
Web crawler with Python - 04.另一种抓取方式

好了,到上一篇博客,我们已经能够顺利从网站上抓取一些简单的数据,并将其存储到文件中。但是在抓取网页的时候,有时候会发现HTML中没有我们需要的数据,这时候如何是好呢?
-------------------------------------
我们的目的是抓取拉勾网Python分类下全国到目前为止展示出来的所有招聘信息,首先在浏览器点击进去看看吧。如果你足够小心或者网速比较慢,那么你会发现,在点击Python分类之后跳到的新页面上,招聘信息出现时间是晚于页面框架出现时间的。到这里,我们几乎可以肯定,招聘信息并不在页面HTML源码中,我们可以通过按下"command+option+u"(在Windows和Linux上的快捷键是"ctrl+u")来查看网页源码,果然在源码中没有出现页面展示的招聘信息。
到这一步,我看到的大多数教程都会教,使用什么什么库,如何如何模拟浏览器环境,通过怎样怎样的方式完成网页的渲染,然后得到里面的信息......永远记住,对于爬虫程序,模拟浏览器往往是下下策,只有实在没有办法了,才去考虑模拟浏览器环境,因为那样的内存开销实在是很大,而且效率非常低。
那么我们怎么处理呢?经验是,这样的情况,大多是是浏览器会在请求和解析HTML之后,根据js的“指示”再发送一次请求,得到页面展示的内容,然后通过js渲染之后展示到界面。好消息是,这样的请求往往得到的内容是json格式的,所以我们非但不会加重爬虫的任务,反而可能会省去解析HTML的功夫。
那个,继续打开Chrome的开发者工具,当我们点击“下一页”之后,浏览器发送了如下请求:
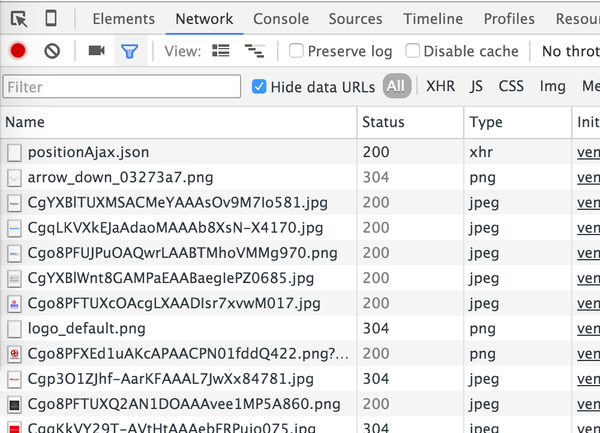

注意观察"positionAjax.json"这个请求,它的Type是"xhr",全称叫做"XMLHttpRequest",XMLHttpRequest对象可以在不向服务器提交整个页面的情况下,实现局部更新网页。那么,现在它的可能性最大了,我们单击它之后好好观察观察吧:
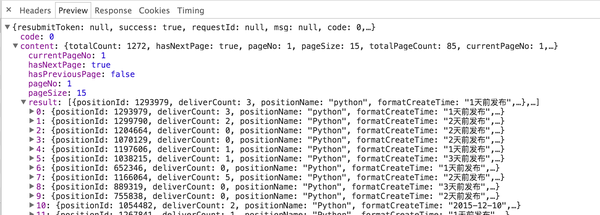

点击之后我们在右下角发现了如上详情,其中几个tab的内容表示:
- Headers:请求和响应的详细信息
- Preview:响应体格式化之后的显示
- Response:响应体原始内容
- Cookies:Cookies
- Timing:时间开销
通过对内容的观察,返回的确实是一个json字符串,内容包括本页每一个招聘信息,到这里至少我们已经清楚了,确实不需要解析HTML就可以拿到拉钩招聘的信息了。那么,请求该如何模拟呢?我们切换到Headers这一栏,留意三个地方: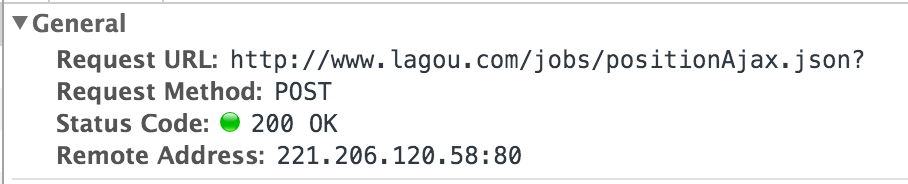

上面的截图展示了这次请求的请求方式、请求地址等信息。


上面的截图展示了这次请求的请求头,一般来讲,其中我们需要关注的是Cookie / Host / Origin / Referer / User-Agent / X-Requested-With等参数。
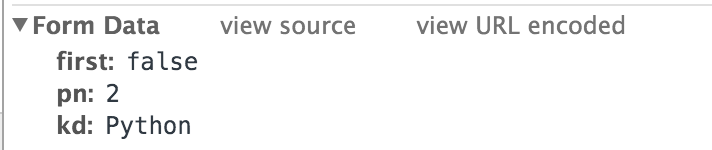

上面这张截图展示了这次请求的提交数据,根据观察,kd表示我们查询的关键字,pn表示当前页码。
那么,我们的爬虫需要做的事情,就是按照页码不断向这个接口发送请求,并解析其中的json内容,将我们需要的值存储下来就好了。这里有两个问题:什么时候结束,以及如何的到json中有价值的内容。
我们回过头重新观察一下返回的json,格式化之后的层级关系如下:


很容易发现,content下的hasNextPage即为是否存在下一页,而content下的result是一个list,其中的每项则是一条招聘信息。在Python中,json字符串到对象的映射可以通过json这个库完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
json字符串的"[ ]"映射到Python的类型是list,"{ }"映射到Python则是dict。到这里,分析过程已经完全结束,可以愉快的写代码啦。具体代码这里不再给出,希望你可以自己独立完成,如果在编写过程中存在问题,可以联系我获取帮助。
小结
这篇博客介绍了有些数据不在HTML源码中的情况下的抓取方法,适用于一部分情况。对于数据的存储暂时还是在使用文件。到下一篇,我们将使用MongoDB存储数据,所以在这之间,希望你可以先在本机安装并配置好MongoDB。
