<Aggregating Deep Convolutional Features for Image Retrieval>论文笔记

转载请注明出处:西土城的搬砖日常
原文链接:
Aggregating Deep Convolutional Features for Image Retrieval文章来源:ICCV 2015
一、文章简介:
典型的图像搜索算法包括三个阶段:首先提取给定图像的原始特征向量即局部不变特征(SIFT等),然后将这些局部不变特征进一步编码作为一个紧凑的图像表示(VLAD, Fisher vector, Triangular embedding等),最后将要查询图像与图像库的图像进行相似度计算,给出搜索结果。本文就是针对其中的第二个过程,提出了一种更简洁,计算量更小的编码方法——Sum pooling(SPoC)。
二、文章背景:
在arXiv上,论文《Where to Focus: Query Adaptive Matching for Instance Retrieval Using Convolutional Feature Maps》就是在本文的基础上提出了新的相似度算法。
在2015年首届阿里巴巴大规模图像搜索大赛中,排名第三的队伍用的就是用到了这篇论文的方法。基于GoogLeNet-22,对最后的8层feature map,首先使用最大池化对这些不同尺度的特征图分别进行子采样转换成相同尺寸的特征图,再使用卷积对这些采样结果进一步处理。然后对这些特征图做线性加权,最后使用sum pooling得到最终的图像特征。
常用图像编码方法:
1. BOF(Bag of words)
- 提取的原始特征向量,即视觉词汇向量。
- 对上面得到的视觉词汇用K-Means聚类,构造相应的单词表
- 统计词表中每个词的频数,从而将图像表示成一个数值向量。


2. Fisher Vector
最早在1998年《Exploiting generative models in discriminative classifiers》中提出了Fisher kernel方法,2007年《Fisher kernels on visual vocabularies for image categorization》中fisher kernel被应用于图像分类。2010年《Improving the fisher kernel for large-scale image classification》进一步改进了fisher vector。其本质使用似然函数的梯度向量表示图像。
3. VLAD(vector of locally aggregated descriptors)
2010年在论文《Aggregating local descriptors into a compact image representation》中被提出。
\mu ^{j} = \sum_{i:NN(x_{i}=j )}^{}{x_{i}-c_{j}}x是图像的原始特征向量,c_{i}是该图像的聚类中心,NN(x)是离x最近的聚类中心。
VLAD可以理解为BOF和Fisher Vector的折中。BOF只用离特征点最近的一个聚类中心代替该特征点,损失较多信息。Fisher Vector用所有聚类中心的线性组合来表示特征点,但是再用GMM建模的过程中也有损失信息。VLAD像BOF那样,只考虑特征点最近的聚类中心,VLAD保存了每个特征点到离它最近的聚类中心的距离,并且像Fisher Vector, VLAD考虑了特征点的每一维的值。
4.Triangulation Embedding
\phi _{TE}(x)=\left[ \frac{x-c_{1}}{\left| x-c_{1} \right| },...,\frac{x-c_{K}}{\left| x-c_{K} \right| } \right]三、本文提出方法:
Sum-pooling(SPoC):
sim(I_{1},I_{2}) = <\psi (I_{1}),\psi(I_{2})=\sum_{f_{i}\in I_{1}}^{}{} \sum_{f_{j}\in I_{2}}^{}{<f_{i},f_{j}>}
在后面的实验中作者发现,上面的方法容易被图像中一些不相关的信息,例如图边缘的树、人行道等干扰,导致识别错误。于是作者进一步改进了上述方法:
\psi _{2}(I) = \sum_{y=1}^{H}{} \sum_{x=1}^{W}{\alpha _{(x,y)}f_{(x,y)}}权重\alpha_{(x,y)}仅由空间坐标确定,即加大图像中心部分的权重,使识别的注意力更加集中在图像的中心区域,淡化图像边缘信息。
最后,再通过PCA降维和L2归一化得到最终的特征:
\psi _{3}(I)=diag(s_{1},s_{2},...,s_{N})^{-1}M_{PCA}\psi _{2}(I)\psi _{SPOC}(I)=\frac{\psi _{3}(I)}{\left| \psi _{3}(I) \right| }
四、实验过程:
首先,作者随机选择图像的部分patch,分别用三种方法找出与其匹配的内容。第一组是用深度网络提取特征,中间一组是只用SIFT提取图像原始特征,最后一组是用Fisher Vector对SIFT取得的原始特征再进行编码后得到的结果。



横坐标为k的取值,纵坐标为第k近的邻居的距离与到所有特征的平均距离的比值。由图可以看出,conv5_4层得到的特征最为稠密,包含的信息更多,能够提供更可靠的相似性。
从上述两个实验都可以明显看出用神经网络学习得到的图像特征相对于SIFT用于匹配任务中得到的结果更准确。所以,本文后面的实验都是基于图像的深度神经网络特征。



上述使用提出的新方法做搜索的例子,绿色代表搜索正确的,红色是搜索错误的,蓝色代表图片来自“junk”列表。从上面可以看出新方法对于缩放,旋转图像识别较好,但是容易被一些不相关的噪音干扰,例如人行道,树等。这就是上面改进方法添加位置信息的原因。
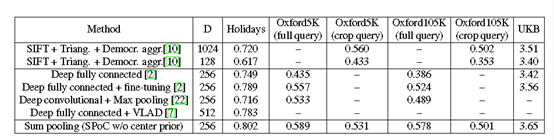
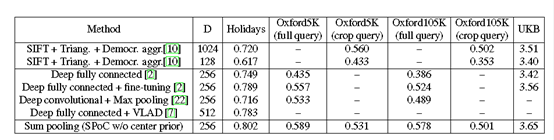
最后,作者将文本提出的方法与主流的方法做了综合对比,很显然,本文方法得到的最终MAP更好,效果更好。
参考:
1.Bag-of-words model in computer vision
