
如何在第一次天池比赛中进入Top 5%(一)

国庆节前后,公司小伙伴给我推荐了个传说中的天池机器学习算法大赛(赛题链接:机场客流量的时空分布预测),说要参加下试试。作为一名名声在外的机器学习叶公好龙宗师,我内心一开始是拒绝的……妈蛋我也就上了几个课会调用调用MLlib的水平啊,这怎么突然就要来真枪实弹了,还以公司名义组了个队,这有点虚……正好那阵子业务开发也比较忙,就一直搁置着……
转眼到了10月中旬,正好有个下午无心干活,又想起了这个比赛,反正新手嘛,谁不是在被虐中成长起来的,要不就来天池划个水试试吧。说干就干,下载了数据,起了个Jupyter notebook,开始……学习pandas……
虽然之前没参加过比赛,不过上过几门课还是了解一些大致的流程。首先看下比赛提供的原始数据,主要就是5张表:
- 机场中700多个WIFI AP点每分钟的详细连接数。这个也是最后需要预测的值。初赛比较简单,只需要预测某一天下午15-18点之间每个AP点每10分钟的平均连接数,总共大概是13590个预测值。
- 机场每天的航班排班表,其中有航班号,预定起飞时间和实际起飞时间。里面有不少缺失值。
- 机场所有登记口和机场区域的关联表。WIFI AP的Tag上有机场区域信息,如E1, W1, T1, EC之类,而航班表里都是登机口比如B225,这个表就是用来做关联的。
- 机场每天的乘客checkin记录表,包括航班号,起飞时间和checkin时间。根据我自己坐飞机的经验,这个应该指的是值机?感觉值机时人不一定要在机场,而且数据本身也有很多缺失。
- 机场每天的乘客安检记录表,同样包含了航班号,安检时间。这个感觉会靠谱一些,虽然同样数据也有很多缺失。两张乘客表里的乘客ID也都有提供,不过两个表用的ID体系不同,无法关联。试着distinct了一下发现ID没有重复的,也就是说无法通过ID来确定某个乘客,基本就是无用的信息。
有了原始数据,就开始搞探索性分析。嗯,看看咋导入数据,要读取csv嘛……pandas.read_csv就可以了!果然简单!(省略各种pandas库方法的各种google搜索学习……)然后查看下数据质量啦(有没有缺失值异常值),画画图看看有啥分布规律啦,看看统计关联度啦等等……这块是我的弱项,可能因为本身数学功底比较差,对于画图也不是很有sense,所以也没有什么特别的发现。第一天基本就在pandas和matplotlib的基本使用学习中度过了。晚上试着跑了个平均值,作为第一次预测结果提交了。
10月15号,第一次结果揭晓,竟然排到了200名以内!(当时总参赛队伍有2000多)简直不敢相信……搞个平均值就能进10%,这比赛真是对新手太友好了……
10月16号,继续学习pandas,做了些其它的分析比如乘客一般会在预定起飞时间前多久来机场过安检,飞机的平均延误情况如何,机场每天的航班排布是不是比较接近,然后略微改进了下简单的平均,做了下花式加权平均,进行了第二次提交。然后就冲到了100名附近。感觉自己势不可挡,已然站在了世界之巅木哈哈……


10月17号,既然平均效果都这么好了,那要不试试ARIMA之类的经典时序预测?又学了下statsmodels库,看了下ARIMA模型需要序列stationary……好吧那做下一阶差分。然后模型拟合需要设置auto-regressive和moving-average的参数,这有点懵逼……随便瞎猜了下可能的回归周期,发现这个跑起来又慢效果也不怎么好,可能更适合长期粗粒度时间序列的预测吧……所以也就暂时没有采用。不过移动平滑这个好像是个不错的主意,继续加入到原先的加权平均模型中,做了第三次提交,貌似名次没什么变化……
10月18号,这天好像是换了数据,初赛只剩下最后6次提交了……这天花了非常多的时间,看了好些Kaggle winner's solution,开始上模型了!(后来才知道我之前用的那些平均之类的方法被大家称之为“规则”,很多情况下规则方法就可以达到不错的成绩了)添加了航班数量的feature,加上之前的时间点平均,滑动窗口,一阶差分等等,用sklearn搞了个GBRT模型!离线验证下效果也不错,信心满满进行提交!果然成绩一出,冲到了第6名……当时的感觉就是,一个能打的都没有啊!(摇手指

10月19号,这天继续疯狂地学习着各种比赛经验,以一种王者的姿态哈哈哈,把玩我的模型们。唔,原来随机森林这种bagging为基础的ensemble方法是主要降低variance的,所以每棵树的深度不能太小,否则bias会过大……而gradient boosting主要降低bias,所以每棵树不能太深太细……唔,原来做模型融合不只有简单的加权平均,还可以在模型基础上做stacking……期间借鉴了很多Kaggle前辈们在github和Kaggle kernels上的代码,不得不表示Kaggle的分享氛围真的是非常好啊!像我这样首次参赛的新手也瞬间变得一招一式有板有眼起来……不过当天快到提交了还没跑完grid search,只能随便填了个估计参数上去预测了,又是自信爆棚提交结果!没想到评测成绩反而大幅下降……妈蛋,我是不是拿错剧本了……


10月20号,此时的我已经杀红了眼,前一天肯定是under fit了!于是我开启狂暴模式,除了自己本本还用了几台公司的虚拟机进行并发模型超参数grid search。这里犯了不少错误,比如很多时候特征工程,数据清洗之类的要远比复杂的模型重要,有了基本模型之后花太多时间做超参数搜索其实也是非常浪费时间,而且数据量(应该做一下down sampling)和模型复杂度上去之后,跑一个简单的cross validation都需要几个小时,而提升很可能并不大。最要命的是,真正比赛时的cross validation方法其实是很讲究的,而我只是很傻很天真地使用了random split……结果就是凄惨的over fit,离线效果很好,上线效果傻逼。这还不是最悲催的,那天几乎是通宵作战,到起床收训练结果的时候才发现,模型预测时需要依赖前几个时间点的数据,而在预测集里面这些值都是未知的,必须得边跑预测边把预测值填进去进行下一个点的预测,这些feature的权重还都相当高。早上6点多发现问题,7点多改完程序后一直跑到10点(每天系统评分的时间点)结果还是没有出来。所以那天就相当于提交了个全0的结果,浪费了一次宝贵的验证机会……


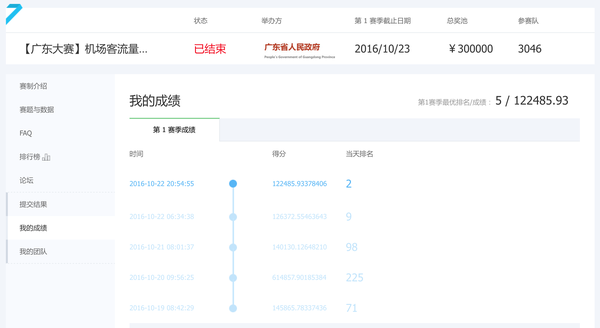
10月21号,倒数第三天了,我终于静下心来研究总结了一下前面成绩下降的原因,其实是模型over fit而不是under fit,而且CV的方法也与线上评测不一致导致预估结果过于乐观。思考一下接下来的战术选择,一条战线是完善之前的树模型,用上xgboost(这货比sklearn带的GBRT快了不止一点点,果然是大杀器)跟random forest和extra trees做混合,用一个2-fold stacking,第二层采用线性回归。然后超参数调优也学乖了点,用上了效率更高一些的bayersian optimization。Feature方面完善了下时间(数据中包含了中秋节,做了点特殊处理),AP点位置等信息,pandas的get_dummies做one hot encoding相当清爽,一行代码搞定。最终模型的feature数大概是60来个,训练提交完之后成绩终于止血回升,不过名次还是在40名左右。(由于提交次数有限,还有很多想法没法在比赛中验证。赛后对这条战线做了些进一步的优化,将第一次几个模型的预测结果作为feature加入到原来的训练数据中来做第二层的模型训练和预测,最终成绩可以排进前20。)
10月22号,受到几个Kaggle分享的启发,对几个分类分别建立模型训练很可能比对整体数据建一个大模型训练效果要好,于是加了条新战线,打算对AP点做下归类然后分别建模。看了下貌似有Dynamic Time Wrapping做时间序列的距离函数效果不错,结合KMeans做clustering,然后用xgboost里拿到的权重比较高的几个feature,对几个cluster分别建线性模型来做预测(也是受了一位KDD Cup大神的影响,她说她赢了3届KDD,用的都是线性模型,给跪了),训练预测速度比树模型们快了不少。Validation方法也改成尽量跟线上一致的预测一段连续时间的值。尝试了下L1,L2模型正则化,混合一下做了提交。这天的结果到了12名。(看我的语气,简直风淡云轻!)
10月23号,最后一天了,进复赛应该很稳,心态也更加平和了……这天也是进入倒计时后难得的早早地在晚上9点就提交结果了,其它几天基本都是晚上通宵跑模型,早上6,7点起来看结果,做提交。这天主要是看了下各天数据的相关度,果断去掉了前面一大段的时间,只用最后一周的数据来做训练。然后用elastic net来替代之前的手动L1,L2混合,略微调整了下超参数,就提交了。



当然,这些结论都是在不了解深度学习的我看来如此的……在比赛过程中我经常感觉我做的很多人肉工作比如特征选取完全可以由auto-encoder来替代,而不断提交结果不断改进模型的行为,也像极了一个SGD+BP优化过程。我还在寻找自己作为一个人类的独有价值所在……
总结归纳下整体的比赛“套路”:
- 首先理解赛题,读清楚需要提交答案的内容和格式。比赛中还是有不少选手因为没提交符合要求的csv文件导致评测出问题的。
- 然后要做好探索性分析,理解业务逻辑,为后面各种特征构建和建模思路做准备。比如本次比赛中从探索分析时就能发现机场每日的航班安排都比较接近,且很多连接点的历史数据都具有很相似的pattern,因此可以用一些简单的规则达到不错的预测效果。
- 数据清洗也很重要,不过在比赛中原始数据有限定,很多数据质量低的数据集基本没有很好的办法去填充缺失值,所以这块主要还是过滤掉缺失异常值的做法比较多。
- 接下来构建特征是影响最终结果占比非常大的部分了。这里一是要仔细,很多时候想法很好,但代码实现错了,导致成绩没有提升,既伤士气,又会影响路线选择的判断。因此写代码实现特征过程中一定要时刻注意验证,写一个小的处理函数就配上一个简单的测试用例看下数据跑出来对不对,养成良好习惯绝对会为整体比赛进程节省不少时间。不要到很后面才发现特征建错了推倒重来。另外一点就是要有想象力,learning rate一开始要狂野一些,一个方法思路不奏效就果断尝试下其它实现,不要被困死在局部最优上。
- 做feature本身耗时耗力,所以开始几天完全可以边做feature,边用简单的规则进行预测提交,不要浪费线上评测的机会嘛!顺便也可以摸摸底,看看真正线上测试集的大致情况,后面很多所谓的“经验值”调优都依赖这些“提交测试”。在整个比赛过程中,真实的评测成绩都是很重要的输入信息,尽量不要浪费。而且大多数时候想法都要比验证机会多,好好规划提交策略。
- 做模型的部分应该是很多初学者,比如我,最喜欢花时间的地方了。不过越到后面越发现其实模型影响并不是决定性的,质量好的数据,构建合理的特征,用线性回归跑跟用GBM跑很可能差距并不太大。用GBM的默认参数跑跟用花了很大力气搜索出来的“最优参数”跑可能也不会有特别大的提升,更别提后面加了新feature可能还要重新搜索……所以这部分的调优完全可以放在比赛中后期再搞。当然如果用深度学习之类……可能情况会不太一样?需要花很多功夫在网络结构上……我也没搞过哈哈。
- 尽量建立完善的离线验证体系,如果能做到离线验证有效果提升,上线也能同步提升,那就再好不过了。当然很多时候是达不到的,只能尽量去接近这个目标。就拿本次比赛来说,如果只用简单的随机split做cross validation,效果要比线上那种连续预测未来3小时的未知值效果好很多。所以后面我还是采用了预测同样3小时连续时间点的方式来做,尽量选取当天pattern接近的3小时,或者前几天同时间段的3小时来做。做离线验证时也要注意不要在训练时不小心把要验证的数据也扔进去训练了……哈哈,新手易犯。
- 最后嘛,多看看别人的比赛分享,从相似的赛题中寻找灵感,不要连着写代码太久,效率降低而且出错率也会变高。注意劳逸结合,毕竟比赛基本上都有1个月的时间,搞不好哪天洗澡时想出一个好的特征就逆袭了呢!
嗯,这样看上去总算切题了一些!
附几个当时看到的不错的学习资源:
某Kaggle大神的参赛示范代码:ChenglongChen/Kaggle_CrowdFlower
Kaggle某次类似时间序列预测比赛的赛后分享和讨论:Walmart Recruiting - Store Sales Forecasting
Phunter大神分享的比赛脚本模板:Flavours of Physics: Finding τ → μμμ
来自北大的著名天池选手的github(初赛第二名):wepe (wepon)
跟上面的大牛一起组队的另一只大牛的博客:DataCastle微额借款用户人品预测大赛冠军思路
ensemble必读:http://mlwave.com/kaggle-ensembling-guide/
xgboost调参指南:https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/
复旦小鲜肉的Kaggle比赛指南:https://dnc1994.com/2016/04/rank-10-percent-in-first-kaggle-competition/
时间序列特征提取库:https://github.com/blue-yonder/tsfresh
一篇关于训练数据量对结果影响的论文:http://web.mit.edu/vondrick/bigdata.pdf
后面还有第二赛季,有空再写吧。
