
知乎小数据分析 & Need help

0 介绍
- 这篇文章图片有点多,流量党请谨慎点开
- 如果只对数据分析感兴趣,可以直接跳到 2.1 节
- 如果你是太长不看党,但是你既然点进来了,能否请你帮我一个忙呢?如果愿意的话麻烦看一下第 3 小节,十分感谢
- 虽然题图是 Big data,但是因为数据量太小了只能算小数据分析
1 数据获取
在上一篇文章里,我提了一下 zhihu-OAuth 这个库并不适合做爬虫,但还是有几个原因还是让我去试着写了一下:
- zhihu-OAuth 在开发过程中需要稳定性以及性能测试,需要大量的,密集的使用场景
- @gaga salamer 在写知乎爬虫,并且向我介绍了 gevent 这个好玩的东西……我想学一哈
- 感觉我写了俩库了,还没真正写过爬虫……试一下不过分吧
随后我去读了 gevent 的文档,花了个几个小时写了个非常简单的爬虫……以下是运行时截图:


上面是运行时 log,左下是 error log,右下是用 socket 进行 IPC 控制后台运行的爬虫。
IPC 支持以下下命令:
- crawled,获取已爬用户数和速度
- left,获取任务队列里的剩余用户数
- worker,获取工作者线程情况
- pause,暂停爬虫
- run,继续爬虫
- stop,停止爬虫
爬的方法是,从我开始,BFS 层级展开关注的人。这样爬的话有一个特点就是,只会爬到有粉丝的用户,没有粉丝的用户是不会被爬到的(对不住了,大家 QAQ)。也就是说爬到的用户相对来说属于知乎里产出比较活跃的人。
技术栈大概就是用 redis 做队列和记录,gevent 协程,sqlite3 做数据库,zhihu-oauth 做底层爬虫。一共 10 个 worker,再加 1 个 db writer 10 秒一次 commit,还有一个 socket server 管 IPC。
我爬的东西很少,就是用户的基础信息,在后面会介绍的。
恩,这个爬虫我不准备开源,因为写的没啥水平……
2 数据分析
爬了多少天我忘了,因为写了暂停和继续功能,我基本是开一下关一下的,不过速度确实不快。我记得有个人 PHP 写的一天就能 100w 呢,最好的语言就是6!
好啦,正式开始吧,介绍一下数据先:
- 因为还没爬完,所以数据量比较小,2528099 个用户
- 记录的属性有:用户 ID,用户名,签名,性别,答题数,问题数,收到赞数,收到感谢数,关注了多少人,被多少人关注,学校,专业,行业,公司,职位
- 没有其他和答案,问题,话题,文章,评论,用户关注关系有关的数据
放一张小截图:

注意,由于爬虫工作时间太长,某些用户的资料可能不是最新的。
2.1 赞数排名前10
这个最简单也最老套了吧,相信有一大堆人做过。
SQL 语句:
select name, voteup_count
from user
order by voteup_count desc
limit 10结果:
Name upvote_count
张佳玮 2002014
肥肥猫 954649
朱炫 938887
ze ran 766117
恶喵的奶爸 735458
yolfilm 699539
寺主人 665168
唐缺 645618
vczh 590346
一笑风云过 568329

我就不艾特这些用户了,感觉艾特了对 Ta 们来说也只是一种打扰而已,没什么其他意义。
按感谢数量排名我就不贴了。
2.2 答案平均赞数排名前 5
SQL 语句:
select name, voteup_count, answer_count, (voteup_count/answer_count) as rate
from user
order by rate desc
limit 5结果:
用户名 总赞数 答案数 答案单价
Dr How 53917 1 53917
大树下的小孩子 53151 1 53151
宋冬野 34074 1 34074
森子大大 26914 1 26914
姚乐乐 46216 2 23108唔,这基本上就成了单一答案最高赞数排名了。
那我们加个限制,要求用户最少有 5 个答案吧,结果如下:
用户名 总赞数 答案数 答案单价
北京小风子 65770 6 10961
Jee Xin 80951 10 8095
era Eth 47790 6 7965
潜水的鱼 39600 5 7920
大儿童 66997 9 7444这几个用户答案的平均质量应该很精良~!佩服一下。
2.3 最喜欢关注人的用户
SQL 语句:
select name, following_count from user order by following_count desc limit 10
结果:
"Neaton" "41600"
"Hannibal Lecter" "16689"
"许鹏" "14629"
"唐晨" "11555"
"柳亚" "11216"
"谈无语" "10156"
"黄继新" "9256"
"徐是愚" "8532"
"陈溪" "7731"
第一名关注了 4w+ 用户,这动态刷的过来么QAQ
2.4 城市用户数排名
SQL 语句:
select address, count(*) as c
from user
group by address
order by c desc
limit 38由于弄了前 30 名,我就不贴文本结果了,只贴图表(下同):
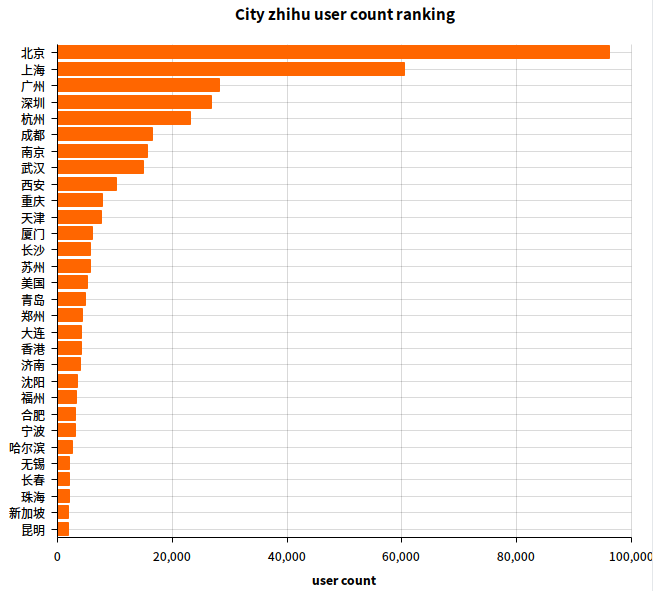

基本上就是省会城市名单?
话说北上广被叫做北上广是有道理的呀~
另外,美国在中间,这还没算填的是美国城市或州的同学们,如果算上应该还能上升个几名吧。另外新加坡也上榜了。
2.5 行业用户数排名
SQL 语句:
select industry, count(*) as c
from user
where industry != ''
group by industry
order by c desc
limit 30图表如下(请点开大图):


第一互联网,第二计算机软件……没啥意外的,不过竟然有 10000 以上的 「政府」行业的用户QAQ,麻麻我好怕!
唔,而且前 30 名医疗相关的竟然只有个制药?稍微有点担忧……
好啦,我只给图,详细的分析不是我强项,交给你们了。
2.6 大学用户数排名
SQL 语句:
select school, count(*) as c
from user
where school != ''
group by school
order by c desc
limit 30
同上,文本就不贴了,结果图如下:
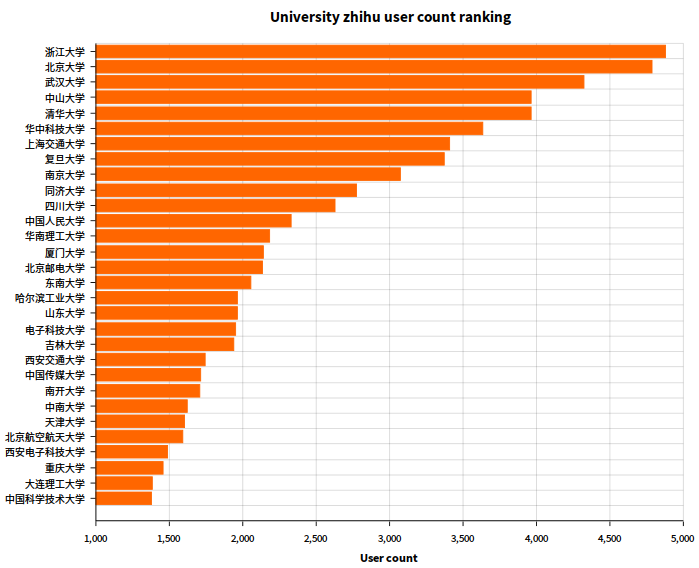

欸,不知道从哪开始吐槽……恩,大家快来找找自己的学校有木有在图里呗~~
2.7 主修专业用户数排名
嘛,就是大学里的专业辣~
SQL 语句:
select major, count(*) as c
from user
where major != ''
group by major
order by c desc
limit 30
结果图:
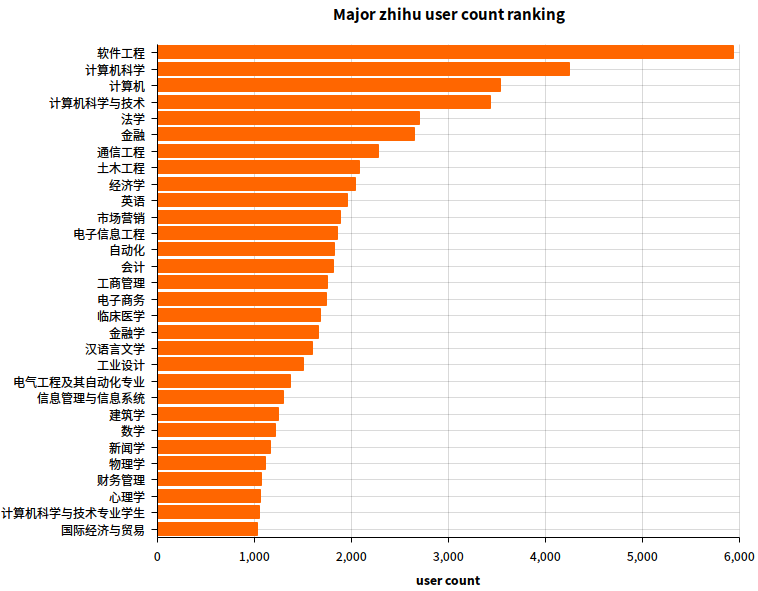

果然不出所料,我大计算机威武。但是因为大家用词不同,被分成了第2、3、4 以及第 29,来看看如果合并之后会是啥样吧。对了金融也有个别名金融学,但那些财务管理,工商管理,经济学之类的……我也不知道算不算金融,就不合并了。
以下是合并了之后的图:
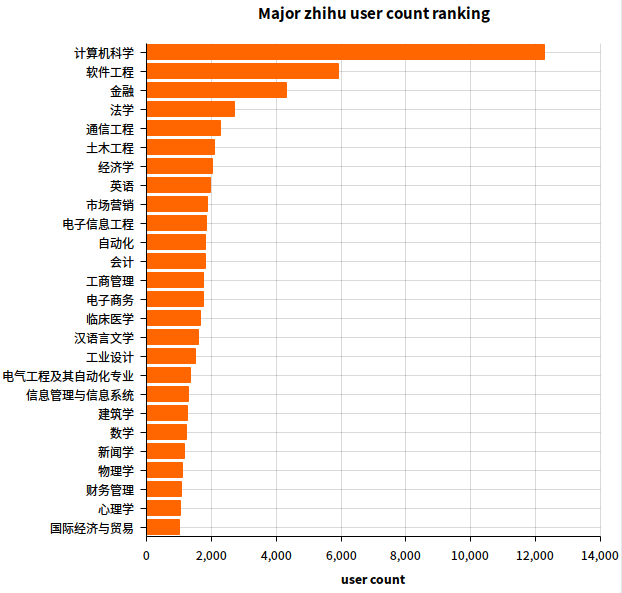

2.8 公司用户数排名
SQL 语句:
select company, count(*) as c
from user
where company != ''
group by company
order by c desc
limit 30
结果图:
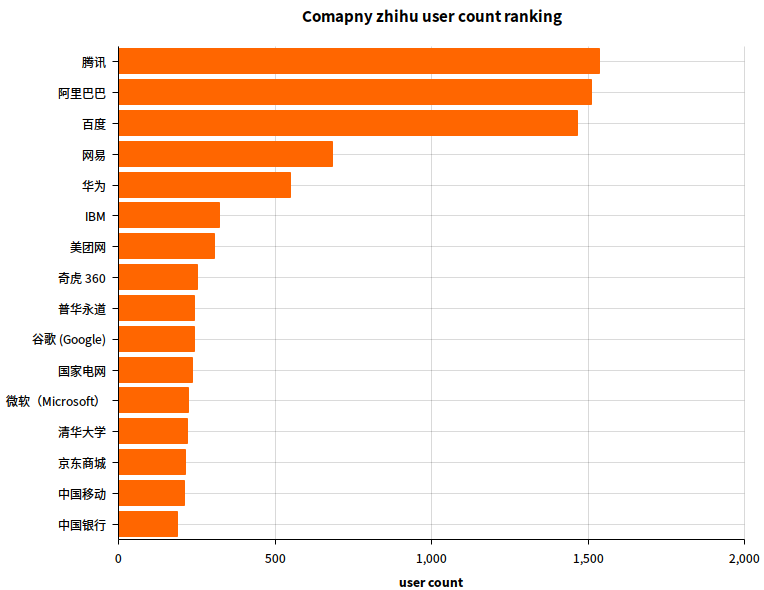

- 我对数据进行了合并处理,比如把 「阿里巴巴集团」,「阿里巴巴」,「支付宝」,「淘宝网」等合并为「阿里巴巴」
- 删除了「无」,「无业」,「自由职业」的数据行。
- 删除了「学生」,「银行」,「教育」,「互联网」等笼统的,不是特定公司的数据行。
嘛,如果你想看处理之前的数据,点这里。
唔,看来 BAT 以后得叫 TAB 了。
然后,普华永道是啥公司QAQ;国企好厉害上了三个;清华大学实力抢镜(company 里填清华大学的应该是老师们吧,有这么多么)。
2.9 男女比例相关
首先是知乎的整体性别比例:


select gender, count(*) as c
from user
where industry like '%软件%' or industry like '%计算机%' or industry like '%互联网%' or industry like '%程序%' or major like '%软件%' or major like '%计算机%' or major like '%互联网%' or major like '%程序%'
group by gender
order by c desc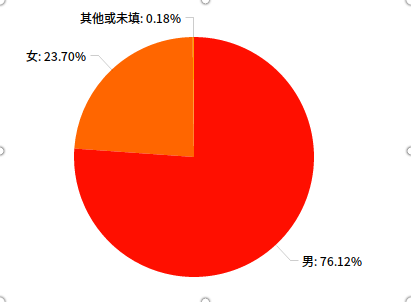
然后是「清华大学」,「北京大学」,「南开大学」(你够了)三所学校的男女比例:
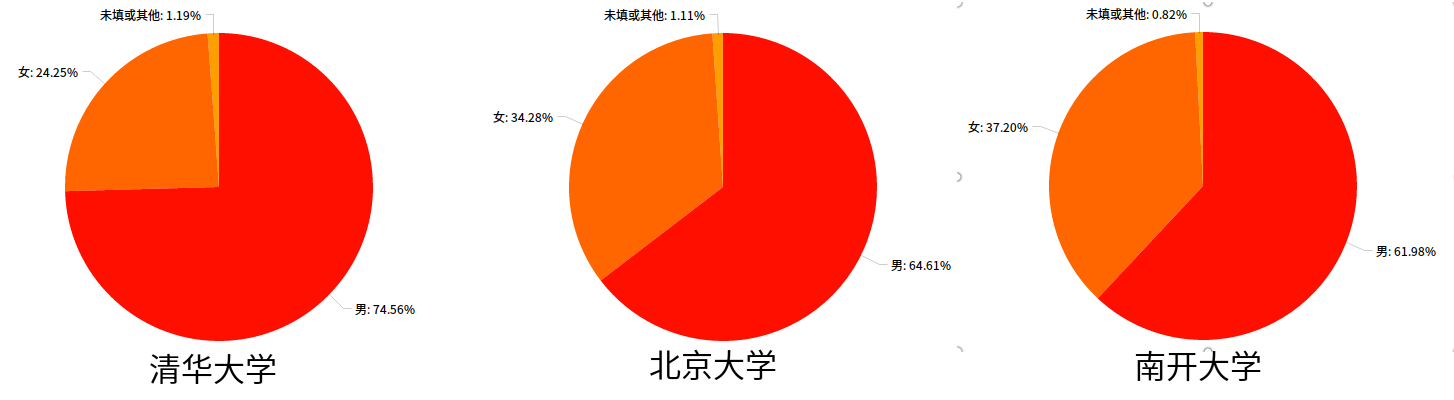

唔,我不说话。
2.10 烂大街昵称排行
不知道怎么处理了,随便来个趣味性的东西吧~~
SQL 语句
select name, count(id) as c
from user
group by name
order by c desc
limit 30
结果图:


(更新:根据大家的评论和私信,这些「已重置」是因为违反知乎规范而被封禁的用户们)
额,丁丁这个昵称也这么普遍的么,第 9 诶……(扶额,不要问我为什么要专门提一下这个名字……
对了,除了这些,我在爬取的过程中发现过很多个叫「送零食了」的用户,所以针对这个用户名我做了一次查询……结果让我大吃一斤 QAQ:
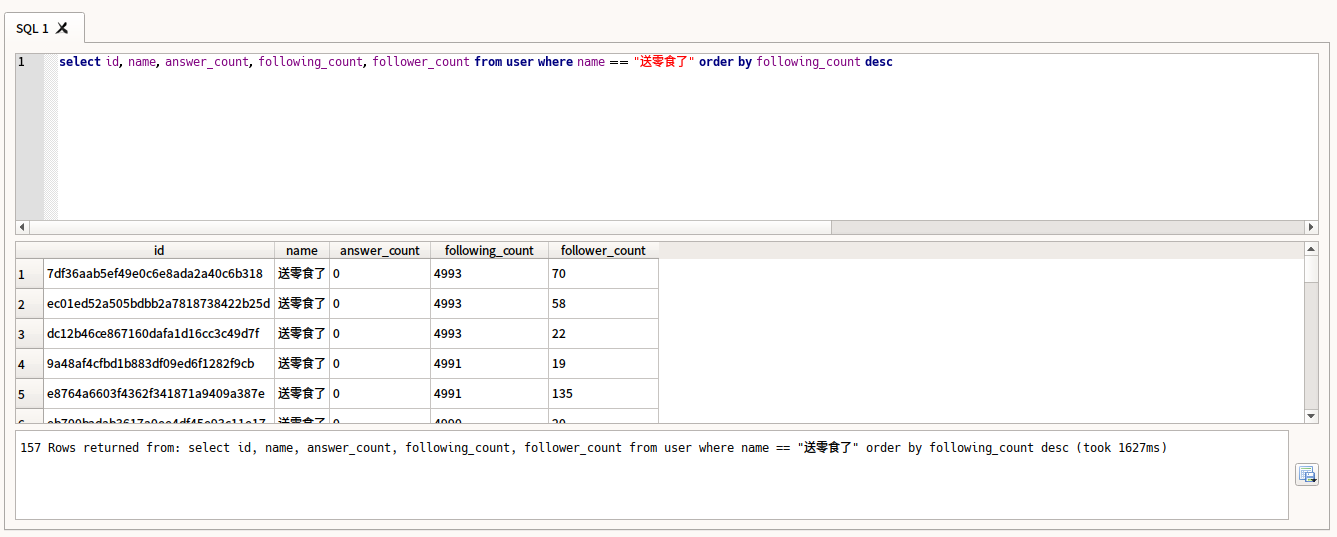

- 都叫「送零食了」(废话!
- 都没回答过问题
- 都关注了差不多 5000 个用户
- 至少被一个用户关注了(要不然我的爬虫爬不到的,所以可能还有很多没人关注的「送零食了」帐号
综上,这肯定是某个人(或者某个团体),为了某一目的弄出来的一批帐号。但他们关注这么多人干啥呢?而且这些不回答问题的人竟然也被几十个人关注了,唔,一个迷之团体。话说他们应该没送过零食吧?
(更新:根据用户@孙达云 所说:「送零食了」是一个广告作弊团伙,通过批量关注人来骚扰和推广自己的产品公众号,之前已经被打击过好几次了)
3 需要你的帮助
看了上面这些图有没有觉得数据处理还挺好玩的呢?
然而写完这篇文章我深刻的感觉到,作为一个头脑简单的程序宅,我能想到的数据处理方式实在太简单了。而且就算我处理出来了,我对分析它们也没什么想法……
鉴于以上几点,再加上经常听说学长学姐们想写知乎分析相关的论文还是啥的,我觉得这些数据在我手上简直是浪费。虽然目前只有 300M 左右,完全不能称得上是大数据……但是给同学们做一些实验,或者前期预备分析的话还是能有点作用吧。
本着为科研献一份力的想法,我有在数据全部获取完成之后把这个数据库公开免费给大家使用的想法。
但是!
在公开之前我有几个问题需要搞清楚:
- 分享这种「用户公开的资料(详见上一节)」的数据集是否侵犯知乎公司的任何权利,是否侵犯知乎用户的任何权利?
- 如果我删去数据库中可以定位到某一用户的属性(也即用户 ID,用户名,一句话介绍三项),问题一的答案是否会改变。
- 如果发布不侵权,我该以何种方式,何种协议,在何处发布这种数据集。
- 我对发布出去的数据的控制权有哪些?比如我是否可以限制数据不可被商业使用?
这几个问题都很重要。但是我的法律知识,讲真,没有细致的了解到这种地步,所以我需要大家的帮助。
如果你对这份数据感兴趣,而且想帮助我,那么:
- 如果您处于法律行业:能否向您询问一下以上几个问题的答案,评论或私信回复均可,感谢。
- 如果您有法律行业的朋友:让他看到这篇文章吧,点赞,评论 @Ta 或者直接分享均可。
- 以上都不符合:愿意的话点个赞帮忙扩散就行,感谢。
啊对了,之前已经说过,由于是 BFS 展开关注的人,所以占知乎用户大部分的「无人关注」的用户并不包含在数据库中。如果你想用这个数据库的资料做一些统计学方面的分析,请注意这个样本特征哟。
4 尾巴
这篇文章好像挺长的,谢谢你看到这。
作为你看完全部的奖励,你可以提一个分析请求,比如「我在我们学校的知乎用户中,被赞数量排第几」,「我校知乎用户的男女比例是多少」,「我所在城市有多少知乎用户」,「和我同名的知乎用户有几个」之类的。
不过你得把需求描述的足够清晰,前面的「我校」「我所在城市」等占位符用真实参数替换。
用 SQLite 的 SQL 语句提出请求的同学优先处理。
不过我最近想干的事有点多,可能没法每个人的要求都处理,见谅。
以上,Enjoy it!
本文章所有图表使用 Online Chart Maker 创建。
题图为CC0公有领域图片,来自 pixabay。
