数学建模笔记——评价类模型之熵权法


嗯,这次讲一讲熵权法,一种通过样本数据确定评价指标权重的方法。
熵权法
之前我们提到了TOPSIS方法,用来处理有数据的评价类模型。TOPSIS方法还蛮简单的,大概就三步。
- 将原始数据矩阵正向化。 也就是将那些极小性指标,中间型指标,区间型指标对应的数据全部化成极大型指标,方便统一计算和处理。
- 将正向化后的矩阵标准化。 也就是通过标准化,消除量纲的影响。
- 计算得分并排序。公式就是S_i = \frac {d_i^-}{d_i^+\ +d_i^- }。
对于上述d_i^-和d_i^+的计算,我们往往使用的是标准化数据后,待评价方案与理想最优最劣方案的欧氏距离,也就是d_i^+\ =\ \sqrt {\sum_{j=1}^m (z_j^+\ - z_{ij})^2 },d_i^-\ =\ \sqrt {\sum_{j=1}^m (z_j^-\ - z_{ij})^2 }。这样的计算方式其实隐藏了一个前提,就是我们默认所有指标对最终打分的重要程度是相同的,也就是他们的权重相同。
但是在实际的问题中,不同的指标往往具有不同的权重。即使题目本身可能没有直接指明这方面的要求,但是仅仅根据常识,我们也晓得评价指标的重要程度许多情况下都是不完全相同的。因此在TOPSIS的拓展方面,我们提出了带有权重的欧氏距离求法:


赋予评价指标不同的权重,更符合实际建模情况,也更具有解释性。确定权重的方法我们也提到过多次了,上网查找别的研究报告,发问卷做调查,找专家赋权等等。我们了解的比较深入又显得有逼格的确定权重的方法,就是层次分析法了。但层次分析法的缺点也很明显,即主观性太强,判断矩阵基本上是由个人进行填写,往往最适用于没有数据的情况。
当我们具有数据时,能否直接从数据入手,确定权重呢?
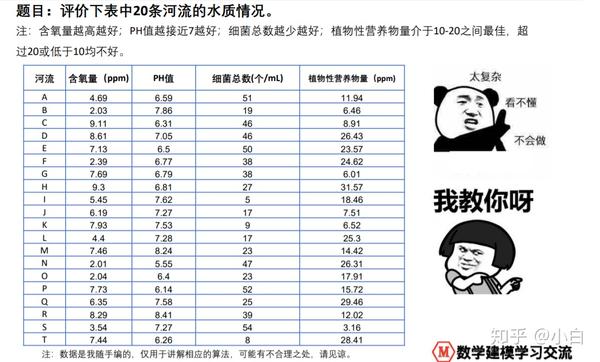

例如上面的题目,常识很难帮助我们确定影响水质最重要的因素是哪一个,也很难告诉我们其余指标的重要程度如何衡量。倘若没有查到相关资料,那我们真的只能完全主观赋权了。这里也只有四个指标,万一来了十个二十个,单是主观赋权就比较麻烦了……
说了这么多,就可以引出一种完全由数据出发,且具有一定逼格的确定权重的方法啦,也就是熵权法。其实听了上面这句话,就应该意识到熵权法的不足之处:只从数据出发,不考虑问题的实际背景,确定权重时就可能出现与常识相悖的情况。以至于评分的时候,也会出现问题。当然啦,我们完全可以灵活一点。熵权法还是有它的优势的,而且逼格比较高……当然我也不晓得评委老师们喜不喜欢这个方法,这里只是介绍,是否采用全看个人啦~
熵——一个系统内在的混乱程度。听起来就很厉害是不是?还有一个著名的“熵增定律”,相信大家或多或少都有所耳闻。虽然是个热力学定律,但其实包含了某种哲学道理:一切事物都是从有序趋向无序。那为什么这个确定权重的方法叫熵权法呢?毕竟数据都是完全给定的了,不会再有所谓向无序的转变了。
具体的我也不晓得,简单讲下我的看法。现代科学除了用熵,还用“信息”来表达系统的有序程度。如果一个系统包含某种确定的结构,就具有着一定的信息,这种信息称之为“结构信息”。结构信息越大,系统就越有序。这么说可能比较玄学,举个简单的例子。
你看海边的沙子,如果仅是随着自然状态自由分布,基本没有什么信息可言,系统完全是混乱而无序的。


如果堆出了一个沙堡,事情就不一样了。沙子有了一定的结构,这部分沙子组成的系统相对变得有序,我们也可以从中看到一定的信息。这样的信息越多,沙堡也就越发精确,系统也就更加有序。应该可以理解的吧~


当然啦,不理解也没关系,我就随便说说。熵权法的原理是:指标的变异程度越小,所反映的现有信息量也越少,其对应的权值也越低。也就是说,熵权法是使用指标内部所包含的信息量,来确定该指标在所有指标之中的地位。由于熵衡量着系统的混乱程度,也可以拿来衡量信息的多少,方法被命名为熵权法倒也可以理解。(不过都是我猜的……)
ok,那我们如何去度量信息量的大小呢?我们可以用事件发生的概率去度量信息量。举个例子,如果小明同学的成绩一直是全校第一,小张同学的成绩一直是全校倒数第一,它们两个同时考取了清华大学。你觉得是“小明考上清华”这一事件的信息量比较大,还是“小张考上清华”这一事件的信息量比较大。很明显,“小张考上清华”这一事件中可能包含着更多的信息量。因为小明一直是全校第一,考上清华应该是一件自然而然的事情,大家都这么觉得。而小张一直是倒数第一,突然考上了清华,一件本来不可能发生的事情发生了,这里面就蕴含着许多的信息。
不过这里有个小问题,上述例子所说的信息,和熵权法原理中提到的现有信息,是不是同一类型的信息呢?
不管怎样,我们可以得出一个简单的结论,越有可能发生的事情,信息量越小,越不可能发生的事情,信息量越多。而我们使用概率衡量事件发生的可能性,因此也可以使用概率,衡量事件包含的信息量的大小。
如果把信息量用字母I表示,概率用p表示,那我们可以画出一个大致的函数关系图。
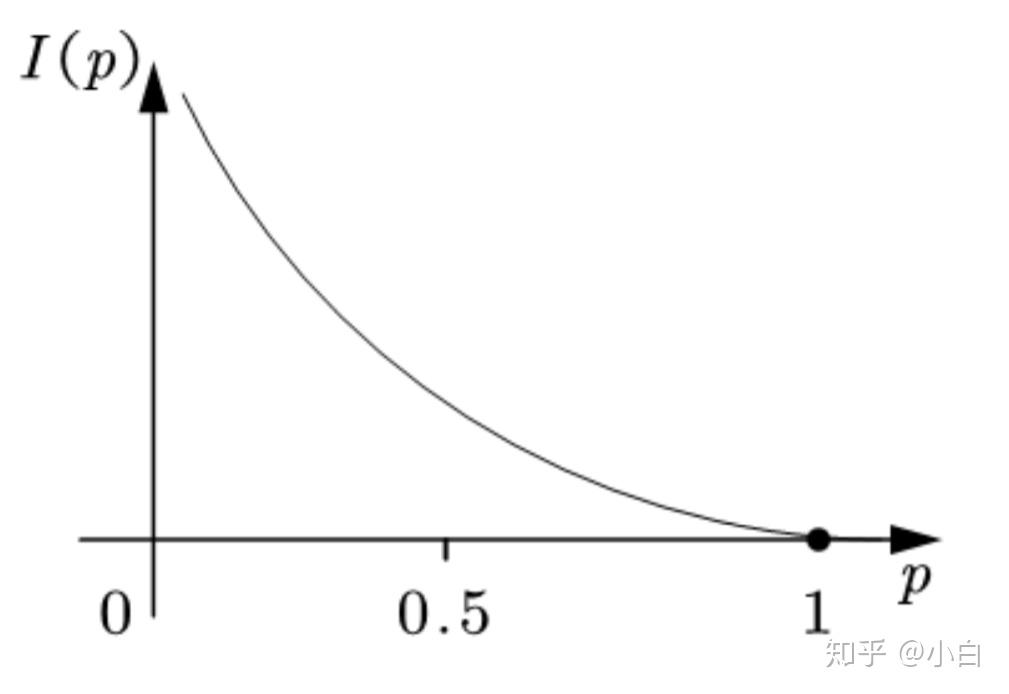
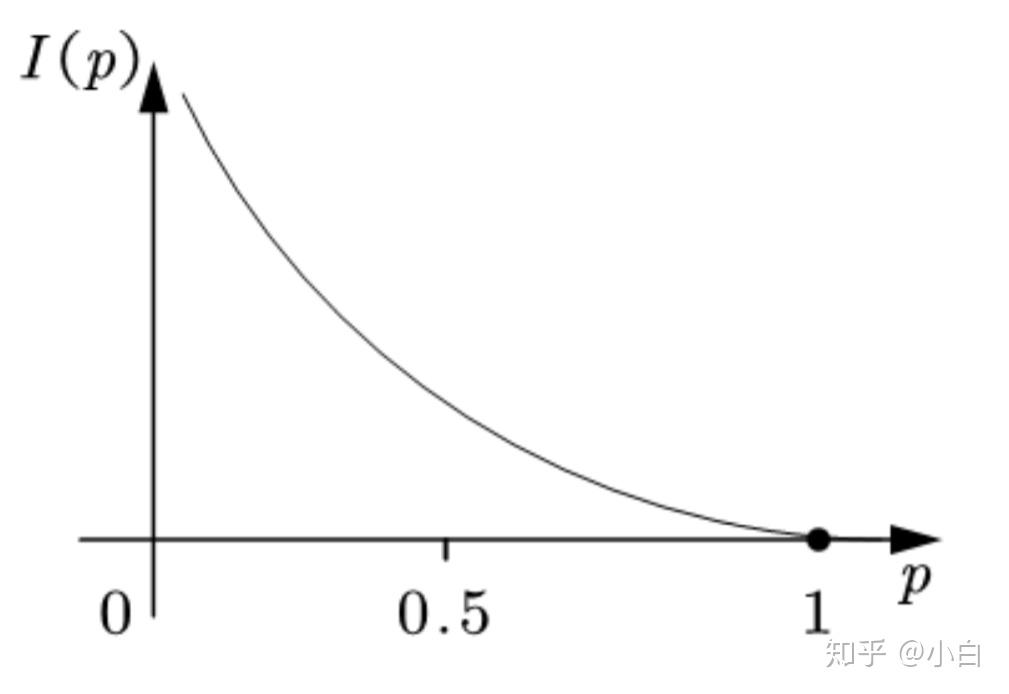
可以发现,信息量随着概率的增大而减小,且概率处于0-1之间,而信息量处在0-正无穷之间。于是,我们可以用对数函数关系来表达概率与信息量的关系。
假设x是事件X可能发生的某种情况,p(x)表示这种情况发生的概率,我们定义I(x)=-ln(p(x)),用来衡量x所包含的信息量。对数函数的定义域是(0,+∞),而概率的范围是[0,1],但是我们一般不考虑概率为0的事件。因此使用对数函数并无定义域方面的不妥。
如果事件X可能发生的情况有x_1,x_2,...,x_n,那我们可以定义事件X的信息熵为H(x)=\sum_{i=1}^n[p(x_i)I(x_i)]=-\sum_{i=1}^n[p(x_i)ln(p(x_i))]。我们可以看出,信息熵就是对信息量的期望值。当p(x_1)=p(x_2)=...=p(x_n)=\frac 1n时,H(x)取最大值为ln(n)。
那信息熵越大,现有信息量到底是越大还是越小呢?上面我们说,信息熵是对信息的期望值,那应该是信息熵越大,现有信息量越大吧。其实不然,因为这里的信息的期望值,应该是对未来潜在信息的一种期望。我们说小概率事件包含的信息量多,是因为一件几乎不可能发生的事件发生了,背后很大程度上有着许许多多未被挖掘的信息,最终导致了小概率事件的发生。我们说一件大概率事件包含的信息量少,其实也是指这件大概率事件发生后,能够被挖掘出的信息量比较少。
上面未被挖掘的信息量,全部都是事件未发生前的潜在信息量,并不是现有信息量。当我们已经掌握了足够多的信息,某些事件的发生就是一件自然而然的事情,我们便可以认为这类事件属于大概率事件。当我们掌握的现有信息较少时,我们很难认为某些事自然状态下会发生,就觉得这类事件是小概率事件。觉得“年级第一考上清华”很正常,因为我们对他的考试实力已经有了足够的了解;而“倒数第一考上清华”,很可能是因为我们没有了解到一个重要信息,例如“倒数第一是故意考倒数第一的”……
嗯,以上是我的想法,也就是对应着“信息熵越大,现有信息量越小”的结论。上面的例子可能还有一些逻辑问题,仅供参考。但是要说明的意思应该是比较明了的。随机变量的信息熵越大,目前已有的信息量就越小。而我们的熵权法,其实是基于已有的信息量确定权重的。
ok,铺垫完毕,接下来就是熵权法的计算步骤了。
1.对于输入矩阵,先进行正向化和标准化(忘记了就去看评价类模型第二篇文章)。
如果正向化之后所有数据均为正数,对于矩阵
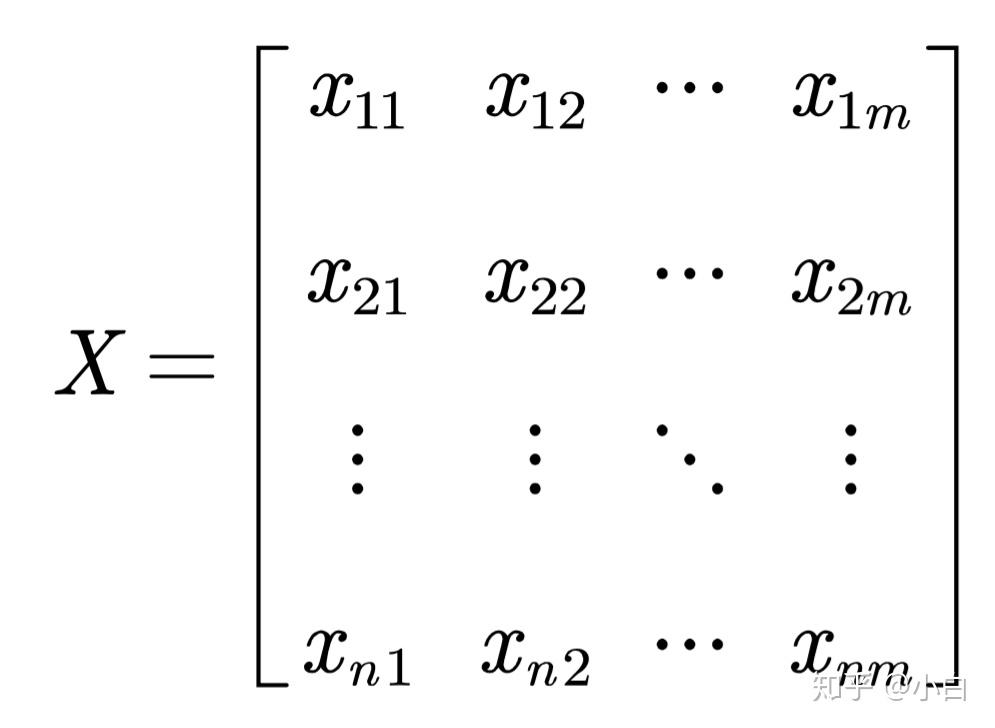

我们可以使用z_{ij}=\frac {x_{ij}}{\sqrt {\sum_{i=1}^n x_{ij}^2}}对每一列指标进行标准化。
如果正向化之后的矩阵存在负数,我们可以使用z_{ij}=\frac {x_{ij}-min\{x_{1j},...,x_{nj}\}}{max\{x_{1j},...,x_{nj}\}-min\{x_{1j},...,x_{nj}\}}进行标准化。总而言之,需保证标准化后的数据皆为正数。
2.计算第j项指标下第i个样本所占的比重,并将其看作信息熵计算中用到的概率。
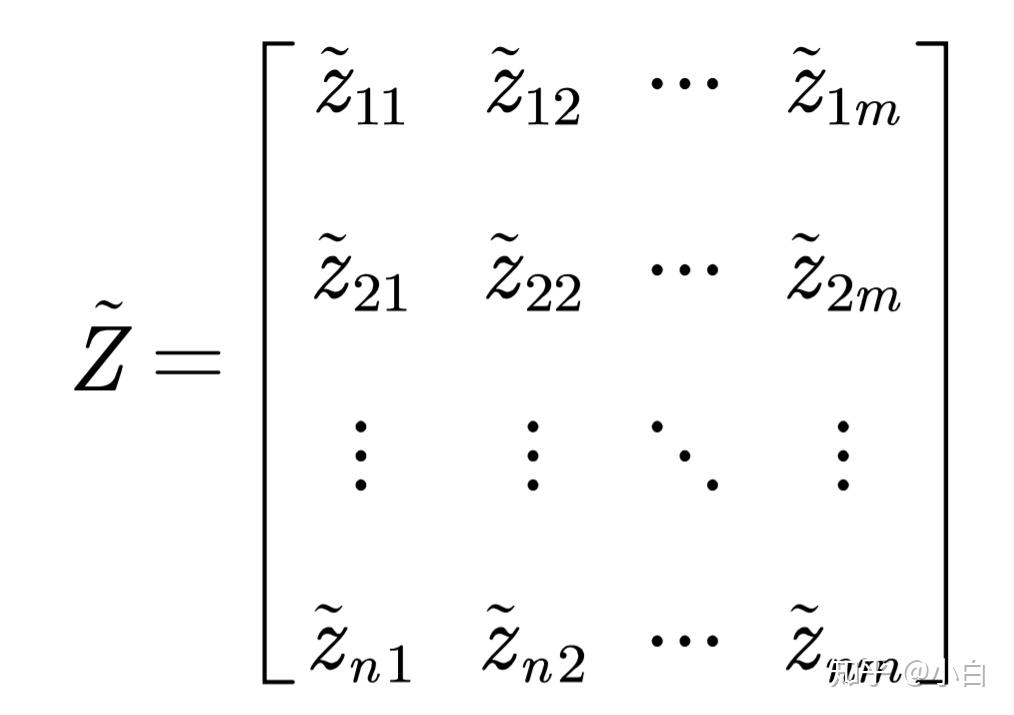
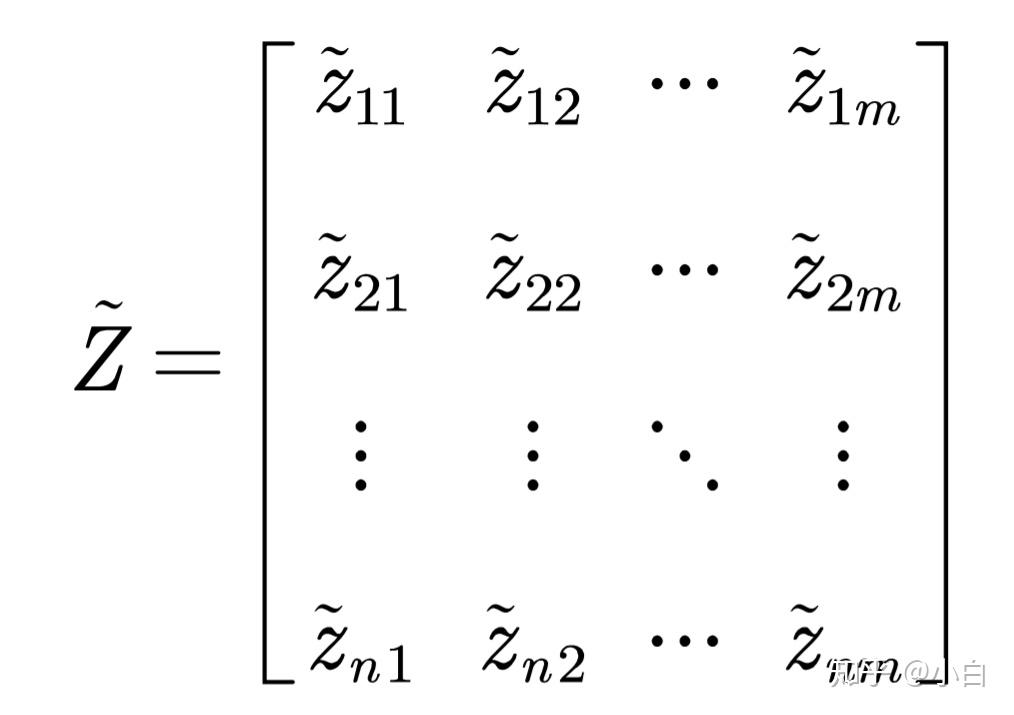
Z是上述经过标准化的非负矩阵,我们由Z计算概率矩阵P。P中每一个元素p_{ij}=\frac {z_{ij}}{\sum_{i=1}^n z_{ij}}。嗯,不要问我为什么要用这种方法确定概率,我也不是很晓得,感兴趣自行查阅吧。查到了可以给我留言告诉我吗?
3.计算每个指标的信息熵,并计算信息效用值,归一化之后得到每个指标的熵权。
对于第j个指标而言,其信息熵计算公式为e_j=-\frac {1}{ln(n)}\sum_{i=1}^n [p_{ij}*ln(p_{ij})],j=\{1,2,3...,m\}。上文中我们提到过,H(x)=-\sum_{i=1}^n[p(x_i)ln(p(x_i))]的最大值为ln(n),所以我们计算e_j时,除以一个常数ln(n),可以使e_j的范围落在[0,1]之间。
上文中也提到了,信息熵越大,已有的信息量就越小。如果e_j=1,信息熵达到最大,此时p_{1j},p_{2j},...,p_{nj}必须全部相同,也就是z_{1j},z_{2j},...,z_{nj}全部相同。如果某个指标对于所有的方案都具有相同的值,那这个指标在评价时几乎不起作用。例如所有的评价对象都是男生,那评价时就不需要考虑性别因素。这也再次告诉我们,在熵权法的框架中,信息熵越大,已有信息量越小。
因此我们定义信息效用值d_j=1-e_j,则信息效用值越大,已有信息量越多。之后我们将信息效用值进行归一化处理,就可以得到每个指标的熵权W_j=\frac {d_j}{\sum_{j=1}^m d_j},j=\{1,2,...,m\}。
以上就是用熵权法计算指标权重的全过程了,其实也不是很难。本质上就是“给包含现有信息量更多的指标以更高的权重”。之后就可以按照这个权重,计算TOPSIS中的优劣距离,甚至可以直接加权打分。
熵权法局限性
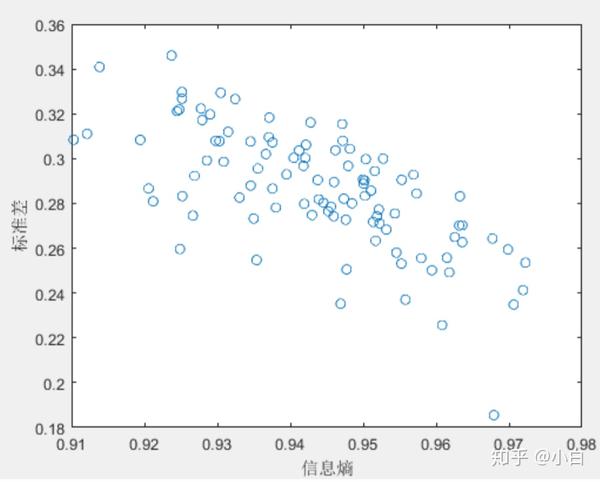
事实上,所谓的已有信息量的大小,其实也可以看成指标数据标准差的大小。所有研究对象在某一指标的数据完全一样时,标准差为0,信息熵最大。如果我们进行蒙特卡洛模拟,可以发现信息熵与标准差基本成负相关关系,也就是说标准差与已有信息量基本成正相关关系。标准差越大,数据波动越大,已有信息量也就越大,我们给它的权重也越大。某种意义上就这么回事。

清风老师提出了一个有意思的问题。在评选三好学生时,如果X是严重违纪上档案的次数,Y是被口头批评的次数,哪一个指标对三好学生评选的影响更大?很明显,实际生活中,一旦严重违纪记入档案,基本就不可能再成为三好学生。但绝大多数人这一指标的值都是0,只有很少数人是1或者2。它的波动很小,按熵权法赋权时的权重就很小。但如果真这么做了,可能某个人即使严重违纪了,依然有可能被评为三好学生。这是与实际不符合的。
这个例子告诉我们,熵权法的局限性在于,它仅凭数据的波动程度,或者说所谓的信息量来获得权重,不考虑数据的实际意义,很可能得出违背常识的结果。
清风老师之前觉得,这个方法是忽悠新手的,因为只要方差大,就认为权重大,显得很没有道理。甚至还不如我们用层次分析法给出一个主观的赋权,或者在网上查资料等等。除此之外,第一步中标准化的方法不一样,最后的结果也可能不太一样,这也是一个问题。
但其实有些问题也是可以解决的。例如上面的严重违纪的问题,完全可以把严重违纪的样本剔除掉,对剩余的样本进行排序。以及,对于现实生活中影响非常大的指标,也可以进行提前的赋权,剩下的指标再用熵权法去分余下的权重。
如果对评价指标具有现实性的了解,那完全可以看看熵权法的结果是否符合实际,再决定是否采用。如果对评价指标了解较少,层次分析法显得很随意,网上也搜不到相应的结论,那使用熵权法也是一件无可厚非的事情。
至于用指标内数据的波动程度来衡量指标的重要程度,到底有没有道理。这个也是见仁见智的事情。我个人觉得还是有一定的道理的。在标准化消除量纲的影响之后,某个指标包含的数据波动程度越大,一定意义上表明该指标对最后的结果,会有一个比较大的影响。因为它取值范围广嘛。TOPSIS中的理想最优解和理想最劣解,就是分别取各指标的最优值和最劣值。而波动程度大的指标在计算某个方案和理想方案的距离时,很显然会有较大影响,给它更高的权重,也不是完全没有道理。当然啦,这种方法还是需要排除特殊情况的,一般情况下我觉得问题不大。
(上面就是随便扯扯,别太当真。)
我觉得,只要熵权法最后的结果,没有违反普遍的常识,用一用也没有太大的问题。清风老师也说了,如果只用来比赛,熵权法就尽管用,这个方法总比自己随便定义的要好点儿吧(一般情况下)。
嗯,以上就是我想说的关于熵权法的全部东西啦。如果还想进一步了解,请自行查阅啦。
拜拜~
这两天知乎给我推送了一些数学建模相关的问答,其中一个是数学建模相关书籍。我把高赞回答推荐的书的电子版找了一下,如果需要的话,在微信公众号“我是陈小白”后台回复“数学建模书籍”即可。