
网络编程(八):再谈Sendfile(2)

整个互联网本质上讲就是一个庞大的数据传输网络,不同的应用对于数据传输有不同的要求:有的关注传输的吞吐率,也就是速度;有的关注消息的可靠性、完整性;有的要求消息要有低延时。在基础设施固定的前提下,但作为一个程序设计者、一个运维人员、一个网络工程师,我们的目标都是尽可能的降低成本,提高网络服务质量。
而成本很多时候的体现就是对计算资源的消耗,其中最重要的一个资源就是CPU资源。虚拟化技术、vHost的发展让一台服务器硬件能够承载更多的站点沙盒。这样就使得传输数据时尽可能少的占用CPU资源变得更为重要。即使刨除计算成本的考虑,数据传输时CPU资源消耗的降低也能让延时敏感的应用受益良多(我们知道CPU消耗的少就是CPU处理用时少,从而让数据更加及时的到达用户端)。
Sendfile(2)在这个时代背景下于2003年前后被加入Linux Kernel,陆续在各大UNIX、Linux、Solaris平台上获得了支持。这个系统内核调用本身被设计出来是用来从磁盘到TCP协议栈拷贝数据用的,但也我们也是可以把它用来做两个文件之间的数据拷贝。
在Linux Kernel 2.6版本中,这个系统调用的原型是这样的:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
- in_fd 被打开是等待读数据的fd.
- out_fd 被打开是等待写数据的fd.
- Offset 是在正式开始读取数据之前应该向前偏移的byte数.
- count 是需要在两个fd之间“搬移”的数据的byte数.
也是由于推出的比较晚,POSIX还没有来得及规范接口,所以各个平台的实现稍有不同。所有就经常会见到类似下面的代码来做兼容性的宏定义:
/**
* @brief sendfile wrapper
*
* @see
* @note
* @author auxten <auxtenwpc@gmail.com>
* @date 2011-8-1
**/
#define ERR_RW_RETRIABLE(e) \
((e) == EINTR || (e) == EAGAIN || (e) == EWOULDBLOCK)
static inline int gsendfile(int out_fd, int in_fd, off_t *offset,
GKO_UINT64 *count)
{
#if defined (__APPLE__)
int ret = sendfile(in_fd, out_fd, *offset, (off_t *) count, NULL, 0);
if (ret == -1 && !ERR_RW_RETRIABLE(errno))
return (-1);
return (*count);
#elif defined (__FreeBSD__)
int ret = sendfile(in_fd, out_fd, *offset, *count, NULL, (off_t *) count, 0);
if (ret == -1 && !ERR_RW_RETRIABLE(errno))
return (-1);
return (*count);
#elif defined(__linux__)
int ret = sendfile(out_fd, in_fd, offset, *count);
if (ret == -1 && ERR_RW_RETRIABLE(errno))
{
/** if this is EAGAIN or EINTR return 0; otherwise, -1 **/
return (0);
}
return (ret);
#endif
}
摘自:gingko/gingko.h at master · auxten/gingko · GitHub
在sendfile(2)出现之前,我们想要把一个文件发送到socket上需要进行如下几个步骤:
- 调用read(2)函数,文件数据被copy到内核缓冲区
- read(2)函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write(2)函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
- 数据从socket缓冲区copy到相关协议引擎。
如下图所示:
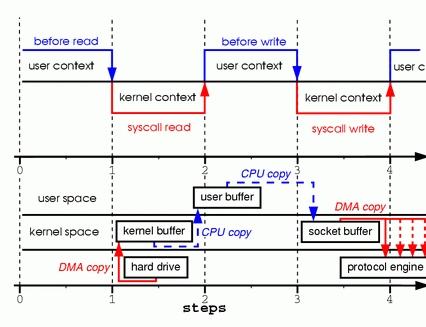

From: Zero Copy I: User-Mode Perspective
我们可以看到,在这个过程当中数据实际上是经过了四次copy操作:
硬盘 —> 内核buffer —> 用户buffer —> 内核socket缓冲区 —> TCP协议栈
写成伪代码大致是下面这样:
int out_fd, int in_fd;
char buffer[BUFLEN];
read(in_fd, buffer, BUFLEN); /* 系统调用, 会陷入内核态 */
write(out_fd, buffer, BUFLEN); /* 系统调用, 会陷入内核态 */
我们可以看到,相比sendfile(2),“Read & Write”方式带来的性能损耗主要有两点:
- 不必要的内存拷贝。
- 系统调用带来的额外的用户态/内核态上下文切换(Context Switch)。
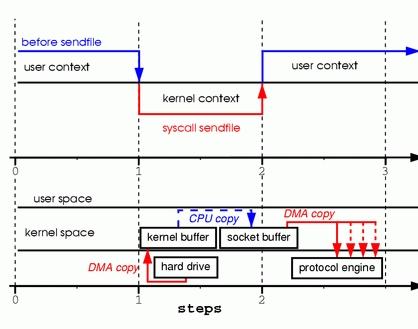
而我们知道,上下文切换涉及到非常多的CPU、内存堆栈的操作,会让分支预测失败率大增,所以频繁的上线文切换是高性能编程的大忌。类UNIX操作系统里都有一个系统命令vmstat可以展示当前系统的“Context Switch”的量(--system--下的cs列):
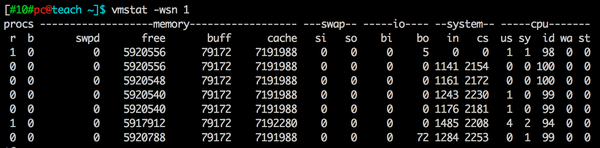

为了让大家对上下文切换的代价有个比较感性的认识,我们下篇文章将为大家详细的分析一下,敬请关注。
著作权归作者所有,任何转载请联系作者获得授权。
作者:auxten
链接:http://zhuanlan.zhihu.com/p/20768200

服务端开发群:365534424,本文仅授权51 Reboot相关账号发布。
