
9978 方言音系/韵母“存古度”的一种定量描述

声明:本文结论不代表作者支持“粤语更正统”、“粤语就是古汉语”等观点。为防止断章取义,本文禁止转载。
在音韵学科普的领域,总有一些争吵不休的问题,其中一个就是哪种方言的音系/韵母更“存古”。例如,很多人主张粤语的音系,尤其是韵母更“存古”,理由是很多古诗词用粤语读仍然押韵,用普通话读则不押韵了。当然,很多圈内人士是反对这种武断的观点的,论据包括:
- 用普通话读押韵,而用粤语读不押韵的诗也是有的,比如题图里那首《悯农》;
- 古诗词押韵并不能表明“存古”——如果一种方言退化到所有字的韵母都一样了,那么用这种方言读古诗词则会完全押韵;
- 粤语尽管韵尾保存得好,但介音丢失得一塌糊涂,主元音的改变也比较严重,跟普通话半斤八两。
然而,“用粤语读古诗词更押韵”这种感性认识,似乎也并不是空穴来风(此处用的是新词义)。那么,粤语的音系/韵母到底是否比普通话更“存古”,如果是,差别有多大?要回答这些问题,必须进行定量分析。
我们来看一看,上面两方争吵时使用的论据,有没有什么比较有启发性。正方论据“古诗词用粤语读仍然押韵”,可以理解成“存古”的一个标准是“古代相同的韵母,现在也相同”。而反方用一种假想的、退化到只剩一种韵母的方言来反驳,其背后的道理是,“存古”的另一个标准应该是“古代不同的韵母,到现在也不同”。换句话说,一种“存古”的方言,其音韵特征应当没有明显的分化或合并,根据古时候的韵母,应当能够基本确定现在的韵母,反之亦然。
上面这句话,让我想到了信息论中的一个概念——互信息(mutual information)。它描述的是两个随机变量的关系,直观的理解,就是知道了一个随机变量,能够提供多少关于另一个随机变量的信息;或者说,两个随机变量携带的信息中,有多少是重复的。如果我们把古汉语的音节/韵母和现代方言的音节/韵母看成两个随机变量,那么“互信息”就可以作为方言音系/韵母“存古”程度的一种量度。
“互信息”的数学表达是这样的。设一个离散的随机变量X有n种可能的取值,取得第i种值的概率为p_i,则X的熵(entropy)定义为:
- H(X) = -\sum_{i=1}^n p_i \log p_i
熵代表了一个随机变量携带的信息量;如果对数的底取2,则熵的单位为比特(bit)。考虑另外一个随机变量Y,同样可以算出它的熵H(Y)。我们还可以考虑X、Y的联合分布以及它的熵H(X,Y)。如果X与Y相互独立,可以证明H(X,Y) = H(X) + H(Y)。一般情况下,H(X,Y)会小于H(X) + H(Y),这是因为X与Y是有关联的。其中少掉的那部分,就是X与Y的互信息:I(X;Y) = H(X) + H(Y) - H(X,Y)。互信息可以理解成X和Y所携带的信息中重复的部分,见下图。
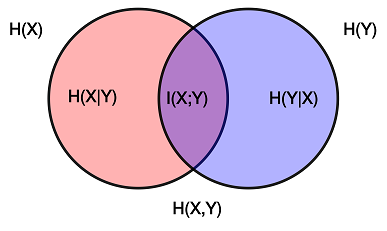
用“互信息”作为方言存古程度的量度,就可以了吗?其实不行。互信息是上图中的紫色部分,但红色和蓝色部分的大小也同样重要。这两部分的大小称为条件熵(conditional entropy),它们表示的是,知道一个随机变量之后,另一个随机变量还有多少不确定的成分。我们想象这样一种方言,它的每一个字的韵母都不同。这样,古汉语韵母包含的信息,就完全涵盖在这种方言的韵母中,互信息等于古汉语韵母本身的信息量,达到最大值,但显然我们不会认为这种方言是“存古”的,因为它的分化太严重了。如果用X表示古汉语韵母,用Y表示这种方言的韵母,则上面的现象可以概括为H(Y|X)过大。在衡量方言存古程度的时候,必须考虑两个条件熵的大小,两个条件熵分别表征了方言音节/韵母的合并和分化程度。
综合考虑互信息和条件熵,可以用如下两个量来描述方言的存古程度:
- 距离:d(X,Y) = H(X|Y) + H(Y|X),单位为比特。其直观含义是,只包含在一种语言而不包含在另一种语言中的信息量有多少。距离越小,存古程度越高。
- 相似度:s(X,Y) = I(X;Y) / H(X,Y),无单位,居于0和1之间。其直观含义是,两种语言共有的信息量占总信息量的比例。相似度越大,存古程度越高。
可以证明,上面的距离是真正的距离,即它满足非负性、对称性、三角不等式。上面的距离和相似度,不仅可以用于衡量一种方言与古汉语的差异,也可以衡量两种方言之间的差异——古汉语在这里的地位并不特殊。
下面是实验时间。
实验所用的数据,取自我的安卓应用“汉字古今中外读音查询”的数据库。收字范围为Unicode从U+4E00到U+9FA5的汉字中,中古音、普通话、粤语读音俱全的汉字,计11182个。因为数据库中只收了繁体字的中古音和粤语读音,所以不用担心简繁体带来的系统偏差。根据这些数据,我分别统计了三种语言中的音节和韵母的分布以及两两的联合分布,并计算了它们的熵、互信息、条件熵。对于多音字,我在统计一种语言的分布时,是把它拆成n个字来对待的,每个字的权重为1/n(n表示这个字的读音个数);在统计联合分布时,则把它拆成nm个字,每个字的权重为1/nm(n、m分别表示两种语言中这个字的读音个数)。
先来看普通话和粤语音系整体的存古程度,此时随机变量代表整个音节(包括声母、韵母、声调):


可以看出,普通话的音节总数小于粤语,与中古汉语的互信息量也小于粤语,这表明普通话音节的合并程度高。但是,已知中古汉语音节后,普通话音节的条件熵H(Y|X)小于粤语,这表明粤语音节的分化程度高。二者抵消一部分,最终的结果是普通话与中古汉语的距离略大于粤语与中古汉语的距离,相应地相似度则略小。但总体来说差异不明显,尤其是距离——中古汉语、普通话、粤语三者之间两两的距离都差别不大。
再来分析韵母。普通话和粤语的韵母比较好界定(普通话中以y、w开头的音节算作零声母,整个音节作为韵母,如ya的韵母算作ia)。而中古汉语的“韵母”定义则乱象丛生,比较模糊:
- 有些韵横跨了多个等呼,比如戈韵有戈一合、戈三开、戈三合;
- 有些摄、等里开合口同韵,如唐韵;有些摄、等里开合口却分韵,如寒、桓韵;
- 有些韵还有重纽现象。
我采用了两种统计方法:一是以《广韵》本来的韵目为韵母;二是把横跨多个等呼的韵拆成多个韵母(但重纽韵未拆分)。
以《广韵》本来的韵目为韵母的统计结果如下:


这一次,差距拉开了。以中古汉语为参照物X,表征合并程度的条件熵H(X|Y),普通话明显大于粤语;表征分化程度的条件熵H(Y|X),普通话与粤语的差别不大。其结果就是,普通话韵母与中古汉语韵母的距离,大于粤语韵母与中古汉语韵母的距离,相似度则相应地小。普通话韵母与中古汉语韵母的距离,甚至大于普通话韵母与粤语韵母的距离。
把《广韵》韵目拆分到等呼的统计结果如下:


结论跟不拆韵时差不多。但有一点值得注意:拆韵后,普通话与中古汉语互信息的涨幅(0.2640比特),大于粤语与中古汉语互信息的涨幅(0.1787比特)。拆韵的主要效果是分清开合口,上面的数据说明,分清开合口更有助于确定普通话的韵母。这也就印证了普通话的介音保存得比粤语好。
综上所述,可以得到如下几点结论:
- 在音节层面,普通话的合并程度更高,粤语的分化程度更高。综合来看,普通话与中古汉语的距离略大于粤语与中古汉语的距离,但差别不明显。
- 在韵母层面,普通话的合并程度高于粤语,而分化程度差不多。普通话的介音保存得比粤语好。
需要强调的是,本文的结论必须谨慎对待,因为:
- 本文的研究方法只能体现音系的“存古”,不能体现音值的“存古”。一种方言可能完全保留古汉语的音系,但音值面目全非,用本文的方法来研究,其结论会是“完全存古”。
- 本文结论并不能直接推导出“粤语读古诗词比普通话更押韵”。这是因为在诗词中,音值相近的韵母可以通押,导致韵母的类别大幅减少。
另外,本文的统计方法也有许多改进的余地,比如:
- 没有考虑汉字出现的频率,让常用字具有更多的权重。按字频加权的一点好处是,统计结果对选字范围的敏感性会降低,因为处在选字范围边缘的字,一般都是生僻字。
- 对多音字的处理十分粗暴。当一个字在多种语言中都是多音字时,我的处理方法实际上假设了这些读音都是独立的,而实际上它们之间往往有对应关系。
实际上,更好的统计方法,不是以字典作为数据来源,而是使用实际的语料库。一方面,语料库足够大之后,各个汉字的频率就能体现出来;另一方面,如果语料库中多音字的读音都按上下文确定,就能完全避免多音字的问题。但是,构建这样的语料库是一项庞大的工程,不是一个人一朝一夕能完成的,我只能退而求其次。这也就影响了本文结论的可靠性——如果真的用上述理想的语料库来做统计,结论完全可能发生变化。
再次声明:本文结论不代表作者支持“粤语更正统”、“粤语就是古汉语”等观点。为防止断章取义,本文禁止转载。
