![[学习笔记] Neural Image Caption(NIC)](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[学习笔记] Neural Image Caption(NIC)

Based on the paper by Oriol Vinyals, Alexander Toshev, Samy and Dumitru, Show and Tell: A Neural Image Caption Gdnerator.
Intro
Image Caption问题比较高难度,结合了物体识别和自然语言处理。NIC使用CNN先对Image层进行训练,将last hidden layer的输出结果作为一个RNN的input,产生描述短语。
Model
对image的预处理使用的CNN作者提到是目前为止对ILSVRC 2014表现最好的,而当时比赛的冠军是GoogLeNet,所以推测应该用的就是这个模型。
Statistical machine translation最新进展显示,一个powerful的sequence model可以获得很好的效果。他的原理是最大化获得正确翻译结果的概率。NIC类似于将image “翻译”成语言。最大化获得正确描述的条件概率(条件是给定input image):
\theta^*=arg\max_\theta\sum_{(I,S)}\log p(S|I;\theta)\theta is model parameters, I is an image, S is correct transcription.因为S表示句子,所以长度没有限制,比较普遍的做法是使用chain rule计算联合概率\log p(S|\theta,I)=\sum_{t=0}^N\log p(S_t|\theta,I,S_0,...,S_{t-1})。其中p(S_t|\theta,I,S_0,...,S_{t-1})一般是用RNN来model。而作为条件使用的t-1个words使用一个固定长度的hidden state或memory h_t储存。h_{t+1}=f(h_t,x_t), f is a non-linear function, x is a new input。
Two Crucial design choices are: 1) f's form, 2)how are images and words fed as input x。我们模型的f使用LSTM net(a particular form of recurrent nets,)。而对于2,representation of images,我们使用一种CNN model,包含batch normalization。
LSTM
选用LSTM的原因是:RNN的设计和训练中最大的问题就是vanishing and exploding gradients。
LSTM的核心是一个memory cell c,encoding knowledge at every time step of what inputs have been observed up to this step。Prediction通过三个乘法gate(为1则保留原值,为0则消除原值)处理:input gate,forget gate,output gate。乘法gate的主要优点就是处理vanishing and exploding gradients。最后计算的是probability distribution over all words。主要使用的非线性化是sigmoid和tanh,最后计probability distribution是用softmax。
Training:LSTM原理是根据已经获取的image信息和已经预测的word来预测下一个word,即p(S_t|\theta,I,S_0,...,S_{t-1})。Image只在LSTM初始使用一次。
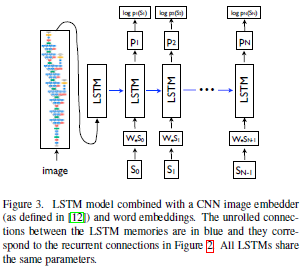
Result
作者提到的一个东西挺有意思,就是word embedding, 用vector represents word,这篇论文有介绍具体方法Efficient Estimation of Word Representations in Vector Space, 目测是NLP范畴,有机会也会总结一下。