三步走,教你定制自己的个性python爬虫,代码都省了有木有~

想抓取各大招聘网站上的职位信息吗,想抓取各大电商网站上的商品信息吗,想抓取1024上各种不可描述吗?看这里,看这里,简单三步走,各种数据,你值得拥有。
一个基于scrapy 的二次开发框架webWalker,只需要配置xpath或正则表达式,就可以在互联网上随心所欲,想抓哪里抓哪里!
框架目标:写最少的代码,实现定制化抓取
需要掌握技能
- xpath表达式,正则表达式,以及css表达式,至少会其中一项
- python 字典和列表数据结构
以下技能最好掌握
- python lambda 表达式的使用
- python 简单函数编写
- 了解scrapy的基本概念,参见scrapy简单介绍
抓取经验:
- 抓取国外81个电商网站70W商品SKU(库存量单位)信息
- 抓取国内各大招聘网站各行业的职位信息
- 抓取不可描述的网站上各种不可描述的图片及下载链接
以下是干货:
手把手教你实现网站分类下项目信息的抓取
我们以bluefly为例进行讲解(声明声明,本文不是bluefly的软文,bluefly不是指蓝翔,虽然我是山东的,更是济南的,但你们问我挖掘机的事情,宝宝表示一脸萌比)
一、安装web-walker
需要python2.7
git clone https://github.com/ShichaoMa/webWalker.git
cd webWalker/walker && (sudo) python setup.py install
or
(sudo) pip install web-walker
可以直接从git上clone代码,但更推荐使用pip安装,windows 系统和ubuntu系统均支持。
二、配置抓取信息
- 打开你要抓取网站,找到一个你要抓取项目的分类。比如,我们选择woman shirt
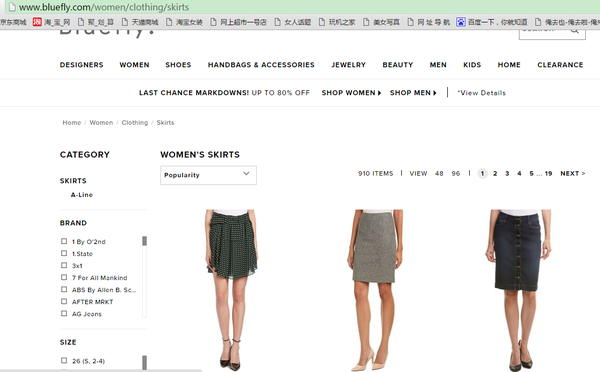

一共找到了910个商品, 我们要把每一件shirt的商品信息都抓取下来。
- 首先我们打开浏览器开发者工具F12,推荐使用chrome浏览器,找到下一页的xpath表达式
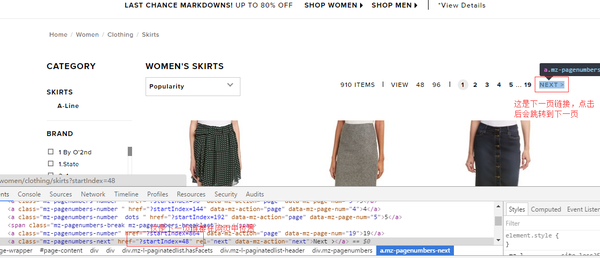

不懂xpath的可以看这里,一个非常简单的XML路径语言,用来寻找网页中的元素,很容易学习。XPath 教程
注意:现在的开发者工具都会有copy xpath这个功能,但不推荐使用,因为copy出来的xpath专一性很强。可能你抓取其它商品或者其它页的时候,xpath已经不适用了,使用id ,标签名,加上class去匹配一个xpath路径,会更通用一些。
我们找到的结果是
'//*[@id="page-content"]//a[@rel="next"]/@href'
好的,先记下来,一会儿用来配置。
- 然后,我们找到商品链接的xpath表达式
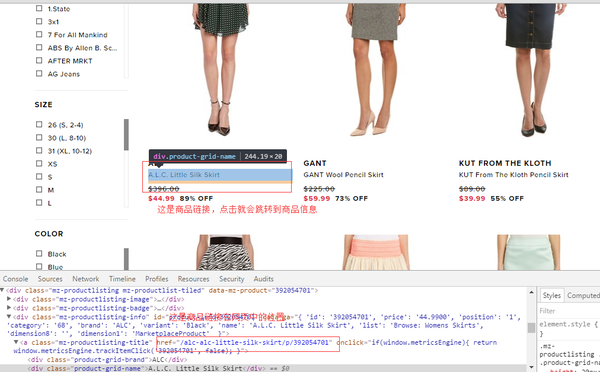

'//ul[@class="mz-productlist-list mz-l-tiles"]/li//a[@class="mz-productlisting-title"]/@href'
保存起来。
- 接下来,我们点开商品链接,在商品页面寻找我们需要的信息。


'//p[@class="mz-productbrand"]/a/text()' # 商标
'//span[@class="mz-breadcrumb-current"]/text()' # 标题
'//*[@id="product-selection"]//div[@itemprop="price"]/text()' # 原价
'//*[@id="product-selection"]//div[@class="mz-price is-saleprice"]/text()' # 现价
'//div[@class="mz-productoptions-valuecontainer"]/span/text()' # 尺寸
'//div[@class="mz-productoptions-optioncontainer colorList"]/div/span/text()' # 颜色
'//li[@itemprop="productID"]/text()' # 商品唯一id
......当然,你还可以抓取其它信息。
好了,在有这些信息之后,让我们开始配置我们的程序吧。
- 使用scrapy生成一个项目
ubuntu@dev:~/myprojects$ scrapy startproject demo
New Scrapy project 'demo' created in:
/home/ubuntu/myprojects/demo
You can start your first spider with:
cd demo
scrapy genspider example example.com
# 目录结构如下
.
├── demo
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
或者直接从test中复制myapp,如果要改项目名字,记得修改scarpy.cfg中的名字
- 删除掉其中的demo/items.py demo/piplines.py,并使用myapp/settings.py,myapp/spipders/__init__.py 替掉原来的文件
- 在spiders目录下,创建page_xpath.py, item_xpath.py, item_field.py, spiders.py,编写以下内容
# spiders.py
# -*- coding:utf-8 -*
SPIDERS = { # 配置spider, spider名称一个字典,字典中为这个spider的一些自定义属性,可为空
"bluefly": {}
}
# page_xpath.py
# -*- coding:utf-8 -*
PAGE_XPATH = { # 配置网站分类页中获取下一页链接的方式,具体策略参见wiki
"bluefly": [
'//*[@id="page-content"]//a[@rel="next"]/@href',
]
}
# item_xpath.py
# -*- coding:utf-8 -*
ITEM_XPATH = { # 配置网站分类页中获取商品页链接的方式,xpath表达式
"bluefly": [
'//ul[@class="mz-productlist-list mz-l-tiles"]/li//a[@class="mz-productlisting-title"]/@href',
]
}
# item_field
# -*- coding:utf-8 -*
ITEM_FIELD = { # 商品页中,所需信息的获取方式,具体策略参见wiki
"bluefly": [
('product_id', {
"xpath": [
'//li[@itemprop="productID"]/text()',
],
}),
('brand', {
"xpath": [
'//p[@class="mz-productbrand"]/a/text()',
],
}),
('title', {
"xpath": [
'//span[@class="mz-breadcrumb-current"]/text()',
],
}),
('price', {
"xpath": [
'//*[@id="product-selection"]//div[@itemprop="price"]/text()',
],
}),
('new_price', {
"xpath": [
'//*[@id="product-selection"]//div[@class="mz-price is-saleprice"]/text()',
],
}),
('size', {
"xpath": [
'//div[@class="mz-productoptions-valuecontainer"]/span/text()',
],
}),
('color', {
"xpath": [
'//div[@class="mz-productoptions-optioncontainer colorList"]/div/span/text()',
],
}),
]
}
- 修改demo/settings.py 文件,或者直接新建localsettings.py,增加自定义配置,要修改的项目在settings.py已注明
配置完毕,接下来我们就要开始抓取了。
三 启动我们的程序
- 启动redis
#如果没有安装redis,可以使用自带的custom-redis,配置文件中需写明CUSTOM_REDIS=True
custom-redis-server -p 6379注:cutom-redis是我实现的python 版的简单redis 参见GitHub - ShichaoMa/custom_redis: python实现简单redis,实现redis基本功能以及可插拔数据结构

- 启动爬虫
cd demo
scrapy crawl bluefly

- 投放任务
# 使用自带的costom-redis 需要加上 --custom
# 投放分类链接
feed -c test_01 -s bluefly -u "http://www.bluefly.com/women/clothing/skirts" --custom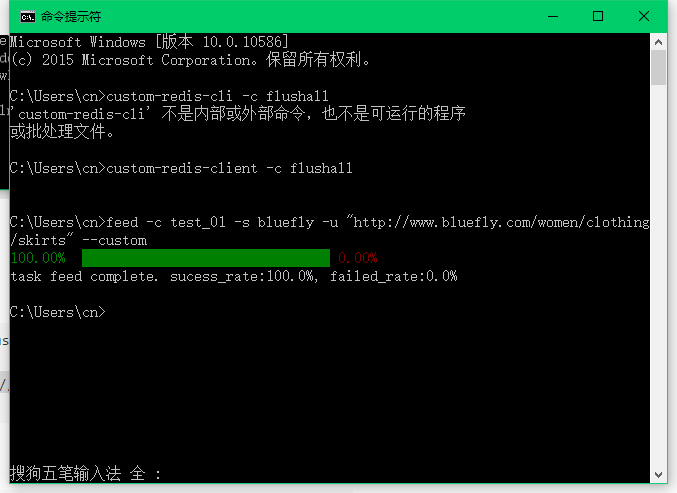

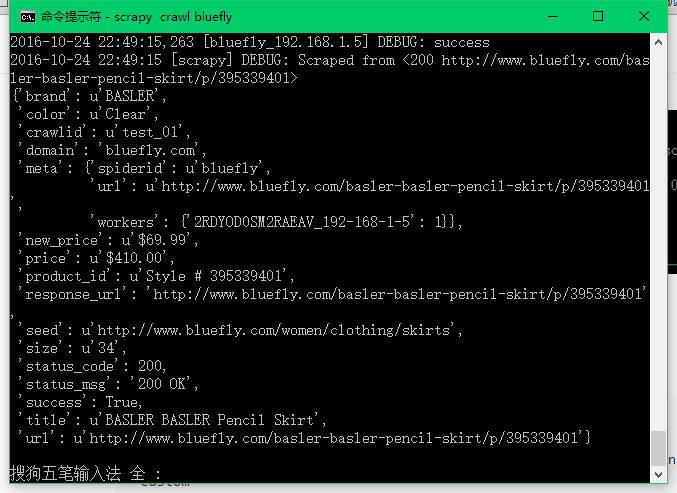

爬虫在努力的工作中。
可以在配置文件中配置是将log打到控制台,文件还是kafka(用来关联elk做日志管理)中。
- 查看任务状态
# 使用自带的costom-redis 需要加上 --custom
check test_01 --custom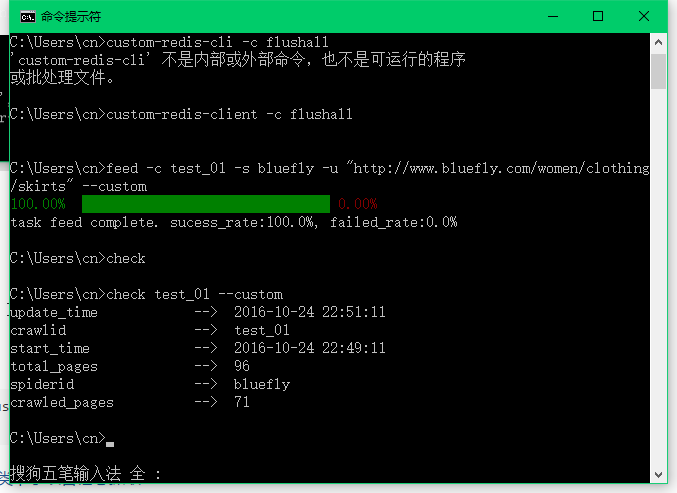

或许你看到这个结果时,第一反应就是这样的,但是,请相信我可以解释这一切。当你不对scrapy做任何限制的时候,scrapy会同时下载十几个网页(具体看配置),抓取速度可能会很快,这样的就会导致,下一页还没翻完,当前页的商品已经差不多抓取完毕了,所以才会这种现象出现。
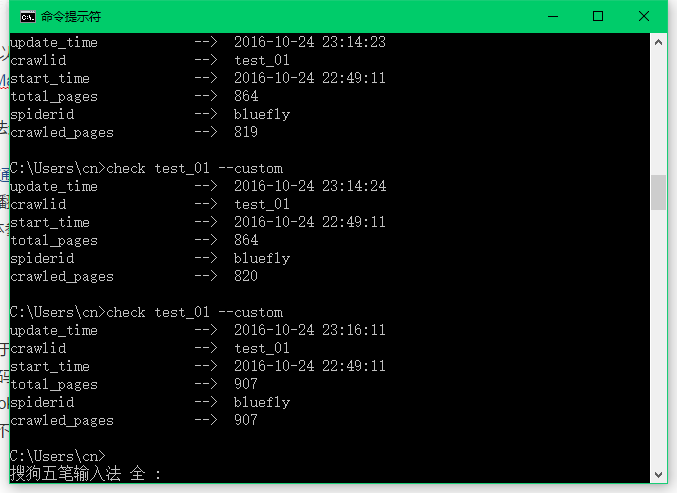

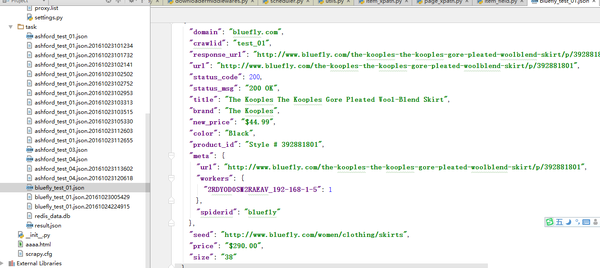
全部商品抓取完毕,至于为什么刚才是910,现在只有907。那是因为这些电商网站的商品数量会经常变化,不要在意这些细节。。。如果你没有更改pipline配置,会默认使用JSONPipline进行数据存储,关闭程序后,会在程序的项目根目录task文件夹下生成json格式的文件用来存储抓取信息。

FAQ:
问:能简单介绍一下scrapy吗?
答:请看这里scrapy 简单介绍 · ShichaoMa/webWalker Wiki · GitHub
问:很多时候翻页链接是前端js生成的,无法通过xpath获取,怎么办?
答:这种情况的确很常见,但是请相信我,通用抓取配置方法 · ShichaoMa/webWalker Wiki · GitHub,这里提到的另外三种通过正则配置翻页策略的方式,基本可以应付绝大多数网站,如果还不能实现,你可以重写parse函数,具体参见自定义高级特性 · ShichaoMa/webWalker Wiki · GitHub
问:很多页面上的信息都是通过ajax发送请求得到的,框架可以通过配置实现吗?
答: 通过配置增发请求函数提供下一个请求的Url,可以优雅的实现。具体参见item_field函数配置 · ShichaoMa/webWalker Wiki · GitHub
问:使用xpath或正则得到数据还需要进一步处理怎么办?
答:框架提供了自定义转换函数机制,你可以通过编写转换函数,来处理抓取下来的原始数据,具体参见item_field函数配置 · ShichaoMa/webWalker Wiki · GitHub
问:网站的一些反爬虫措施如何应对?
答:常规的反反爬虫措施框架都已经集成,对于限制ip,可以通过配置代理中间件使用来完成。对于通过验证码识别爬虫的网站,可以通过编写验证码中间件,调用识别验证码的程序来识别,如果不好识别,可以使用人工打码,并记录返回的cookies,用以发送下一次请求。这种方式看似低级其实很好用,对付amazon及jomashop屡试不爽。一个有效cookies可以用半小时。半小时打一次码。其实是可以接受的。
问:如何提高抓取效率?
答,scrapy支持高并发,简单配置即可,但是不推荐使用太高的并发,非常容易被封ip。本框架是一个分布式程序,在一台机器上的开启redis之后,可以使用不同的ip下多台机器同时运行spider监控redis任务队列抓取。
问:如何保存数据?
答:scrapy提供了自定义pipline的功能,可以根据需求将数据存储到不同的数据库中,具体可以参见自定义高级特性 · ShichaoMa/webWalker Wiki · GitHub
问:如果我们有问题和建议给你发私信。pull request会被重视吗?
答:首先非常感谢您的使用,由于本人才疏学浅,经验不足,所以框架可能会存在很多不够完善的地方,愿您的问题可以使框架本身功能越来越强大、易用,我会尽可能在最短时间内给您回复,并适时对框架做出改进。
您的每一次赞美都是我前进的动力,感谢阅读!
github: GitHub - ShichaoMa/webWalker: 分类下子项目信息抓取
关于作者: 不按套路出牌的水货python程序员,在职爬虫工程师。
