
零基础入门python爬虫(二)



欢迎加入纯干货技术交流群Disaster Army:317784952
往期回顾:
0x00****正确识别网站编码类型
上一章中我们说urllib模块下的info()方法获取网页的Header信息,但是有的一些中小型网站和个别大型网站是不能够很好的获得的。这是因为有时建站者用的是别人的网站源码,网页的编码和头部信息声明的编码不统一,也有的是旁站和主站编码类型不一致,总之很多原因吧。那么我们怎样才能合理的得出一个网站的编码类型呢?总不能它的分站,每个页面都去查看源代码都去分析吧?
我们需要用到chardet这个第三方模块;
https://pypi.python.org/pypi/chardet
下载下来后安装方法也是比较简单的,在cmd中执行文件夹chardet-2.3.0下的steup.py install 即可!(你又学会了安装第三方模块!)那么接下来我们就要用到这个模块:
import chardet
# 字符集检测
import urllib然后封装一个函数,先撸代码后封装函数
ef automatic_detect(url):
"""doc"""
content = urllib.urlopen(url).read()
result = chardet.detect(content)
encoding = result['encoding']
return encoding
然后将字符串网址赋值给url构成一个
urls = ["http://www.baidu.com/",
"http://www.163.com/",
"http://www.youku.com/"
]接下来遍历这个参数,让每次都把url参数传入函数,打印出来。
for url in urls:
print url,automatic_detect(url)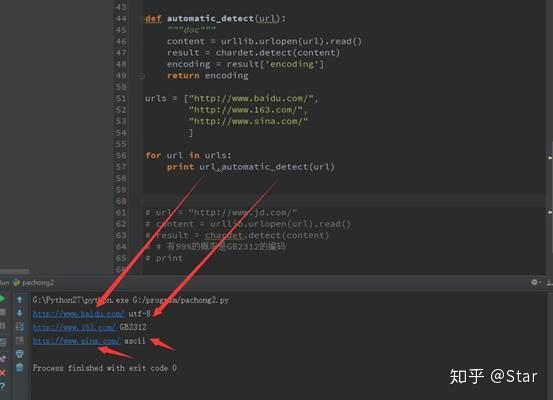

这样呢,我们就可以批量检测网站的编码理想,图上标注的代码可以分析显示出网站编码类型可能性百分数,很可靠。Chardet不再是服务器头部信息判断编码,也不是通过检查网页源代码得到站长申明的编码,而是通过检测所有内容判断编码类型,所以可靠。
**0x001 **网站抓取限制绕过
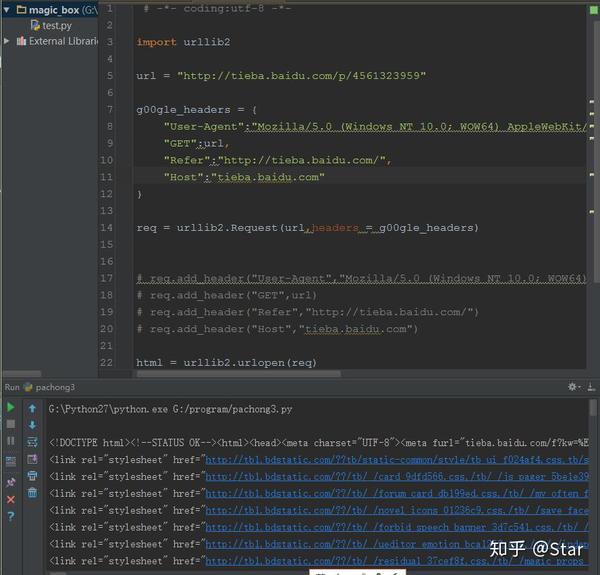
有的一些网站是防爬取的,那么我们想要爬取的话就需要知道它是怎样限制的。它会记录来访信息,如果发现你短时间内请求多次就会限制你的IP.是否模拟浏览器,且用户信息多种多样,又来自不同的IP进行访问呢?这样就会让受访对象以为是来自不同地方的多个用户在访问,就没有限制的理由喽?当然是可以的,你且来看,先看模拟一个浏览器访问:
# -*- coding:utf-8 -*-
import urllib2
url = http://tieba.baidu.com/p/xxx
g00gle_headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"GET":url,
"Refer":"http://tieba.baidu.com/",
"Host":"tieba.baidu.com"
}
req = urllib2.Request(url,headers = g00gle_headers)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36")
req.add_header("GET",url)
req.add_header("Refer","http://tieba.baidu.com/")
req.add_header("Host","tieba.baidu.com")
html = urllib2.urlopen(req)
print html.read()
print req.header_items()除了以上的代码分别加上这两条打印,就可以分别打印网页内用和头部信息。

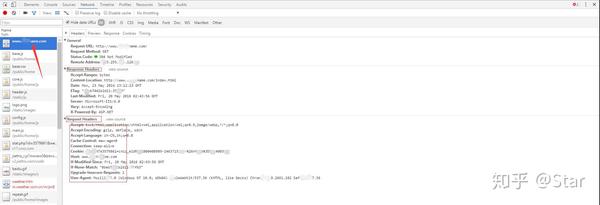
用户信息可以用Chorme等浏览器抓包查看:
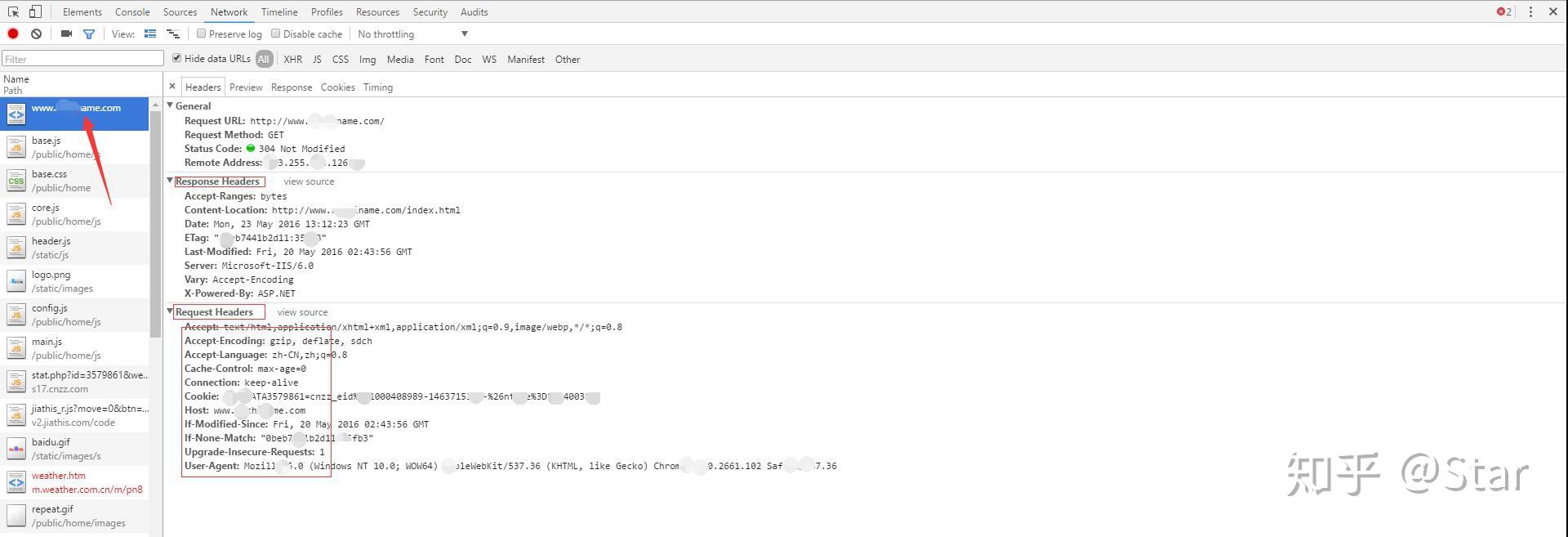
下面我们封装函数,捏造多个用户信息访问:
# -*- coding:utf-8 -*-
import urllib2
import random
url = "http://tieba.baidu.com/p/xxx"
g00gle_headers = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89"
]
def get_content(url, headers):
"""
@获取403禁止访问
"""
random_header = random.choice(headers)
# header参数传给函数random_choice(随机选择),然后赋值给random_header(随机header)
req = urllib2.Request(url)
req.add_header("User-Agent",random_header)
# 添加header,用户代理
req.add_header("Host","tieba.baidu.com")
# 添加Host
req.add_header("Refer","http://tieba.baidu.com/")
# 来源
req.add_header("GET",url)
# 请求的地址
content = urllib2.urlopen(req).read()
return content
print get_content(url, g00gle_headers)笔记已做在代码的注释段,请仔细看一下。其中:
g00gle_headers = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89"
]就是捏造的多个用户信息,变量名可以随便取的,不建议我这么非主流,还是有套路一点比较好。这样就可以突破网站的抓取限制了。这还是没有设置代理IP的,感兴趣的同学可以继续深倔!
**0x003 **本章小结
本章我们针对一般情况以外的特殊情况进行了探讨。有的网站查不到编码类型怎么办,有的网站拒绝爬取信息怎么办。世上本没有路,走的人多了也便成了路。办法一定会有的,大牛眼里这些都是小儿科,欢迎来喷!下章我们爬取所需要的东西,有序下载到本地,敬请期待!


