
【阅读笔记】AlexNet - ImageNet Classification with Deep Convolutional Neural Networks

2012年出现的AlexNet可以说是目前这个深度卷积神经网络(Deep Convolutional Neural Networks) 热潮的开端,它显著的将ImageNet LSVRC-2010图片识别测试的错误率从之前最好记录top-1 and top-5 测试集 错误率 47.1% and 28.2% 一下子降低到了 37.5% and 17.0%。
虽然AlexNet并不是CNN的开创,但是从此开始CNN开始受到人们的强烈关注,并在ImageNet的比赛中大放异彩,2012年的AlexNet成为了研究热点从传统视觉方法到卷积神经网络的分水岭。

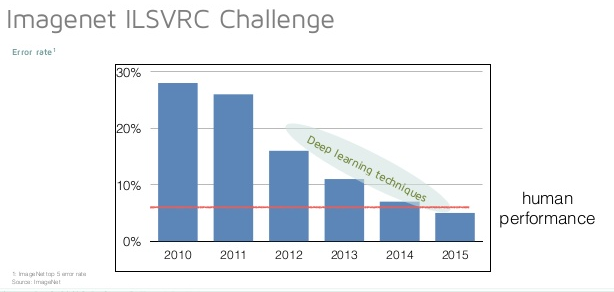
图片来自:
http://www.slideshare.net/nervanasys/sd-meetup-12215其中,从2012年以后Imagent ILSVRC的冠军一直是CNN。
因此正好借在上的一门课程要求读论文的机会,深入的了解下AlexNet,并作些笔记。
Paper原文地址:
1. AlexNet 网络架构
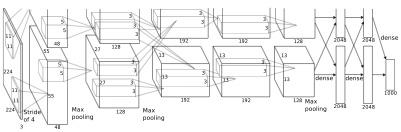
从图中可以看出,AlexNet一共有八层,其中前五层是卷积层(Convolutional layers),后三层全连接层(Fully-connected)。这个网络在现在看来并不深,但是在11年那时候就是一个突破了。
为了解决训练时间问题,他们实验室使用了两块GTX 580 3GB GPU,并且配合高度优化的卷积算法。为了解决过拟合的问题,他们采取了Data Augmentation和当时突破性的新方法Dropout(之后还会讲到)。
当时的GPU 即使是旗舰的GTX580也只有3GB的显存,对于如此深度的卷积神经网络来说并不是很足够,因此网络被分成了上下两层,一块GPU处理一部分的数据,并在中间部分层数据通讯。
1. Input layer: 224 * 224 * 3 (RGB图片,224 * 224像素)
2. Conv layer: 96 kernels of 11 * 11 * 3 - Response Normalization - Max-Pooling - ReLU
3. Conv layer2: 256 kernels of 5 * 5 * 48 - Response Normalization - Max-Pooling - ReLU
4. Conv layer3: 384 kernels of 3 * 3 * 256 - ReLU
5. Conv layer4: 384 kernels of 3 * 3 * 192 - Max-Pooling - ReLU
6. Conv layer5: 256 kernels of 3 * 3 * 192 - ReLU
7. Fully-connected1 of size 4096 - ReLU
8. Fully-connected2 of size 4096 - ReLU
9. Fully-connected3 of size 4096 - ReLU
10. Softmax output 1000
Conv layers with a stride of 4
在具体的实现当中,第2,4,5层卷积层只连接到前一层在同一个GPU中的部分,第3层卷积层和所有全链接层连接前一层的所有节点。
1.1 ReLU Nonlinearity
现在ReLU已经几乎成了DeepLearning的标准非线性函数,但是在当时最流行的还是经典的sigmoid和tanh,关于ReLU的详细资料和与其他函数的对比在各种地方都有介绍,重点优势主要是:1. 不会像sigmoid一样在容易饱和。2.计算速度快,使网络更快收敛。
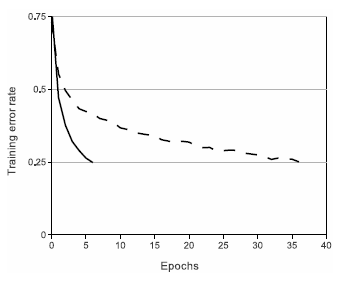
这张来自论文的图片显示了,ReLU快速收敛的特性。
1.2 Overlapping Pooling
AlexNet中的Pooling是重叠的,每次取3 * 3的像素做Max-Pooling,然后每次只越过2格,这样每个Pooling之间都会有一定得重叠,有利于更好地克服过拟合。
2. 减少过拟合
论文的第二部分主要讲他们如何克服过拟合的问题,虽然Imagenet的数据训练集很大,但是在深度神经网络的处理下,还是依然很容易产生过拟合问题。
2.1 数据扩增(Data Augmentation)
第一种数据扩增的方法:
原始的图片是256 * 256 像素,随机抽取其中的224 * 224的一块图片,这样就能讲数据集增加2048倍,虽然数据之间相关度非常高,但是依然有效。
第二种数据扩增的方法:
更改数据图片RGB通道的强度。
首先通过PCA,主成分分析,找出整个测试集数据中RGB像素值的主成分,然后在每次训练的图片像素中加上一定随机比例的主成分。
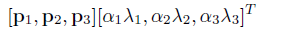
其中,p_i 和 \lambda _i是第 i 个3 x 3 图片RGP像素值协方差矩阵的特征值和特征向量, \alpha _i 是随机变量,从一个均值为 0 标准差 0.1 的高斯分布中抽取。对于一次训练中的一张训练图片,\alpha 只抽取一次,下一次再用这张图片训练时再重抽取。通过这个方法,top1 的错误率下降了1%。
2.2 Dropout
这也是现在非常常用的一个方法,通过随机的训练中的一些节点暂时“丢掉”,来防止过拟合,同时也增强了学习到的特征的鲁棒性,对于一部分节点。设置一个丢弃的概率p = 0.5,如果本次被抽中“丢弃”, 那这个节点就不参与正向和反向的计算。整个网络以此防止了过于依赖部分节点,因此整体效果将会显著的提高,
在AlexNet中,前两个全链接Fully-connected层采取了Dropout的策略,近乎将整个网络收敛的训练迭代次数增加了两倍。
这篇论文作为最近的深度学习开篇文章,非常值得多次阅读,如果有新的感想我也会继续记录,祝大家学习愉快!