多阶hash实现与分析

多阶hash作为腾讯即通部门底层存储,在资料、关系链系统中均有使用,内部文档大多讲述实现原理,缺少实现细节与具体源码,在github偶遇一份类似实现,特分析之。
多阶hash简介
我们常用的hash只有一层结构,常采用链表法进行冲突解决:
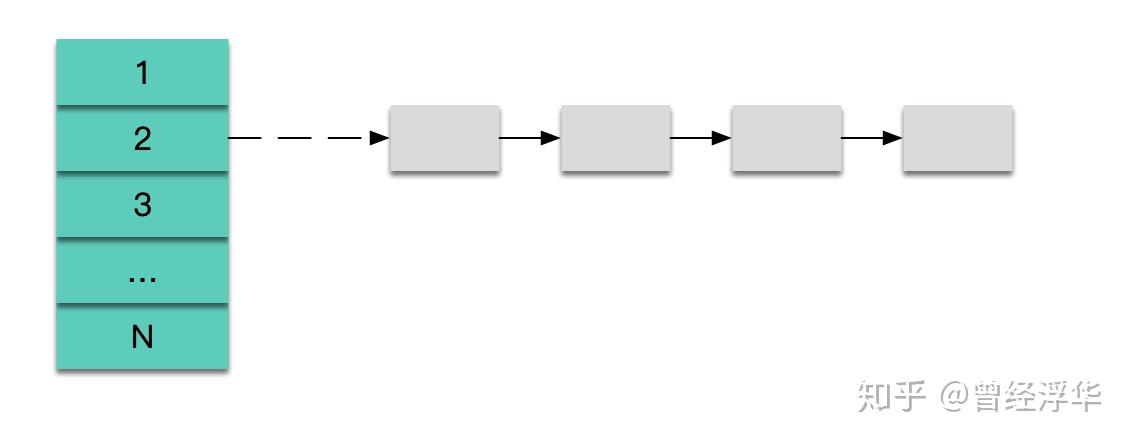

当hash结构装载的数据较多时,冲突严重,链表结构长度较长,查找key的过程需要对链表进行遍历,耗时不可控,这时可以进行hash扩容,即将hash桶数量扩大,数据重新迁移到某个index下,但此数据迁移过程耗时较长,同时需要考虑读写冲突问题。
腾讯设计的多阶hash,即是将某一层冲突的key,交由下一层进行填充,直到最终层


多阶hash构造时候,需要两个参数,第0层最多容纳的元素个数N,阶数M
每一阶可容纳元素个数如何计算呢?
从N开始计算比它小的素数,依次作为每一阶的元素个数
假如N=100,M=5,那么每一阶元素个数为:
97,89,83,79,73
元素插入流程:
根据元素key计算hash值,对N0取模得到下标,查看该坑位是否被占 如果该坑位被占,那么下移到下一阶,重复上述计算过程,直到:
- 某一阶有空余坑位,那么将该元素插入
- 如果查找到最后一阶,仍然没有空余坑位,那么插入不成功,对外报错。但是综合考虑N,M值,这种情况概率极低
最差情况下,需要查找M阶,才能找到可插入坑位
元素查找流程:
与元素插入流程类似 根据原始key计算hash值,从第0阶开始依次查找对应坑位,检查坑位中元素key与待查找元素key是否匹配,如果不匹配,则下移到下一阶,继续查找 如果某一阶对应坑位hash值为0,也就是该坑位为空,不能停止查找元素,因为该坑位可能是由于删除操作而释放出来
最差情况下,需要查找到最后一阶,也就是查找M阶,才能找到元素
综上,该数据结构,最坏情况下需要查找M阶
与普通hash结构相比,其优缺点如下:
优点:
- 实现结构简单,利于cpu缓存,查找速度不一定慢
- 可直接将数据结构保存到磁盘,进行落地存储
- 插入与查找时间可控,不需要复杂的动态扩容流程
缺点:
- 初始内存占用多,不像普通hash随着元素插入逐渐消耗内存
- 不支持扩容,初始构建时即限定可插入最大元素数量
综合考虑优缺点,可用其实现一些高性能的存储系统
多阶hash实现
多阶hash的元素一般保存key值,其value需要找地方额外存储
整个系统设计如下:
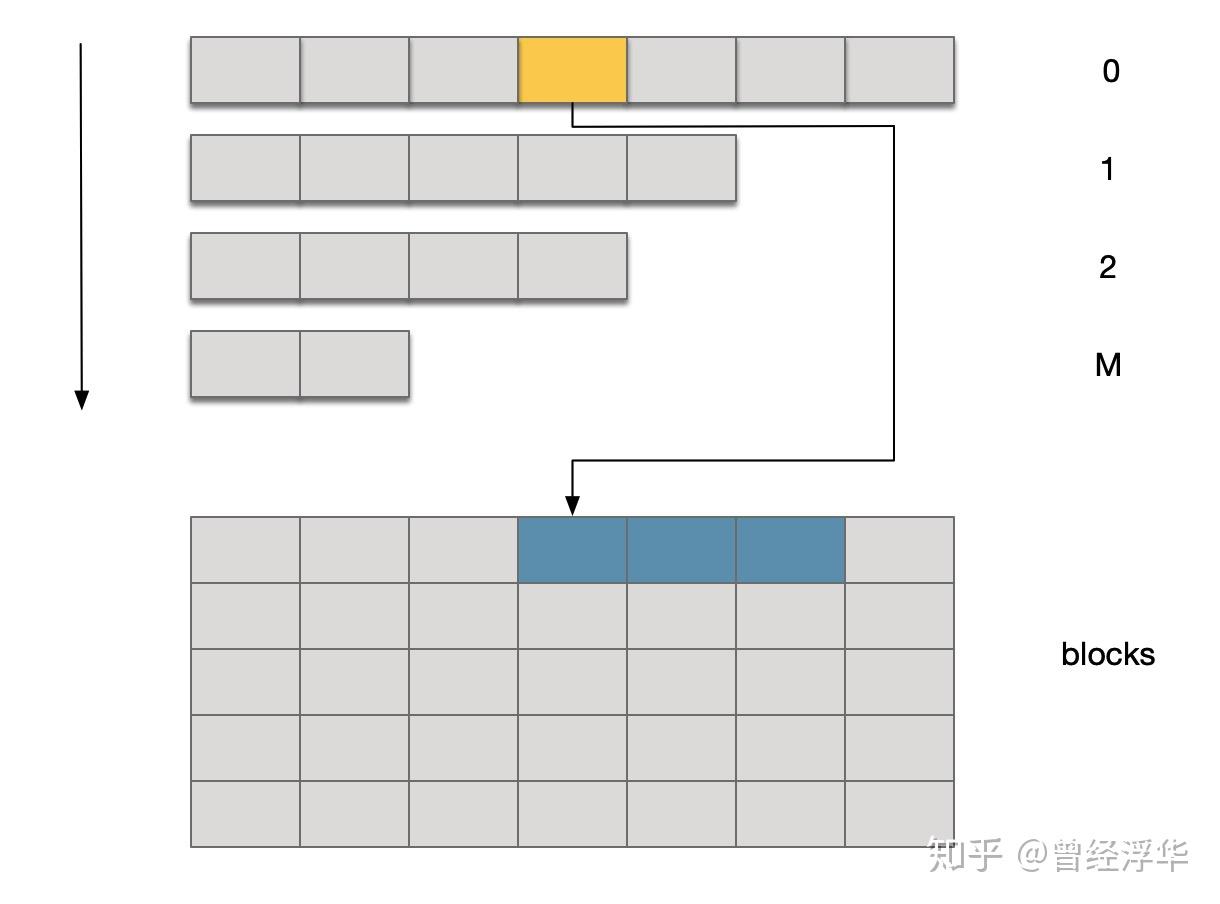

系统保留一大块内存,并切分为小的block,每个block有固定大小,这样一个value会占据一个至多个block
例如:每个block为32字节,需要写入value为70字节,那么其将占据3个(2 * 32 + 6)block
内存布局:
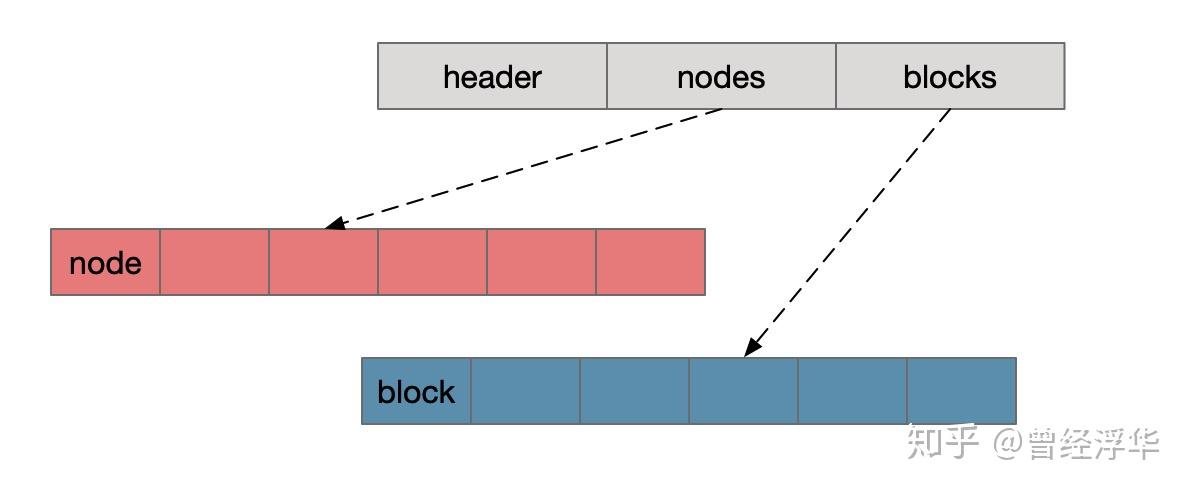

整个存储由: header + nodes + blocks 三部分构成,其中nodes由所有的node节点组成,blocks由所有的block元素构成
nodes即是由多阶hash打平而来,而blocks本来就是预先申请的大块存储
内存结构即最终磁盘组织结构,不需要额外转存,设计非常巧妙
如果再配合内存映射mmap简直完美,操作内存即是操作文件!
几个问题
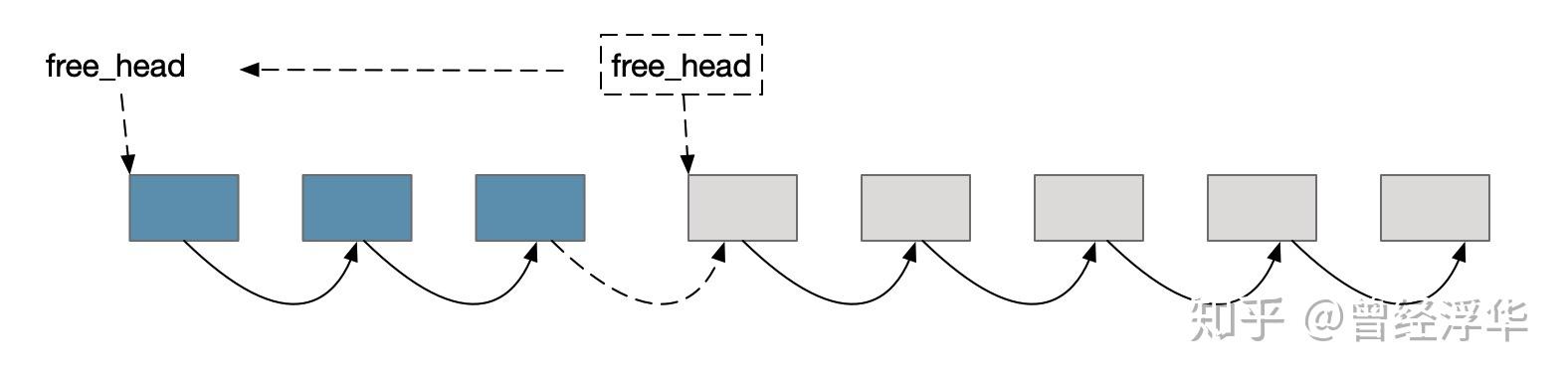
- 插入元素时,如何查找可用block? 将空闲block组织成链表结构,在每个空闲block中记录下一个空闲的block地址,将空闲block逻辑上串联,在header中记录空闲链表头部地址。 需要空闲block时,从空闲链表头部开始获取即可


- 删除元素后如何回收block? 查找待删除的最后一个block,将其next设置为header中空闲链表头部地址,同时将header中空闲链表头部地址更新为删除的第一个block地址
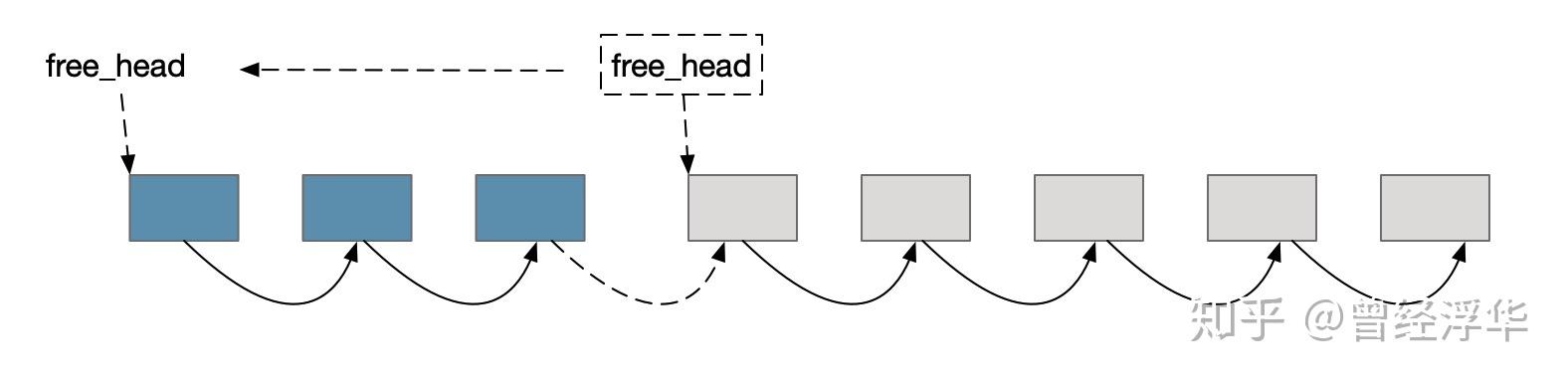
最后
经过以上分析,再查看项目源码会理解得比较透彻
项目地址:多阶hash