
城市计算:大数据如何解决北京的问题



文/郑宇
本文整理自今年在北京举办的麻省理工斯隆“技术创新与创业论坛。演讲者郑宇是微软亚洲研究院主管研究员,他也是麻省理工科技评论TR35(35名在科技创新领域具有杰出成就的35岁以下顶级青年创新者)获奖者。
城市化的进展给我们带来了现代化的生活,但是也带来很多问题,比如说交通的拥堵、能耗的增加和环境的污染,要解决这些问题在很多年前看似几乎不可能,因为城市的设置过于复杂,牵一发而动全身,环环相扣。但是现在,由于传感器技术的发展和大规模计算基础单元的成熟,产生了大量的大数据,从我们的社交媒体,到我们的气象数据,从我们的地理地图数据,到交通流数据,如果使用得当的话,这些大数据可以帮助我们发现这个城市的问题,并进一步帮助我们去解决这个城市的问题。
基于这个,我们提出了城市计算这个话题,包括四个环节,城市感知、城市数据管理、城市数据挖掘和城市数据提供,把这四个环节形成一个环路,在不干扰人生活的情况下自动改善人、城市、生活,所以简短来说,我们就是要用大数据去解决大城市中的大挑战。
下面看一下这个城市里面到底有什么样的大数据呢?第一个,就是我们的路网数据,其实是北京的一个地图数据,其中红色可以来表示高速公路,蓝色表示环路,如果有多年这样的数据,我们可以知道这个城市的交通网络在如何的扩张。
另外一个数据,就是我们的兴趣点数据。一个兴趣点,包括名字、地址、GPS坐标和类别。比如某个楼就是兴趣点,某个楼显示的是北京酒吧和电影院的分布,其中黄色点表示电影院,蓝色点标志酒吧。如果有多年这样的数据,我们可以知道这个城市在如何的变化、兴盛或者消亡。
举个例子,在过去的5年里面,北京市电影院的数目持续增加,达到了260家,那就说明可能有越来越多的人去电影院看电影,而不是买DVD了,很多故事可以从大数据里面发现。
下一个就是我们很关心的,空气质量数据,通常被定义为优良、有害或者有毒等等,这个数据中国人很关心,我们美国的同事也很关心,只是关心的方面是不一样的。这个数据跟气象相关,包括刮风、下雨、温度、湿度、气压等等。
这也是一个数据,人移性的数据,在什么地方可以怎么样,这个数据反映的是人在城市里面怎么移动的。
最后是一个出租车的轨迹数据,这是三个月的数据,越亮的地方车越多。如果我们把三个月的数据加到一起,总长度是地球到太阳距离的三倍。如下图是反映北京出租车轨迹数据的热度图。
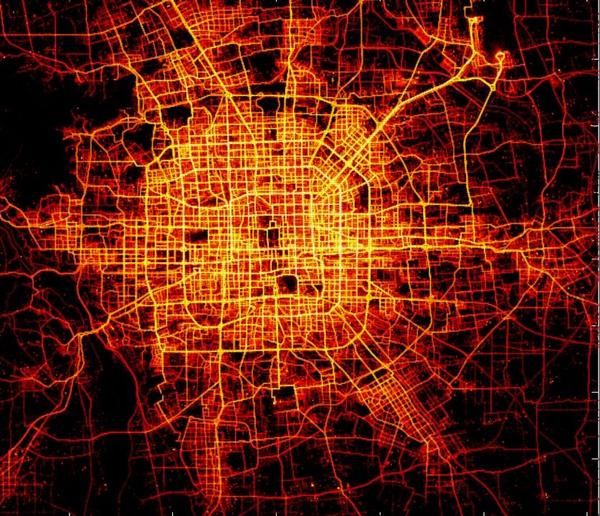

这个数据告诉我们的其实不光是地面的交通流量,因为装GPS的出租车可以感知路面流量,我们知道这个城市里面人是怎么通过出租车出行的,因为我们知道每辆出租车的上车记录和下车记录,这两个不同的就是,根据人乘坐出租车产生的图,左边是工作日,右边是节假日,颜色越深,代表单位时间里面到达这个区越多。基本上北京东北部这个部分,CBD的比较多一点。对比两个图,工作日和非工作日看的话,这个概率高于非工作日,很简单,因为非工作日出去玩了。
基于这个数据我们做了详细的研究,今天讲三个案例,分别关于环境空气质量、能耗和我们的城市规划。
第一个,大家最关心的就是我们的空气质量,中国政府也是非常头疼这个事情。在北京已经建了22个空气质量监测站,图上的每个蓝点就是空气质量监测站,但是这个数量还是非常有限的,因为建一个站点非常昂贵。数目这么有限我们面临的是什么问题呢?一个城市的空气质量是不均匀的,而且是非常不均匀的。我们看这个图,这里面每个图案代表的是已经建好的,它的数字就表示空气质量,在同一时间不同地点的空气质量读数可以差得很远,有的时候即便挨得非常近,但是也可以差几百。因为什么呢?因为一个地方的空气质量有很多复杂因素来决定,包括我们的交通流量、气象条件,以及这个地方的土地使用规划,有多少工厂、公园,都不一样。
另外,不同地方的空气质量随时间变化也是不一样的,我们看这样一个例子,北京的空气质量从好变坏,并不是一瞬间所有地方都变坏、所有地方都变好,可以看到,不同地方随着时间变化是不一样的,有的地方只有几十,有的地方已经几百了。正是因为这样一个原因,我们就不知道如果一个地方他没有建空气质量监测站,他读数是多少,比如现在这个位置空气质量到底是多少,不能根据平均值去看这个读数,也不能简单的用线性差价来计算。
我们还加上5个其他大数据,包括了气象条件,刚刚说刮风、下雨、湿度、气压等等。交通流量数据,还有单位时间里面多少人来、多少人走,有多少餐馆、多少公园、多少广场等等,结合这些数据我们就可以建立一个模型,建立一个地方的数据和这个地方空气质量的模型,以后给定这样的数据即使没有建空气质量监测站,也可以把这个地方的空气质量算出来,这是我们已有的空气质量监测站的数据,可以算出北京任何一个角落一公里乘一公里细粒度的空气质量,我们就知道什么时候去跑步、什么时候让小孩出来,并且这个细粒度也是我们下一步解决空气污染问题的前奏,你知道什么原因导致的污染,必须知道哪个地方总是被污染,才可以去分析。
这个是采用了基于云和端的架构,云实时的得到气象质量数据,通过手机客户端和我们网站提供的用户信息,可以访问任何一个地方的空气质量,这个服务已经发布,是公开的。这个手机应用,如果用Win Phone,点任何一个地方,马上可以告诉你空气质量多少。
这个精度可以做到0.8。中国10个城市做这个应用,并且验证了这个成果,0.8的精度,是用大数据的方法做的,之前传统行业基于空气动力学模型0.6,而且喊了很多很多年行业没有进步,现在环保部已经跟我们签约做这个事情。
第二个,关于城市规划。我们看这个城市的功能区划在什么地方,他们的分布是怎么样的,这个就显示是一个真正的结果,其中红色的是北京的科学和文教区,黑色的表示商业区,但是我要强调一个地区的功能不是单一的,这个地区可能既有商业、也有学校、还有住宅,是一个分布,可能80%是商业、20%是学校,所以具有相同颜色的区域,实际上他们是具有相同功能的分布。
反过来说,即便一个区域被认为是科学文教,也不代表他每个角落都服务于科学文教,就需要进一步确定他某种功能的核心所在,比如右边这个图是表示了北京核心商业区所在,第一,可以帮助我们规划人员做下一步版本的城市规划,因为城市规划一般10年一个版本,但是5年之后就发现这个已经很不一样了,可能因为规划不合理,可能因为政策导向变化了,我们做下一个版本的规划的时候,必须知道当前这个城市的状况是什么样的,哪里是科学文教区,哪里是成熟商业区。
另外,做商业选址的时候可能要考虑这个因素,离其他的商业区多远,都是实实在在的商业价值,这个我们跟北京城市规划研究院的同事有些交流和合作。
这里面是用两部分的数据,为什么不用我们兴趣点数据就够了呢,因为兴趣点数据可以告诉我们一些基本信息,如果看到这个区域里面有很多学校,很可能就是科学文教区。看下面这两个餐馆,数据库里面存储的都是中餐馆,但是他们差别很大,反映的地域功能也是很不一样的,左边可是建立在居民区里面的餐馆,为老百姓服务的,另外一个可能是建在旅游景点为更多人服务的,这个就可以区别代表不同功能的含义。
另外,人的移动性本来反映一个区域的功能,比如发现一个区域,大家早上离开这个区域,晚上回来这个区域,这个区域很可能是住宅区,所以把这两部分数据一结合,就能够把细粒度的功能区划自动出来。
我们在2010年、2011年看到的结果,我们看变化是不是有道理,如果有道理就说明我们做的正确的。第一个区域,A的区域,2010年的时候我们发现浅黄色,代表新兴的住宅区,到2011年变成在建设区,本来觉得挺惊奇的,因为北京第一高楼在这个地方建设了,就是大建设。
另外,就是我们前门大街这块,之前被认为是自然公园,后边变成熟的商业区,大家知道奥运会前后这个地方重建,现在有上百家的商户饭店在这边,就是成熟的商业区。
还有一些地方是我们不知道的,这是望京的区域规划,本来公布住宅区的,我们结果也是吻合,黄色区域新兴住宅区,但是里面有紫色区域就是新兴商业区,这就要政府知道已经有新兴商业区出现了,下一个版本要考虑。
第三个,关于能耗。谁能告诉我在过去一个小时里面北京到底有多少汽油被加,我相信这个问题可能没有人能回答我,有人说这个很像微软的面试题,实际可以通过一些方法来做,我们用装有GPS传感器的出租车,北京市场有近6万多辆出租车,都装了传感器,利用这种传感器检测出租车在加油站的等待时间,用这个等待时间可以算出排队长度,进而算出队里的车的数量,假设这个车的数量符合正常分布,假如平均下来每个人加4升的油,就可以把加油站的加油量算出来。如果能够把整个城市的加油站都算出来,就可以知道这个小时多少油被车加掉了,但是这里面有很多问题,这里面就不展开了。
这个数据有什么用呢?主要是可以来改进我们能源基础设施,比如说我们发现有的区域加油站可能就不够,人很多,总是排很长队,而且大家排队时间、等待时间很久,这个时候我们是不是旁边要加一些加油站呢,反过来有些加油站可能是过度建设的,这个地区可能没有什么人加油,几乎很多地方空置,或者大量开放我们的加油站。
这两个图的结果,可以告诉大家,早上早高峰的时候,北京市600多加油站里面,大概有6万人在加油,他们平均花费的时间是14分钟左右,但到了晚上平均加油时间就是5、6分钟左右,所以我一般就是晚上8点钟以后去加油。
我们要强调,我们是用出租车传感器去感知整个城市的友好,而不是说只是算出租车的友好,可以看到这四个图对比,上面两个是根据出租车的数据看出租车数量阅读图和出租车花的时间阅读图,跟下面整个城市花的时间和整个城市所有人去加油的数量是不一样的。
到底什么是城市计算,回去大家记住三个字,是三个B,就是用大数据解决大城市的大挑战。第二个,我们的方法是什么呢?是三个M,继续学习、数据管理和数据挖掘。我们的三个W,就是人、城市、生态系统都要三赢。更短的就是3BMW。


观众问答
听众:我们这个大数据用模型算出来之后这个东西对决策或者说对政府或者普通人有什么意义?
郑宇:告诉大家很多人不太了解的真相,空气质量,如果北京刮了一整晚的风,可能每个地方都已经均匀了,或者北京如果已经连续3天雾霾非常严重,200以上了,可能也差别不大,但是中国70%的时间是差别非常大的,而且从好变坏、坏变好的过程中是看不出来的,可能觉得今天不错,但是有的地方可能150,因为PM2.5是看不见的。但是能看到PM10以上的颗粒,那是雾,用灰尘作为核心,PM2.5本身是不能看出来的,我们大量的数据进行了比对,利用站点的数据统一时间算最大值和最少值的差距,平均下来每个小时里面最大值减最小值在120以上,还算城区的不算外面的,就是一个地方良,另外一个地方是污染,这还是平均值,最大的时候差300、500是可能的,因为受很多复杂因素的影响,受地面交通流量的影响,有车、没车是不一样的,有没有厂矿,土地使用规划,有公园还是餐馆,都是不一样的,另外气象条件,跟你这里的水域和房屋是有关系的。
两种情况北京可能一致,第一,刮了一晚上大风之后,或者刮了24小时大风之后可能都很好。第二,严重雾霾三天以后,基本上均匀了。但是为什么有时候我们看不出来区别,第一,可能要连续观察,第二,现在很多APP发布的数据是不负责任的,因为政府发布的数据是24小时平均的,政府公布的数据是24小时平均的浓度,就是这个小时的数据跟过去23小时数据加一块,这个平均值一抹基本上看不出区别了,很多APP的人不懂这个东西,也没有想这个东西,这个问题并没有做,因为这是国际标准,但是上海已经认识到这个问题了,就改变这个策略。
这个给大家困扰,觉得政府公布的是假数据,其实并不是假数据,因为是跟过去一个小时的过去很好的天平均了,那就很好了,其实是把今天这个小时的数据跟昨天23小时的数据加在一块平均了。所以现在在很多APP上面,24小时一平均大家看不出这个差别,但是中间千差万别。
另外还有标准的问题,美国标准和中国标准可能不一样,我们系统中是把两个数据都用到一起了,统一标准,都用了中国的标准,因为美国标准和中国标准在低浓度的时候会更敏感、要求更高,但是高浓度的时候其实差不多,所以中国政府并没有公布假数据,我们很多时候发现在同一指标下算出来,中国政府公布的数据还高于美国站点的数据,所以大家要增强对空气质量的认识。
很多人跟我说过,看天是不是可以,刮风是不是可以,其实这个问题非常难,比天气预报还难。天气预报天上就够了,没有其他的干扰因素,但是空气质量既取决于天、还取决于地、还取决于人。环保部他们是专家,他们做这个领域很久了,他们知道传统方法,我们要把这个推广到中国目标200个城市,让大家真正知道现在所在环境空气质量是多少。
听众:还有一个问题,如果只有22个站点的数据,怎么去做大数据?
郑宇:这是非常好的问题。刚刚你说光看空气质量数据本身算不算大数据,但是我们刚刚还说到有另外五类大数据结合在一块,就是交通流量数据、气象数据、人的移动性数据,加上道路结构、餐馆,比如说这个地方他的楼房密度非常高,红绿灯口数特别多,餐馆数也比较多,工厂也比较多,那很可能会不好,当然我们这个是有数据的模型训练出来的,不是人下定义的,也不是写出一些什么规则来。这个模型很复杂,大数据的价值,传统经典模式里面可能写一个简单的方程,空气质量跟风俗成反比或者正比,但是那个可能不准确,因为没有人感觉到那个时候观测是不够的,所以那时候写出来并不能反映实质。
现在大数据来了,人的思维是有限的,不能写出一个非常非常复杂的方程,用积极学习的方法可以学出一个模型来,这个模型可能有上千个参数,超过人本身思维的能力,但他就是能把这个问题解决,就是能告诉你这边有多少,所以这个就是大数据的一个理念。
听众:现在的数据来源包括出租车的GPS信息,包括空气监测站实时的读数,这些应该都是政府所有吗,出租车北京也是政府所有的,像这样的话微软的研究结果读他们这些数,微软和他们大概什么样的合作模式?因为微软是一个商业公司。
郑宇:我们刚刚讲的只是几个案例而已,我们对后还是要把案例中的模型变成模块化设计,我们有一个产品专门来做智慧城市的平台,这里面中间有一层就是数据分析层,中间有很多模块,用产品什么样子,到一个城市里面政府提需求、提数据,给我数据、给我需求,用我的模块像搭积木一样很快搭出一个垂直应用来,空气质量是很快的垂直应用,可能还有交通的,还有我们的环保,还有我们能耗的,所以我们的模式还是要从平台去做,但是要把各种各样的公共模块设计好、集成好,是这样的一个模式。
听众:首先想问一下,在整个大数据的过程中微软到底扮演一个什么样的角色,是说全产业链包括从芯片开始吗,包括建立模块到后期分析,还是具体是什么?第二个问题,在中间很多公司在做大数据,微软跟别人不一样的地方、创新的地方在哪里?第三个问题,到目前为止有没有盈利,如果没有的话,在未来的3—5年中短期来看你们有没有对盈利有一个预期?
郑宇:第一个问题,本来微软就有我们的云平台技术,底层的基础设施我们是有的,但光有一个云可能大家觉得这个并不能算智慧城市,光有一个云只是存储和计算,智慧城市我们在这个云平台上面要做新的层,像你刚刚说的那个产品,就是基于云平台上边加了数据管理、数据分析,专门针对城市里面的大数据来做的应用。我们还是想通过平台的方式推销我们的产品,我们的模式还是刚刚说的,政府你有需求,你有什么样的数据你放过来,我们做一个解决方案,很快平台上面就能形成一个垂直应用,我们跟环保部采用同样的思路,这样可以解决我们政府技术上面的困扰。
微软跟其他方面的优势,第一,我们有硬件的基础设施,我们自己掌握。第二,我们在数据分析能力上面,我们觉得我们有一定的优势,特别是大数据、时空数据的混合分析,这里面还是一个有难点的时候。说大数据其实很多人谈的还是一种数据,单一数据,但真正的大数据并不是单一数据,应该是很多很多种不同的数据融合在一起,这个数据怎么融合,而且要做又快又好,还有很多工作要做,我们在探索,微软有研究院,这正好是他们的特长。
第三个不太适合回答,那个时候我们有商业团队,我们更多从研究来考虑这个问题,以后如果有兴趣可以关注我们的平台,关注我们产品的信息发布,可能会找到你的答案。
此文由MIT Technology Review 中国大陆地区独家授权,更多精彩内容请搜索官方微信“mit-tr”,同我们一道关注即将商业化的技术创新,分享即将资本化的技术创业。


