王宝强是怎么选律师的?知识图谱告诉你

王宝强离婚案件终于开庭了,但宝宝专门聘请的律师张起淮到底有多牛,为什么第一时间就锁定请他呢?
据了解,张起淮在律师圈内的口碑颇有争议。因为他是当年“李天一轮奸案”的二审律师,在此之前还代理过北京某球星强奸案,且为被告人做无罪辩护获成功。
因此,有人说他爱出风头,有人说他“功绩显著”,但无疑他与娱乐圈有不错的关系,用知识图谱可以很容易地把事情讲清:


可以看到,他曾为徐静蕾、赵薇、庄则栋等名人担任过代理律师,因此王宝强这次的选择,极大的可能是圈内人介绍。分析王宝强2004年因参演冯小刚执导的剧情片《天下无贼》而获得关注,知遇之恩外,王宝强的生活一直有冯导的关心,而冯导与演而优则导的赵薇、徐静蕾已有多年交情,根据推测应该是得到了像冯导之类的比较亲近的朋友帮助。
并且,张起淮还多次就其代理的典型案件接受央视、人民日报等多家媒体的采访,还担任央视《焦点访谈》、《东方时空》、《今日说法》的嘉宾,简直就是律政界大咖。
反过来说,这么牛的律师能第一时间陪同王宝强报案,其案件复杂度和当事人的知名度无疑都是张起淮选择接手的原因。
不过,因代理李天一案太出名,网传张起淮律师是著名刑事代理律师,便有舆论表示:王宝强方面启用张作为代理律师的原因,在于此次案件绝非单纯的民事案件。
那到底是不是呢?
根据数据分析显示,张律师代理案件共计101起,其中刑事类案件仅占其代理案件的2.11%,其实,绝大部分案件还是民事类案件。不过考虑此次离婚案件复杂度,确实需要经验丰富的律师出手。
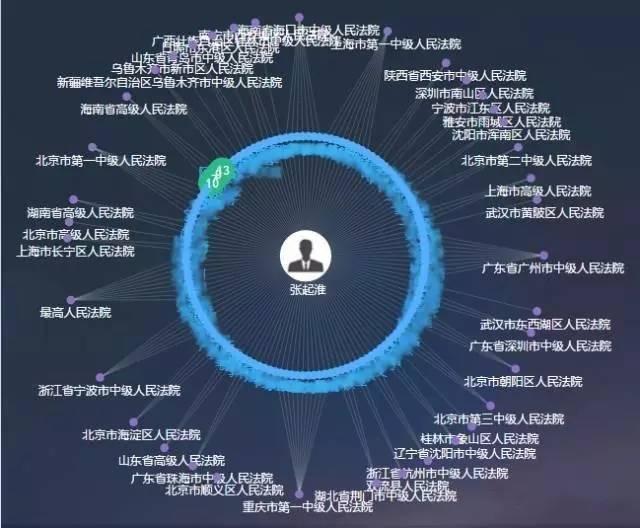

因此,张起淮之所以被认可,也并非只因在娱乐圈的知名度,还得靠实力说话:从第三方平台的律师关联方图谱来看,张律师在全国多地都代理过诉讼案件,并且未有异常关联预警。
其实,很多应用场景都可以用到知识图谱,但当面对海量的异构数据,分析起来就没那么简单了,需要整合线上、线下、手机、PC等全渠道来源数据,结合不同业务进行关联分析,下面举几个百分点在金融领域的应用来细说。
1
反欺诈
反欺诈是风控中非常重要的环节。
基于大数据的反欺诈的难点在于如何把不同来源的数据(结构化+非结构)整合在一起,并构建反欺诈引擎,从而有效地识别出欺诈案件(比如身份造假、团体欺诈、代办包装等)。
而且,不少欺诈案件会涉及到复杂的关系网络,这也给欺诈审核带来了新的挑战。知识图谱作为关系的直接表示方式,可以很好地解决这两个问题。
首先,知识图谱提供非常便捷的方式来添加新的数据源。其次,知识图谱本身就是用来表示关系的,这种直观的表示方法可以帮助我们更有效地分析复杂关系中存在的特定的潜在风险。
反欺诈的核心是人,需要把与借款人相关的所有的数据源打通,并构建包含多数据源的知识图谱,从而整合成为一台机器可以理解的结构化的知识。
我们不仅可以整合借款人的基本信息(比如申请时填写的信息),还可以把借款人的消费记录、行为记录、网上的浏览记录等整合到整个知识图谱里,从而进行分析和预测。
其中的一个难点是很多的数据都是从网络上获取的非结构化数据,需要利用机器学习、自然语言处理技术把这些数据变成结构化的数据。
2
不一致验证
不一致性验证可以用来判断一个借款人的欺诈风险,和交叉验证类似。比如借款人A和借款人B填写的是同一个公司电话,但张三填写的公司和李四填写的公司完全不一样,这就成了一个风险点,需要审核人员格外的注意。
再比如,借款人说跟张三是朋友关系,跟李四是父子关系。当我们试图把借款人的信息添加到知识图谱里的时候,“一致性验证”引擎会触发。引擎首先会去读取张三和李四的关系,从而去验证这个“三角关系”是否正确。很显然,朋友的朋友不是父子关系,所以存在着明显的不一致性。
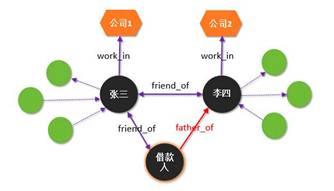
不一致性验证涉及到知识的推理。通俗地讲,知识的推理可以理解成“链接预测”,也就是从已有的关系图谱里推导出新的关系或链接。比如上面的例子,假设张三和李四是朋友关系,而且张三和借款人也是朋友关系,那我们可以推理出借款人和李四也是朋友关系。
3
组团欺诈
相比虚假身份的识别,组团欺诈的挖掘难度更大。
这种组织在非常复杂的关系网络里隐藏着,不容易被发现。当我们只有把其中隐含的关系网络梳理清楚,才有可能去分析并发现其中潜在的风险。
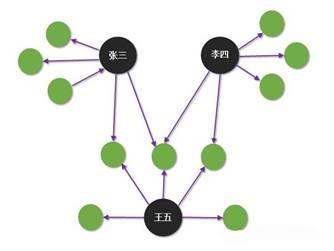
比如,有些组团欺诈的成员会用虚假的身份去申请贷款,但部分信息是共享的。从下图中可以看出张三、李四和王五之间没有直接的关系,但通过关系网络我们很容易看出这三者之间都共享着某一部分信息,这就让我们马上联想到欺诈风险。
虽然组团欺诈的形式众多,但有一点值得肯定的是知识图谱一定会比其他任何的工具提供更佳便捷的分析手段。
4
异常分析
异常分析是数据挖掘研究领域里比较重要的课题。
我们可以把它简单理解成从给定的数据中找出“异常”点。在实际应用中,这些”异常“点可能会关联到欺诈。
既然知识图谱可以看做是一个图(Graph),知识图谱的异常分析也大都是基于图的结构。由于知识图谱里的实体类型、关系类型不同,异常分析也需要把这些额外的信息考虑进去。大多数基于图的异常分析的计算量比较大,可以选择做离线计算。在应用框架中,可以把异常分析分为两大类:静态分析和动态分析。
- 静态分析
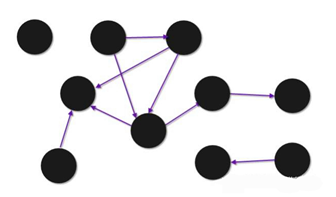
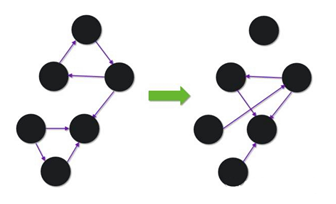
所谓的静态分析指的是,给定一个图形结构和某个时间点,从中去发现一些异常点(比如有异常的子图)。下图中可以很清楚地看到其中五个点的相互紧密度非常强,可能是一个欺诈组织。所以针对这些异常的结构,可以做出进一步的分析。
- 动态分析
所谓的动态分析指的是分析其结构随时间变化的趋势。假设是,在短时间内知识图谱结构的变化不会太大,如果它的变化很大,就说明可能存在异常,需要进一步的关注。
5
失联客户管理
除了贷前的风险控制,知识图谱也可以在贷后发挥其强大的作用。
比如在贷后失联客户管理的问题上,知识图谱可以帮助我们挖掘出更多潜在的新的联系人,从而提高催收的成功率。
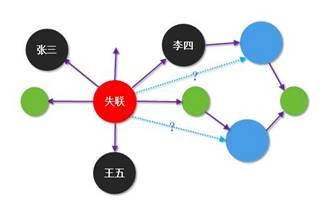
现实中,不少借款人在借款成功后出现不还款现象,而且玩“捉迷藏”,联系不上本人。即便试图去联系借款人曾经提供过的其他联系人,但还是没有办法联系到本人。这就进入了所谓的“失联”状态,使得催收人员也无从下手。
那接下来的问题是,在失联的情况下,我们有没有办法去挖掘跟借款人有关系的新的联系人?而且这部分人群并没有以关联联系人的身份出现在知识图谱里。如果能够挖掘出更多潜在的新的联系人,就会大大地提高催收成功率。
比如,在下面的关系图中,借款人跟李四有直接的关系,但我们却联系不上李四。那有没有可能通过2度关系的分析,预测并判断哪些李四的联系人可能会认识借款人。这就涉及到图谱结构的分析。
6
智能搜索及可视化演示
基于知识图谱,也可以提供智能搜索和数据可视化的服务。
智能搜索的功能类似于知识图谱在Google、Baidu上的应用。也就是说,对于每一个搜索的关键词,我们可以通过知识图谱来返回更丰富,更全面的信息。
比如搜索一个人的身份证号,智能搜索引擎可以返回与这个人相关的所有历史借款记录、联系人信息、行为特征和每一个实体的标签(比如黑名单、同业等)。另外,可视化的好处不言而喻,通过可视化把复杂的信息以非常直观的方式呈现出来,使得我们对隐藏信息的来龙去脉一目了然。
7
精准营销
一个聪明的企业可以比它的竞争对手以更为有效的方式去挖掘其潜在的客户。
在互联网时代,营销手段多种多样,但不管有多少种方式,都离不开一个核心——分析用户和理解用户。知识图谱可以结合多种数据源去分析实体之间的关系,从而对用户的行为有更好的理解。
比如一个公司的市场经理用知识图谱来分析用户之间的关系,去发现一个组织的共同喜好,从而可以有针对性的对某一类人群制定营销策略。只有我们能更好的、更深入的(Deep understanding)理解用户的需求,我们才能更好地去做营销。