
多任务模型之MoSE

前言
之前,我们介绍过Google研发人员开发的非常经典的一款多任务学习模型MMoE,MMoE由于其模型的简单,已经在工业界进行了大量的应用,包括小米、京东等涉及到个性化的业务都有相关部署。然而,因为MMoE中experts的足够“简单”,使其在表达各个任务的同时,不能很好地对用户的行为序列进行解析,因此就会导致MMoE模型在进行多任务学习时,不能很好地对序列行为数据进行有效表达。本文将介绍一款新的模型——MoSE[1],其将MMoE中的expert做了改造并取得了很好的效果。
问题背景
在日常的互联网中,用户往往在使用一次互联网时,具有一定的前后相关的序列关系,多目标学习可以很好的同时对用户的前后相关行为进行有效的学习,可能有助于更好地学习不同用户行为目标的联合表示,但我们仍然面临一些挑战:
1.数据稀疏性——在现实世界的web应用程序中,用户活动可能是非常稀疏的。例如,与其他事件(如用户印象事件曝光)相比,用户购买事件可能非常罕见。
2.数据异构性——用户活动数据是异构的,并且跨越了各种数据源和类型。例如,用户画像数据包含性别信息,而用户日志数据包含点击信息。由于任务冲突,学习异构数据的共享表示是困难的。
3.复杂的多重目标——目标之间的时序关系,比如点击和购买,因为用户的潜在意图很复杂。
模型提出
于是,在这种背景下,作者提出Mixture of Sequential Experts (MoSE) 模型,这个模型在expert中集成了Long Short-Term Memory (LSTM),使用MoSE对用户行为数据流中的多目标进行建模。另外,作者假设除了数据表示的显式顺序方法外,框架中应该有专门的组件,在合并复杂数据集之前对它们的不同方面进行建模。
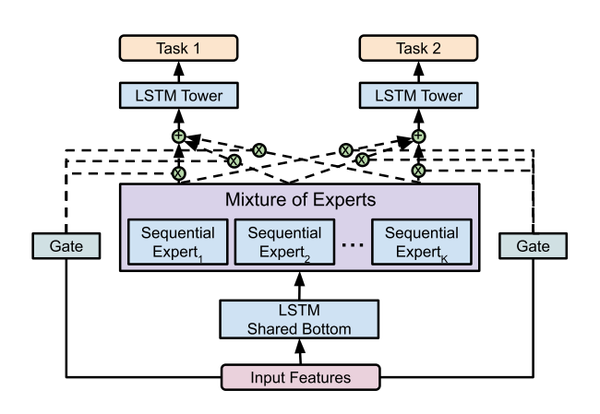
上图为MoSE模型的架构,具体如下:
1.用于使用顺序输入数据的共享底层LSTM模块,它允许从输入层进行显式和有效的表示学习。
2.顺序expert层的混合,其中每个expert为每个任务建模不同方面。例如,expert可以专注于建模稀疏变量的顺序依赖性。Mixture of Expert (MoE)层的主要目标是实现条件计算,在每个例子的基础上只有部分网络是活跃的。通过使用LSTM代替全连接网络,进一步增加了MoE层,更好地处理序列数据。
3.用门控网络对expert的输出进行门控。每个门控网络可以学习“选择”一个子集的expert使用条件输入的例子。这允许在不同的变量之间建模复杂的交互作用。
4.多Tower网络,每个任务有一个Tower,解耦优化的任务。这是多任务学习文献中常见的结构,对于学习具有不同规模和数据类型的不同任务非常有用。
实验结果
作者将MoSE与七个备选模型进行比较,并显示了G Suite数据的结果。由于数据的敏感性,作者只展示了模型的相对性能。得出以下结论:
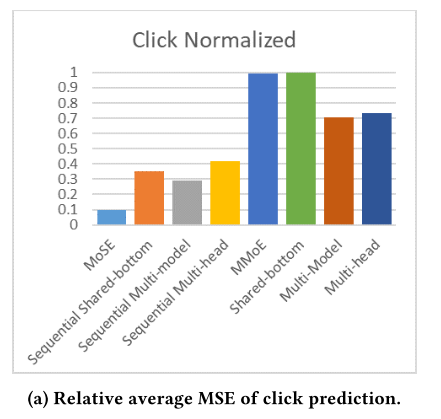
1.MoSE的推理性能始终优于其他选择,尤其是在复杂的真实数据集上。
2.一般来说,顺序模型的性能优于非顺序模型,这说明了在用户活动流中显式地建模序列依赖关系的必要性。
3.MoSE显著优于其他序列模型。这说明MoSE模块能够有效地处理用户活动流中的稀疏变量和异构数据源之间复杂的交互等问题。
4.与其他非顺序模型相比,MMoE本身并没有显示出显著的优势。当在MoSE中那样使用顺序expert时,expert混合框架是最有益的,因为用户活动流中的大多数复杂性似乎源于顺序复杂性和稀疏性。
总结
通过上述实验的分析和对比,我们可以看出,MoSE模型在用户行为序列事件的建模中,会取得不错的效果,并且文中作者还指出了MMoE模型在序列建模中的缺点(由于推荐中特征的稀疏性导致FC层对特征的表达不足),因此,我们可以通过LSTM对用户行为序列进行建模以取得更好的效果。但是问题来了,MoSE模型如果通篇都用LSTM代替FC,在在线推理中,LSTM是串行计算的,这是否会由于expert数量的增多而导致推理变得缓慢呢?这是一个值得思考的问题。
参考文献
[1] Z. Qin, Y. Cheng, Z. Zhao, Z. Chen, D. Metzler, and J. Qin, “Multitask Mixture of Sequential Experts for User Activity Streams.”
如果你喜欢我的文章,欢迎关注我的微信公众号【软客圈】(ID:recoquan)
纯手工打造,实属不易,欢迎大家分享和转发~
原创内容,转载需注明出处,否则视为侵权并将被追诉!