
深度学习theano/tensorflow多显卡多人使用问题集

其实一直想写这篇东西,今天还是抽空系统整理一下吧。
深度学习在实验环境通常会在一台主机安装多张显卡,既可以满足多人使用,也可以运行部分分布式任务。
例如我这里一台主机安装了3块980Ti显卡(虽然做了SLI但实际在深度学习用不着,其实只在windows下玩游戏有用),不用水冷也可以正常三块同时跑。运行环境是以keras为主(anaconda虚拟环境,cuda7.5+cudnn4),后端有人选择用theano,有人选择用tensorflow,也有人不用keras直接跑tensorflow。由于是实验环境外加正式环境(每天定时运行程序),有4、5个用户可能会同时使用,在之前使用过程中经常会遇到各种冲突。经历了各种痛苦后,我积累了一些心得,将各种解决方案列举一下。
基本显卡信息用nvidia-smi命令可以 当前运行情况:
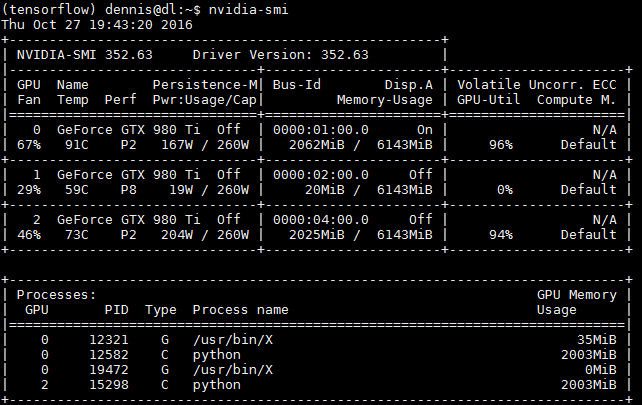

可以看到第一块显卡和第三块显卡已经有程序运行着(一般接显示器的显卡会占用200M左右显存),但是我通过代码已经限制了显存的占用(下面会提到)。
要看到什么python代码正在运行,可以用 ps ax | grep python 命令来看到其他人在运行的代码。在实际使用中由于深度学习会长时间运行,可以考虑用apt-get安装screen或tmux复用终端运行,这样即便网络断线也不会导致程序的中断。
接下去是正题了,默认情况下我们已经配置好使用显卡运行深度学习程序:
1、运行多程序,但返回显存不足
有时会碰到类似:MemoryError: Error allocating xxxxxxx bytes of device memory (CNMEM_STATUS_OUT_OF_MEMORY)的错误
一般情况下,当两个程序同时在同一块显卡上试图执行程序时,默认会返回这种错误。首先nvidia的显卡用作深度学习的主要两个关键部分,一个是显存,一个是cuda流处理器,如下图,注意流处理器和显存容量两个关键指标。

默认情况下,不管是theano还是tensorflow,都是在执行初始化时占用满显存,请注意,是占用满。这样,这块显卡都容不下第二个程序运行了。所以默认配置情况一块显卡同时只允许一个人运行一个深度学习程序。
那么我们自然会想到是否一次只用一部分显存,是否可以让多个程序同时运行?答案自然是肯定的。
1.1:theano后台限制显存:每个用户在自己home根目录建立.theanorc文件(注意这个文件默认不存在,且文件名前面有个点),配置参数例子如下(参考:config – Theano Configuration):
[global]
floatX = float32
device = gpu0
optimizer_including = cudnn
[lib]
cnmem = 0.3
[cuda]
root = /usr/local/cuda/
其中cnmem部分是占用多少比例显存,也就是说如果配置0.3的话可以同时满足1.0/0.3 = 3个程序同时运行(剩下0.1我留给显示器显示ubuntu桌面),每个程序一次占用三分之一的显存。device = gpu0说明启动第0个GPU,配合nvidia-smi命令的输出,gpu0其实表示的最下面的显卡(请注意图上显示编号为2),gpu1表示中间一块(如果总共三块显卡),gpu2表示最上面一块。默认情况,theano会使用第0块显卡(如果其他被占用)。
1.2:tensorflow后台限制显存:
tensorflow如果如果单纯用tensorflow的话可以用代码控制(参见:https://www.tensorflow.org/versions/r0.11/how_tos/using_gpu/index.html#allowing-gpu-memory-growth):
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
session = tf.Session(config=config, ...)
如果使用keras作为前端也可以用代码控制(参见:Limit the resource usage for tensorflow backend · Issue #1538 · fchollet/keras · GitHub)
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.3
set_session(tf.Session(config=config))
这样就可以让同一块显卡同时执行多程序了。cuda流处理器也可以和多核CPU一样满足多程序运行。
需要注意的是,虽然代码或配置层面设置了对显存占用百分比阈值,但在实际运行中如果达到了这个阈值,程序有需要的话还是会突破这个阈值(用theano后端会如此,tensorflow可能会报资源耗尽错,2017年7月20日补充)。换而言之如果跑在一个大数据集上还是会用到更多的显存。以上的显存限制仅仅为了在跑小数据集时避免对显存的浪费而已。
2、只运行了一个程序,运行返回显存不足
运行机器学习算法时,很多人一开始都会有意无意将数据集默认直接装进显卡显存中,如果处理大型数据集(例如图片尺寸很大)或是网络很深且隐藏层很宽,也可能造成显存不足。
这个情况随着工作的深入会经常碰到,解决方法其实很多人知道,就是分块装入。以keras为例,默认情况下用fit方法载数据,就是全部载入。换用fit_generator方法就会以自己手写的方法用yield逐块装入。这里稍微深入讲一下fit_generator方法。
fit_generator方法定义
def fit_generator(self, generator, samples_per_epoch, nb_epoch,
verbose=1, callbacks=[],
validation_data=None, nb_val_samples=None,
class_weight=None, max_q_size=10, **kwargs):
其中generator参数传入的是一个方法,validation_data参数既可以传入一个方法也可以直接传入验证数据集,通常我们都可以传入方法。这个方法需要我们自己手写,伪代码如下:
def generate_batch_data_random(x, y, batch_size):
"""逐步提取batch数据到显存,降低对显存的占用"""
ylen = len(y)
loopcount = ylen // batch_size
while (True):
i = randint(0,loopcount)
yield x[i * batch_size:(i + 1) * batch_size], y[i * batch_size:(i + 1) * batch_size]
为什么推荐在自己写的方法中用随机呢?因为fit方法默认shuffle参数也是True,fit_generator需要我们自己随机打乱数据。另外,在方法中需要用while写成死循环,因为每个epoch不会重新调用方法,这个是新手通常会碰到的问题。
当然,如果原始数据已经随机打乱过,那么可以不在这里做随机处理。否则还是建议加上随机取数逻辑(如果数据集比较大则可以保证基本乱序输出)。深度学习中随机打乱数据是非常重要的,具体参见《深度学习Deep Learning》一书的8.1.3节:《Batch and Minibatch Algorithm》。(2017年5月25日补充说明)
调用示例:
model.fit_generator(self.generate_batch_data_random(x_train, y_train, batch_size), samples_per_epoch=len(y_train)//batch_size*batch_size,
nb_epoch=epoch, validation_data=self.generate_valid_data(x_valid, y_valid,batch_size),
nb_val_samples=(len(y_valid)//batch_size*batch_size), verbose=verbose,
callbacks=[early_stopping])
这样就可以将对显存的占用压低了,配合第一部分的方法可以方便同时执行多程序。
3、多显卡环境在某块显卡被占用时在其他显卡运行返回:Segmentation fault (core dumped)
最近几个月使用频繁时,经常有人会碰到Segmentation fault (core dumped)错误(这个问题似乎是突然出现的),当我在用编号为2的显卡时,其他人使用其他显卡时就会报这个错,而其他人使用编号0显卡时,我使用编号2显卡也会报错。在网上也可以看到此类问题。
虽然tensorflow可以指定显卡(参见:Using GPUs),但如果使用前端用keras时也无从指定。
其实有一劳永逸的方式,在CUDA层面屏蔽其他显卡。
默认情况下,调用CUDA都会遍历所有显卡,有显卡被占用就可能会出core dumped错误,通过CUDA_VISIBLE_DEVICES参数可以控制CUDA可见哪些显卡,只显示自己用的就好,就不用关心别人的用没用了。
将此参数配置加入系统变量即可:
export CUDA_VISIBLE_DEVICES=2
后面的编号表示几号显卡,也可以用逗号分隔。(参见:python - TensorFlow Choose GPU to use from multiple GPUs)
通常可以将这行加入用户home目录下.bashrc,这样每次远程登录就不用重新配置了。
如此,每个人使用不同显卡就能互不干扰了。
————————————————
终于写完了,应该算是干货吧,嘿嘿~~