
Tengine 支持 AML、RK NPU 第1篇-闲聊

背景
2017年
各种机缘巧合来到深圳,抓住人工智能火箭尾巴,挂着 嵌入式Linux驱动工程师 的羊头,卖起了 NNIE 的狗肉。当初团队的理想很丰满:借 Hi3559AV100 神器,造超一流 AI Camera。事与愿违,PoC版本不到一周,项目却光速下马……后来转战 arm neon 优化圈子,成为一名 土法 HPCer + 野生调优师。
有人一直问我端侧AI落地,CPU 与 NPU 到底谁能笑到最后?相辅相成吧,CPU 是基本盘,NPU 再来锦上添花,只有做好了异构调度,才能更好的发挥 AI SoC 的价值。
圈圈虫关于 深度学习模型在 CPU 上的速度/量化/调优 的内容在之前的水文中已经讲过一些,今天跨界来介绍下当前火热的 NPU 相关内容。
Tengine 完成正宗国产芯-良心大厂 AML、RK NPU 算子级适配,已在 A311D/RV1126 EVB 实现 PoC 验证和精度调优。
Amlogic NPU
晶晨半导体(Amlogic)创立于美国加利福尼亚圣克拉拉,并在圣克拉拉、上海、北京、深圳、台北、首尔和法国设有研发中心、支持和销售分支机构,专业从事高性能多媒体芯片的设计、研制和应用,现已成为全球领先的无晶圆半导体系统设计公司。
目前内置 NPU 的方案有:S905D3、A311D
Rockchip NPU
瑞芯微电子(Rockchip )成立于2001年,总部位于福州,在深圳、上海、北京、杭州、香港及台湾均设有分支机构,是中国专业的集成电路设计公司。
目前内置 NPU 的方案有:RK1808、RK3399Pro、RV1109、RV1126
好了,官方的解释完成。
2018年
第一次公布其 NPU 性能数据时,VGG16 居然能跑到实时(即 Inference Time < 30 ms)当时非常震惊。毕竟当年嵌入式端侧 SoC 级别能落地的 NPU 解决方案也就 HiSilicon 的 Hi3559AV100,当时的 NNIE 还只是单核心,VGG16 也才 60 ms。不乏当初也“中二”过,在知乎上脸都被打肿了
2019年
加入 OPEN AI LAB 的 Tengine 团队,全力投入到赋能 AI 芯片的工作中,加入我司的初衷之一是奔着 arm china 的 周易 AIPU 而来,结果再次事与愿违,居然首先接触到的是内置 NPU 的 3399Pro 开发板和 RK1808 的计算棒。虽然团队的宗旨很简单:赋能 AI 芯片,可实施起来缺异常费力,AI 芯片一般过于黑盒,既然是 ASIC 了,速度优化是不可能再优化了,那就让 AI 芯片更加易用吧!
NPU 模型适配
算法模型迅速、高效化的工业化落地,是当前行业的面临的一大问题。原本学术界与工业界就存在较大 Gap,加上 NPU 芯片的突然兴起,说是为了提高工业界的效率,事实上很多常规的的学术界模型都较难快速部署到 NPU 芯片上。
模型转换
芯片产品的迭代周期往往以年为计数单位,而学术界的各种骚操作 Operator 是以季度为单位在更新,这也是 NPU 芯片模型适配的一个怪相,兼容性最好的模型是 Caffe,也许芯片设计之初只有 Caffe 可做参考。
然而现在早已是 TensorFlow、PyTorch、MXNet……的世界了。

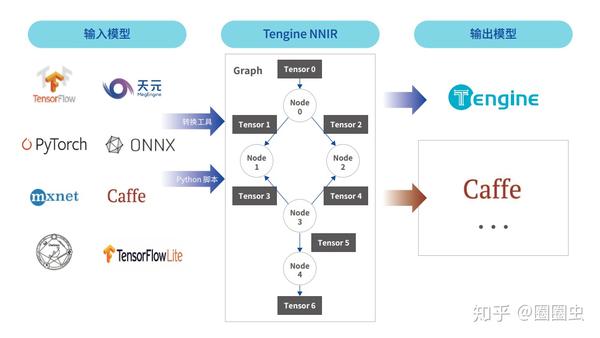

ONNX 之殇
ONNX 的设计初衷是很美好的,但是 PyTorch 已开始力推 Torchscript,TensorFlow2 的 MLIR 也有后浪之势。而当你辛辛苦苦转好 ONNX 模型,拿出 Netron 打开后出现下面情况,内心 OS 是很糟糕的。让 NPU 部署这玩意儿?!
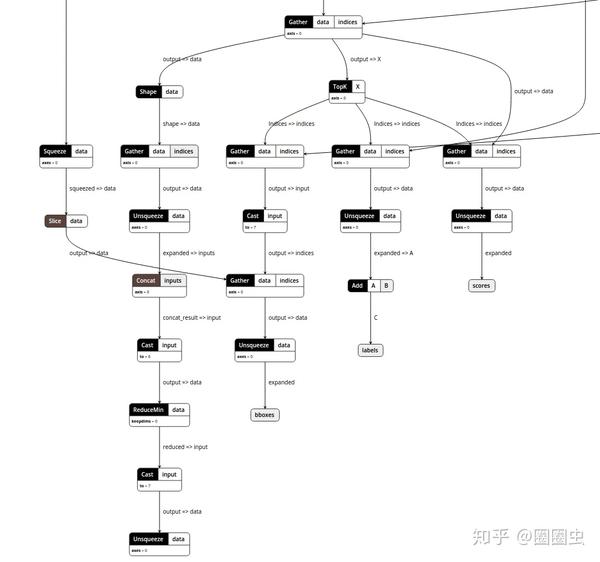


如果 CPU 能跑起来,GPU、NPU 就能跑起来,那该多好。
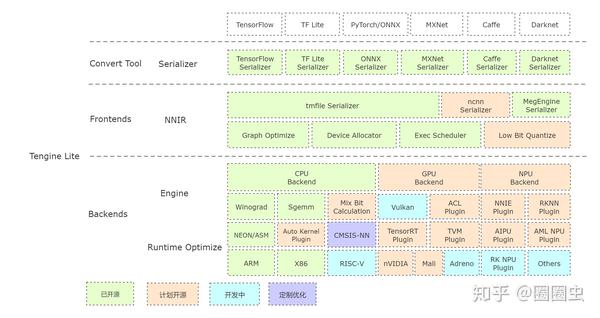

异构计算
所谓:“即使性能猛如虎,还得大师手切图”,大概也侧面推动了 NVIDIA 股价再创新高。
模型适配,Tengine 团队是专业的,闲来大佬太肝了,果然大(dan)佬(shen)才是生产力啊

灵活调度
在模型加载的时候,根据后端硬件的情况,自动完成 subgraph 生成,尽量减少算法工程师手工切割模型,促进算法模型快速迭代、落地。
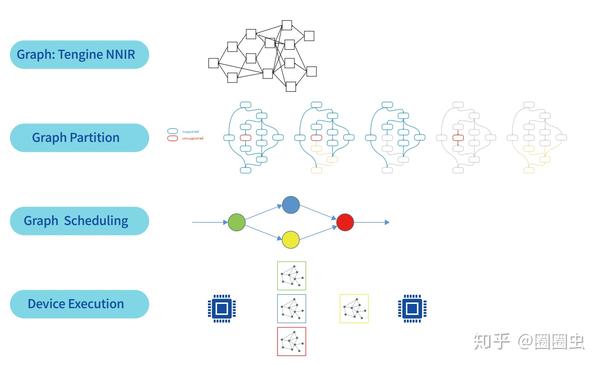

各尽其责
- 算力需求大、操作固定的骨干网络由 NPU 出力;
- 算力需求低、操作风云变幻的处理由 CPU 断后。
精度调优
啥?NPU 精度还能调优?
市面上的 NPU,大概率采用 8bit 整型量化。既然量化,必然导致精度下降。由于 NPU 是个黑盒子,模型适配尚且有点难度,这下精度又掉了!是非常打击部署同学的耐心的。还好量化模型精度调优,圈圈虫略懂一些。
离线量化
下面是基于 RK1808 的神经网络计算棒的离线精度调优初步(疫情期间,Tengine 组的 HH小哥哥为了消磨无聊时间),精度调优工具经过努(jia)力(ban)已无缝迁移到 RV1126,一劳永逸了(以下表格测试时间为 2020年Q1 非官方的测试结果,随着离线量化算法的不断演进,芯片厂商官方提供的量化工具精度会越来越好,再这里就不做详细对比)。
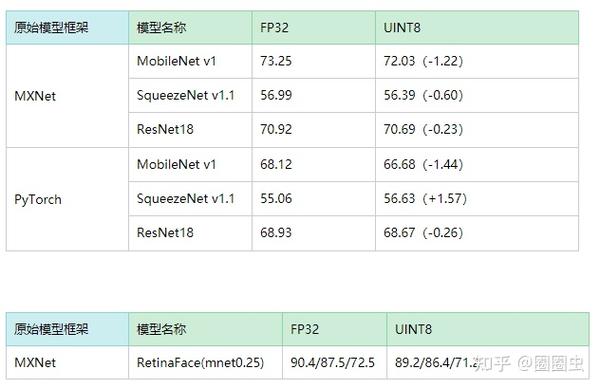

离线量化,方案千奇百怪。最终的精度效果也各有千秋,只能说 Google 的 TensorFlow 害人不浅,到现在还在想修改量化方案,这让后面的 NPU 厂商非常头大。如果能将优秀的 CPU Int8 量化精度无缝迁移到 NPU,那该多好。


量化训练
虽然圈圈虫也实现过基于 Caffe、MXNet、PyTorch 等训练框架的量化训练插件开发,单纯从精度恢复效果来看,效果还行。而实际落地项目,需要算法工程师高度配合,修改原有的训练脚本,绝大多数的炼丹师是拒绝的(我也不知道为啥,也得加钱?)。大师说过:量化训练需要的专家经验太多,初学者是很难在短时间内有收益的。只能作为精度调优的最后手段。

2020年
又回到了 RockChip 的故事了。原本应该 2020Q1 量产的 RK3588(国产最强 AI 广告面板机……)由于疫情的原因无限期 Delay,据说 2020Q4 应该稳了(希望没有立 Flag 吧)。而在今年的 6 月份,Rockchip 发布了 RV1109/RV1126 两款 高低搭配的 IPC 产品,其中的 NPU 部分采用了新一代 NPU 架构,从目前初步评测的数据得知,优化了分离卷积的推理性能,常规端侧小模型(采用 mobilenet backbone 的网络)表现优势明显。
通过各种渠道大佬,有幸获得到 EVB 板和 38 板(所谓 38 板,就是再加个 Sensor 模组,再加个塑料外壳,就是 IPC 整机啦!)


后 NNIE 时代
三十年河东三十年河西,由于复杂的原因,国内 AI 芯片市场又将迎来新一轮洗牌,Tengine 团队将始终致力于服务 AI 芯片快速落地,同时拥抱开源、开放的精神,后续会陆续分享当前的工作经验,减少大家踩坑几率。

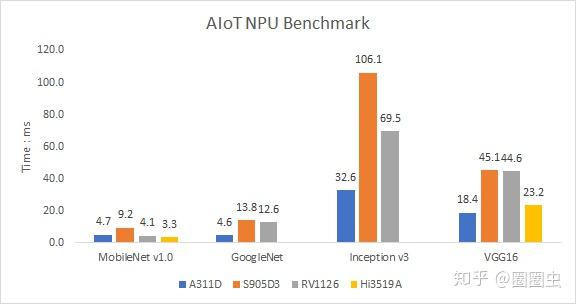
算力对比

编解码对比


江山代有才人出,各领风骚数百年。后续我们会开放基于 A311D 平台的 NPU 评估 demo,感兴趣的朋友可以关注我们的 Github 社区最新动态。
我是 圈圈虫,一个热爱技术的中年大叔。快加入 OPEN AI LAB 开发者技术 QQ 群(829565581)来找我吧!溜了~~
入群秘令:CNN
