亿参数的模型(仅次于拥有 1750 亿的 GPT-3 完整版模型)处理二位数加减法的准确率也只有 50% 左右,处理其他运算的准确率还不到 10%。

关于训练
GPT-3依旧延续自己的单向语言模型训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。同时,GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。
对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
为了达到上述目的,作者们用预训练好的GPT-3探索了不同输入形式下的推理效果:
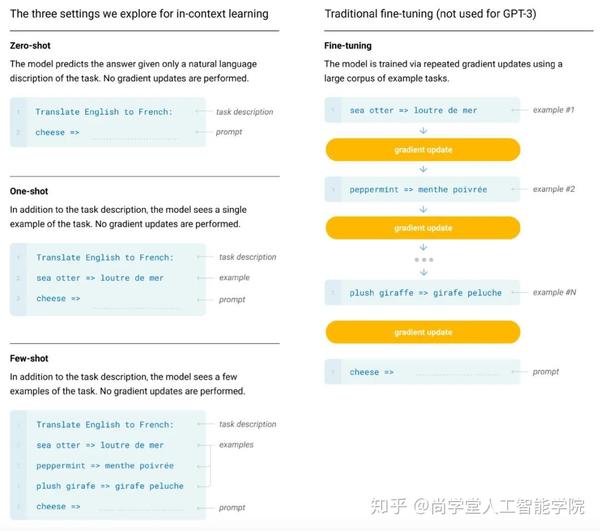

这里的Zero-shot、One-shot、Few-shot都是完全不需要精调的,因为GPT-3是单向transformer,在预测新的token时会对之前的examples进行编码。
作者们训练了以下几种尺寸的模型进行对比:


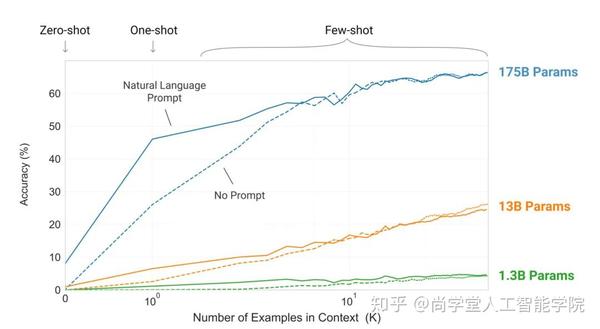
实验证明Few-shot下GPT-3有很好的表现:

NLP领域 :我要爆啦!


最后 对人工智能感兴趣的小伙伴-评论关注;
有免费教程!!