
强化学习需要批归一化(Batch Norm) 或归一化吗?

深度强化学习算法 (DRL, Deep Reinforcement Learning Algorithm) 的神经网络是否需要使用批归一化 (BN, Batch Normalization) 或归一化(白化 whitening)?
深度强化学习不需要批归一化,但是可以用归一化。(长话短说)
归一化指的是深度学习的白化(whitening),这种操作可以让神经网络舒服地训练。本文讨论了 state action 这些输入值 以及 Q值(reward)这些输出值 的归一化问题。见下方目录。
舒服地训练:让神经网络的输入值,或者输出值尽可能靠近正态分布,从而让激活函数正常工作,随机初始化的参数不需要被夸张地调整,梯度下降优化器的超参数可以不调。
代码与对应的流程,如下:
- ElegantRL的网络基类,Critic网络,直接把归一化的均值和方差这些参数记录在神经网络里,即插即用
- ElegantRL的算法基类,函数 update_avg_std_for_normalization,根据训练中采集到的样本更新归一化参数
- ElegantRL的PPO算法,使用自动归一化,根据样本,调用函数,去更新Actor与Critic网络里的归一化参数
目录
- BN在RL中是如何失效的?
- 尽管RL不需要批归一化BN,但RL可以使用归一化(白化)
- 列举出学界对BN in RL 的讨论并点评
- 回复评论:「running mean std这个trick为何不用?我直接算出norm的定值」
- 回复评论:「奖励归一化有用吗?不能对reward归一化,但可以调整它的大小」
更新日志
2020-09-02 第一版,把语气改好一点
2020-10-09 第二版,回答评论区问题「reward需要归一化吗?」,将原来的第五节「列举出知乎对BN in RL 的讨论并点评」删掉, 换成「回复评论区的问题」
2021-01-28 第三版,增加Reward是否能归一化的讨论
2023-07-04 第四版,增加的状态和被拟合的Q值进行归一化的代码
BN在RL中是如何失效的?
在深度学习中BN很有用,特别监督学习:从训练集中抽取数据进行训练,通过随机抽取保证每个批次的数据符合独立同分布 (i.i.d.)。在这种稳定的训练环境下,BN可以计算出稳定变化的 mean 和 std 用于归一化。
- BN很有用,详见 Paper3 Batch normalization: Accelerating deep network training by reducing internal covariate shift. 2015. 这篇论文还解释了BN如何起作用。
- BN如何用,详见 从双层优化视角理解对抗网络GAN 的 3.2.3 批归一化BatchNorm 该怎么用?
在强化学习中,BN会失效:智能体 (agent) 训练越快,BN越难以发挥作用。与监督训练不同,RL的智能体需要通过「经验回放」技术与环境交互来获取训练数据,这些数据无法在开始前就准备好(给定)。所以RL无法为BN提供足够稳定的训练数据,每当训练数据发生变化(智能体搜集到大量新的状态state),而BN来不及适应新的数据,造成估值函数和策略函数相继奔溃(估值函数的估值不准,策略函数的策略退化)。
「经验回放」技术是什么?详见 DRL的经验回放(Experiment Replay Buffer) 用Numpy实现让它更快一点 的章节 1. 简单介绍「经验回放」
与环境交互来获取训练数据:因为智能体的动作会影响它下一步的状态 (state),因此要通过交互去收集数据。请注意有反例:如果金融RL的智能体控制的资金量少,那么可以认为它的交易行为不会对市场的大环境产生影响,因此在开始前就准备好(给定)金融RL的训练数据。


在有监督的深度学习中:
- 无论网络性能如何,我们一直都从训练集随机抽样得到稳定的训练数据(绿色箭头起点)
- 在训练数据稳定时,BN也趋于稳定,并算出稳定的均值和方差(绿色箭头终点)
而在深度强化学习中:
- 训练数据由智能体与环境交互从零开始收集,一开始就不稳定(橙色箭头起点)
- 经过长时间采样,训练数据变多,并趋于稳定(橙色箭头终点),BN也渐渐稳定
- 此时由于策略提升,智能体开始收集到新的状态,训练数据发生变化(红色箭头起点)
- 受采样数据中新状态的影响,之前BN算出的均值与方差不适应新的数据,因此开始波动,可是策略的性能在BN算出稳定的新值之前就已经发生了明显的下降。
- 策略性能下降,导致智能体与环境的交互受到影响,加剧了采样数据的不稳定,最终BN与采样数据双双滑落到不稳定的状态(红色箭头终点)。
- 循环以上过程 2~5
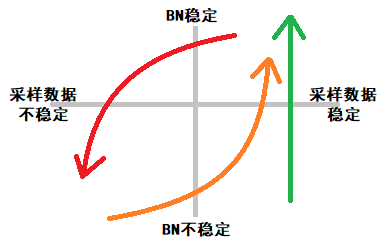
请注意,复现得差的DRL代码训练效率低,这味意着采样数据稳定,那么它用了BN反而能获得性能的提升(成绩垫底,发挥稳定,有较大提升潜力)。
传统的机器学习算法(如sk-learn里的),会超参数搜索技巧的人得到的结果差不多
深度学习算法可以在kaggle上办比赛,尽管大家的算法差不多,但是复现效果明显有差别(如自称YOLO5的算法的确比YOLO4好,可它本质上还是YOLO4)
深度强化学习的算法不同人类复现的效果天壤之别。“这个环境我用DRL的XXX算法跑不出来啊”,他可能把DRL算法当成是sk-learn里面那些算法了。
若你在外看到有人宣称使用了BN让他的DRL算法训练更快了,可能是因为他实现的DRL算法差。例如,对于完全相同的某个任务(如Ant-v0-pybullet):
- 好的DRL算法复现,平均训练0.5m步,加上BN,训练1m步,得出结论:BN不适合RL
- 差的DRL算法复现,平均训练10m步,加上BN,训练5m步,得出结论:BN适合RL
尽管RL不需要批归一化BN,但RL可以使用归一化(白化)
对训练数据使用归一化(白化 whitening):将输入神经网络的数值事先除以其均值和方差,让输入的张量符合标准正态分布。深度学习使用这种方法消除输入数据的量纲,随机初始化的网络在白化后的输入数据训练会很舒服:假如输入一个绝对值很大的数字 -10000,那么神经网络的wx+b的参数w、b需要经过很多步的更新才能从 0 → 1000,让这一层的输出也接近正态分布,才能让我们的激活函数ReLU、Tanh等正常工作。因此深度强化学习也可以对输入数据进行白化操作,具体操作如下:
- 开始DRL的训练,然后将历史训练数据保存在经验回放 (relpay buffer) 里
- 训练结束后,计算 replay buffer 里 state 每个维度的均值和方差,结束整个训练流程
- 下一次训练开始前,对所有输入网络的state用固定的均值和方差进行归一化
- 重复一两次此过程
Critic一般以 state 和 action 作为输入,为何一般只对state做归一化而忽略 action?
在动作空间是连续的情况下,一个设计得好的环境,其 action 的均值方差最好接近0和1。要做到这点非常容易,例如我将动作空间定为 -1到 1。
「Reward需要归一化吗?」见下文。Reward不能归一化,但是可以成倍地调整其大小
此外,一边训练一边计算用于归一化的均值与方差是可行的。与批归一化不同:这里的归一化统计的不是某一批次的数据,而是统计了历史出现的所有数据,因此它在训练后期非常稳定。如下:
# https://github.com/zhangchuheng123/Reinforcement-Implementation/blob/master/code/ppo.py
# 详细过程去看他的代码
classRunningStat(object):
def mean(self):
def std(self):
class ZFilter:
def __call__(self, x, update=True):
x = x - self.rs.mean
x = x / (self.rs.std + 1e-8) # 用1e-5更保险
x = np.clip(x, -self.clip, self.clip)
return x然而,我自己从来不用 running mean std这个trick,因为我认为这个太耗费性能了。我直接手动地统计出 mean 和 std,然后在完全重新开始训练时,直接让 state 除以std 减去 mean 这两个常数,效果同样很好。详见下方「我不用 running mean std这个trick,我直接算出norm的定值」
还认为RL应该用BN?RLlib ray-project 这些开源DRL库都不用。知名的强化学习算法库:伯克利的Ray RLLIB、OpenAI的 baselines 等 都没有在他们的DRL算法中使用BN,这是有说服力的证据。若看到这里还有人认为RL应该使用BN,那么可能只有把深度学习当成是实验科学,并用实验数据和代码才能说服了,代码见 ElegantRL (中文名可能叫“强化学习库:小雅?) ,里面有各种DRL算法以及标准的训练环境。想要通过实践去检验的人,可以随便挑一个算法,在你自己认为合适的地方加上BN层,如下:
self.net = nn.Sequential(nn.Linear(state_dim, mid_dim), nn.ReLU(),
nn.BatchNorm1d(mid_dim), # 随便挑一个地方加上BN层
nn.Linear(mid_dim, action_dim), nn.Tanh(), )实验数据见下方论文截图。
4. 列举出学界对BN in RL 的讨论并点评
- 反方 Paper1, Paper2 的观点与我相同,认为不需要:
- 正方 Paper3, Paper4 认为RL需要BN
Paper1 认为RL不能使用BN
CrossNorm: On Normalization for Off-Policy TD Reinforcement Learning. 2019.10 "Results improve only little over those without normalization and often are substantially worse."
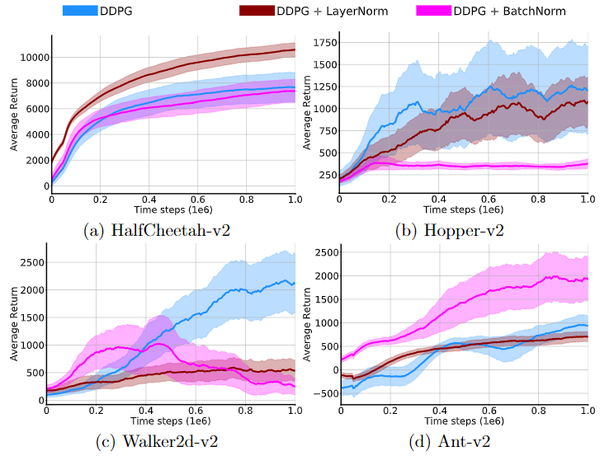

上面这篇文论发现在DRL 中使用BN 会带来很小的提升,但通常情况下甚至更差(训练更长久,且训练不稳定)。因此他们对BN 进行改进,提出了 CrossNorm。我在我的DRL 代码中尝试了BN,观测到的现象与他们描述的相符。此外,我尝试了他们的 CrossNorm 却没有得到显著的提升,我不推荐 CrossNorm。
Paper2 认为RL不需使用BN
Continuous control with deep reinforcement learning. ICLR. 2016 In Fig. 2, they compare "target network update" with "BN". the blue curve (with target network, not BN) is no significant difference between other methods with BN.
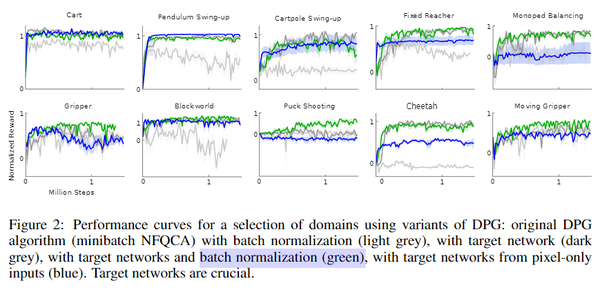

早在2016年,就有人讨论过 BN in RL 了,他们的结论也是:RL不需要使用BN,BN带来的性能提升微乎其微,远远不如 soft target update、(和后来的)Generalization Advantage Estimate 等技术。
Paper3 认为BN可以提升DL的训练
Batch normalization: Accelerating deep network training by reducing internal covariate shift. 2015. Cited by 17773 (till 2020-05-14)
在DQN提出用 Q network 取代 Q table,DDPG提出用 Actor Network 取代 DQN 的 贪婪策略 argmax 后,强化学习的无模型算法逐渐与深度学习进行结合。以至于知乎讨论的「强化学习」很大程度上是指「深度强化学习」(Deep RL)。
这篇文章只说:BN可以给深度网络带来提升,把它算成是正方已经很勉强。尽管深度强化学习也是一种深度学习,但是我个人认为深度强化学习中BN会失效。原因是深度强化学习(DRL) 不使用训练集进行训练,其训练数据没有深度学习那么稳定。详见本页面的「1. BN在RL中是如何失效的?」
Paper4 认为BN可以提升RL的训练
A Novel DDPG Method with Prioritized Experience Replay. IEEE SMC 2017. They cited Paper3 and claimed BN can improve DRL.
这篇文章在他们的DRL算法 DDPG中 尝试使用 BN,并认为用了更好(我反对此观点)。下面是我个人的吐槽:
- 为何在2017年出了A3C.2016 的情况下还要用 DDPG.2014?
- 若没有大厂背书(或是落地),没有开源代码的研究成果可视为不存在。
- Paper3 说的是BN可以提升DL,而没有直接说BN可以提升DRL,不应该犯这种错误。
- 这篇文章发表在 IEEE SMC 2017. 还好不是讨论强化学习的地方,这篇文章能过侧面说明了当时这几个审稿人可能需要先入门深度强化学习。
- 这篇文章把DQN的 Prioritized Experience Replay 和 DDPG 结合起来,这是A+B式的科研,其创新程度不高,可以作为优秀的本科毕业设计,更不该成为可发表的论文。在标题上写 Novel DDPG 不恰当。
回复评论区的问题(大家一起讨论,氛围很好,2021-01-28)
「running mean std这个trick为何不用?我直接算出norm的定值」
@tingxfan BN在实验上确实没怎么提升,不过running mean std这个trick在baselines里已经被广泛使用了吧,不知道作者为什么不推荐?
哈哈,期待另开一篇文章单独说说,为什么baselines很差,为什么rllib好。baselines虽然代码结构有点乱,但是性能一直还算有保证。
running mean std 这个trick是有用的,它记录智能体遇到的所有state的均值与方差。既然记录的是所有的state,那么随着训练的进行,它算出来的均值与方差会趋于稳定。因此:
- 在训练前期,它算出来的均值与方差不稳定,对RL的训练有影响,在简单任务上更明显(训练步数小于1e6)
- 在训练后期,它算出来的均值与方差几乎不变。那么我为何还要使用这个trick呢?
综合考虑,我不使用running mean std 这个trick,我会使用本文章节2提及的方法:直接用上一轮 experiment replay 中state计算出固定的均值与方差,这样一来:我能在训练前期归一化并保持均值方差的稳定(它们是常数,固然稳定),训练后期,我不需要让程序反复更新均值与方差,算法运行效率高一点点。
尽管做好一个细节只可以让算法运行效率高一点点。但是多个细节都做好,运行效率的提升是显而易见的。我自己写了一个强化学习库:小雅?ElegantRL ,里面尽可能地将不需要写在循环的东西都移除了,我只希望像有更多优雅的RL代码可以被人使用。至于为何要自己写一个新的,出发点和他们是一样的:stable-baselines 可能是觉得 baselines 不够稳定才不得已新开一个 fork ,可是stable-baselines 也不够稳定,而 RLLib却过于臃肿,高耦合度的代码让follow 的人感到头大。我也是无可奈何才决定从头开始构建一个库。(有时间会写一写我认为「baselines里面那些部分做得不好,需要如何改」)
「奖励归一化有用吗?不能对reward归一化,但可以调整它的大小」
@Heeger 请问reward (奖励)归一化有用吗?
首先,神经网络的输入和输出要尽量靠近正态分布,神经网络的激活函数生效范围、默认超参数、梯度下降算法等更加适应正态分布,因此神经网络在归一化(白化)操作后训练会比较舒服。
然而,我们不能对reward做归一化。使用了贝尔曼公式(极致简约版 Q = r + \gamma Q' )的强化学习不能让reward减去一个非零常数,这会破坏环境本身的 reward function,让Q值变成一个受执行步数影响的值。若 r+1 ,那么智能体只要呆坐不动,其总收益就能一直+1。反之 r-1 ,那么智能体会倾向于尽快结束游戏。可即便是每一轮训练步数固定的任务也不能让reward减去一个非零常数,因为折扣因子 \gamma 是一个略小于1的数,任何实数乘以折扣因子都会向0靠近一点点,它能让智能体用更多步数避开事件型的负收益,用更少步数靠近事件型的正收益。
尽管我们不能对reward做归一化,但我们可以让它乘上一个系数用于调整大小,详见的曾伊言:深度强化学习调参技巧:以D3QN、TD3、PPO、SAC算法为例 的【奖励比例】reward scale。
能对Reward做归一化的特例:如果你的agent无论采用何种策略,都不影响它在环境中的探索步数,也不影响它触发某些事件的步数,(例如训练环境的每轮训练 episode 的终止步数是固定的,或者奖励非常稠密),那么你可以让 reward 加减一个数值。
能对Reward(Q值)做归一化的特例:对Q值进行正则化操作不会破坏 Reward Function,效果不错。请注意,这里在Q值 上做norm,而不是在 reward 上做norm。
Stack Overflow 的回答 Normalizing Rewards to Generate Returns in reinforcement learning。曾伊言:如何选择深度强化学习算法?MuZero/SAC/PPO/等 的【PPO+GAE】。以下代码,见「强化学习库:小雅」的AgentZoo.py:
class AgentPPO():
...
def update_policy():
...
all__adv_v = (all__adv_v - all__adv_v.mean()) / (all__adv_v.std() + 1e-5) # advantage_norm:
...
