CNN网络的设计论:NAS vs Handcraft

训练Convolutional neural network (CNN) 时,一般都会先选定一个知名的backbone (比如说ResNet-50),再依照需求从中调整出平衡效果与效能的架构。很多时候,这个调整的概念是相当依赖经验 (感觉) 的,需要通过大量的阅读与实践的经验来培养。
CNN的发展中有过许多经典架构,可以分为人为设计(Handcraft)与网络搜索(NAS)两个方向。人为设计上,从早期的LaNet、AlexNet到近期知名的VGG、Inception、ResNet、MobileNet等等,每种网络的提出都包含了作者对于网络架构的见解。而网络搜索则是通过neural architecture search (NAS) 直接找出最佳的网络架构。本篇文章会借由EfficientNet与RegNet,分别是近年NAS与人为设计的巅峰,分享一些关于CNN网络设计与调整的观点。


本篇文章讨论 convolutional neural network的设计方法,从特征图宽度、分辨率与深度意义与 scaling开始,再从介绍 NAS (EfficientNet)与 handcraft的设计过程 (RegNet),最后讨论两者之间的关系。这篇文章主要重点在于网络架构设计的讨论,不单单是 EfficientNet或 RegNet的介绍。
推荐背景知识:convolutional neural network (CNN)、neural architecture search (NAS)、EfficientNet、RegNet。
1 CNN基本设计框架
CNN的网络设计多半包含三大部分:
- convolution layer抽取spacial information;
- pooling layer降低图像或特征图分辨率,减少运算量并获得semantic information;
- fully-connected (FC) layer回归目标。
随着时代的改变,虽然pooling layer时常被较大stride的convolution取代,global average pooling与1x1 convolution也时不时代替了FC layer,这个大思路依然是大致没变的。
1.1 Stem -> Body -> Head
在网络架构的无穷可能性中,即使要使用neural architecture search (NAS) 爆搜一波,也难免显得困难。在近期的CNN架构发展,可以看出常见的CNN架构可以被切成三个部分:
- Stem: 将输入图像用少量的convolution扫过,并调整分辨率度。
- Body: 网络的主要部份,又可分为多个stage,通常每个stage执行一次降低辨率度的操作,内部则为一个或多个building block (如residual bottleneck)的重复组合。
- Head: 使用stem与body提取的feature,执行目标任务的预测。
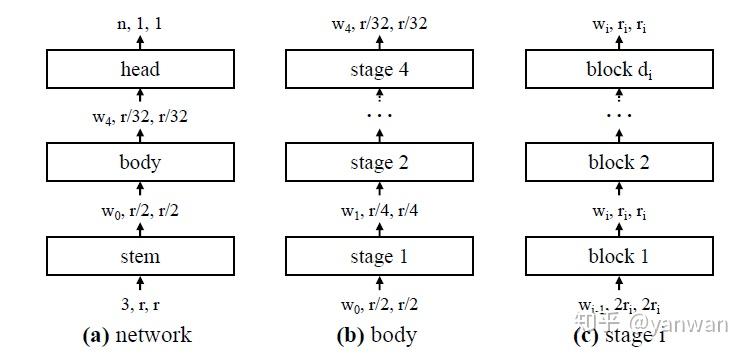

其实并不是所有 CNN都遵循这样的框架,只能说是常见的框架。
1.2 Building Block
Building block也是一个很常被使用的术语,指的是那些被不断重复使用的小网络组合,比如说ResNet中的residual block、residual bottleneck block [1]又或是MobileNet中的depthwise convolution block [2] 与reverted bottleneck block [3]。
除了上述以外,设计 convolutional neural network当然还有许多可以调整的细节: shortcut的设计 (如 FPN [4])、receptive field的调配等等。不过为了比免冗长繁杂、不在这篇文章讨论。
了解了CNN网络的概念后,我们先考虑一个问题:假设有一个已知的框架,如何依照需求加大或压缩这个网络呢?
2 Scale An Existed Structure
在不大幅改动主架构的情况下,一般常调整的项目就是以下三种:
- 深度D (depth):代表从输入到输出,堆叠的building block或convolution layer的数量。
- 宽度W (width):代表该building block或convolution layer输出feature map的宽度 (channels或filters数)。
- 分辨率R (resolution):代表该building block或convolution layer输出feature map张量的长与宽。
3 单独强化其一
在深度方面,我们相信越深的网络可以捕捉越复杂的特征,并且带来更好的泛化 (generalization) 能力。然而,过深的网络即使使用skip connection [1] 与batch normalization [5],仍然容易因梯度消失 (gradient vanishing) 导致不易训练 [6]。
在宽度方面,一般来说越宽的网络可以捕捉到更细节 (fine-grained) 的信息,并且容易训练 [6]。然而,宽而浅的网络却是难以捕捉复杂的特征。
在分辨率方面,高分辨率无庸置疑的可以得到更多细节信息,在大多的论文中基本上都是提升performance的好法宝。显而易见的缺点就是运算量,然后在localization问题需要调整、匹配的receptive field。
以下是EfficentNet论文提供单独增加深度、宽度与分辨率上的实验。从实验上可以看出,单独增强其中一项对效能的提升都是有效的,但是很快这个效果就会饱和。


3.1 Compound Scaling
基于单一强化的实验,EfficientNet的作者认为应该要一起考虑强化深度、宽度与分辨率三项。然而,在一定的运算量设定下,如何决定调整这三项之间的调整比例则是一个开放的问题。
考量到同样提高深度、宽度与分辨率两倍增加的运算量其实不同 (增加深度两倍,会增加运算量两倍;增加宽度或分辨率度两倍,则会增加运算量四倍)。论文提出的compound scaling是考量运算量增加的比例,以规划 (programming) 定义最佳化问题,再使用一个小的grid search近似最佳解。


现在,我们了解了CNN网络的概念,也了解了怎么依照需求,从网络宽度、深度与分辨率放大或缩小一个已知的CNN网络。那现在的问题回到了:怎么去找一个好的网络架构呢?然深度学习已经在很多领域超越了人为的知识,那是不是也可以让机器自己设计类神经网络的架构呢?这个问题就是近期很热门的研究题目:neural architecture search (NAS)。
4 Neural Architecture Search (NAS)
虽然号称神经网络的自动搜索,但NAS也不是无敌的万事通,NAS的实作一般需要定义三个元素:
- Search Space: 定义可以选择的网络基本元素 (如convolution、batch normalization)、与可以调整的内容 (如kernel size、filter number)。
- Search strategy: 定义搜寻的方法,如reinforcement learning是其中一个常见的方法。
- Performance estimation: 定义如何评估一个架构的好坏,如准确度、运算量等等。
这篇文章不谈论 search strategy,关注放在与网络设计有关的 search space与 performance estimation。
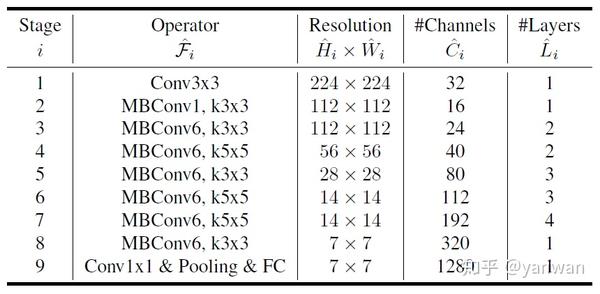
4.1 EfficientNet
EfficientNet [7] 是可以说是目前 (2020年) 移动端 (使用CPU计算) 最强的网络架构。EfficientNet沿用MnasNet [8] 的search space,但将运算资源的估测从latency改成FLOPs,即对于某个网络 m、目标运算量 T,使用一个hyperparameter w控制accuracy与FLOPs的trade-of,最佳化Accuracy(m)*[FLOPs(m)/T]^w。
以下是MnasNet与EfficientNet的search space,大致看一下可以选择的有convolution的形式、kernel与filter size、squeeze-and-excitation [11] 的使用与参数、skip connection (shortcut)与每个block (或说stage) 的layer数目等等。
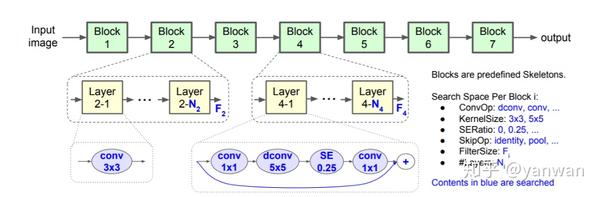

EfficientNet论文找出了一个base架构EfficentNet-B0后,依照compound scaling的原则,假设运算资源为两倍,找出了最佳的scaling parameters (α=1.2, β=1.1, γ=1.15),依照这个scaling方法 [补充3],依序推理更大的架构EfficentNet-B1到EfficentNet-B7。是现在 (2020年) 最强也最高效的网络架构之一。

好了!我们知道了NAS是如何找到一个好的网络架构。那么如果是人类要怎么去找一个好的网络架构呢?
5 Handcraft Design with Insights
在一般的情况下,人为设计网络的流程大概是这样:先从一个大略的网络概念假设一个网络可调整范围 (design space,以NAS的术语是search space),我们会在这个空间进行大量的实验后,找到一些容易带来正效益的方向。这时候我们会依照这个方向继续进行实验,也就等同于收敛到一个更小的design space。而这样递迴地进行,就像下图从A走到B再走到C的过程。


回想一下NAS的三大元素:search space、search strategy、performance evaluation。其实人为设计与NAS根本没什么两样,只是search strategy是依照着我们自己本身的知识在进行。但这就是导致结果最不一样的地方,NAS以performance为最佳依据,擅长找到那一个最强的模型。而人为设计的过程则是观察performance,却也同时依照自己过往知识与经验的累积、每个参数代表的意义、每个增加的模块效果等等推测方向,因此找出来的通常一种方向并且带有某些insight。
或许有些人会觉得类神经网络就是个黑盒子,许多 insight都是为了发论文牵强解释出来的,但如果没有这些 insight,我还真不知道怎么去改变一个网络。
5.1 Analysis of design space
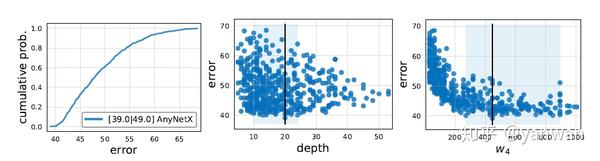
事实上,如何严谨地定义带来正效益的方向不是一件简单的事情。在”Designing Network Design Spaces” [9] 这篇论文中将这优化网络架构的过程以系统化的整理并分析。作者使用sample的方式,在定义的design space中分析这个design space中model的错误分布 (论文称为empirical distribution function, EDF),藉以找出带来正效益的方向。

5.2 RegNet
RegNet是”Designing Network Design Spaces”论文中通过分析EDF找出来的网络,以下分享作者搜寻RegNet design space的过程,从中可以感受一个网络架构被设计的过程。
由于网络的design space其实是个几乎无穷大的范畴,就像一般研究人员会有个initial model (如ResNet),论文先定义了一个广泛的但非无穷大的design space,AnyNet + X block = AnyNetX。
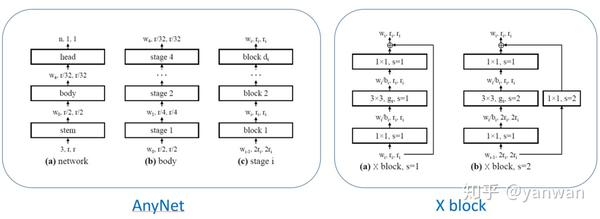

AnyNetX承袭了CNN的大部分精神,是一个类似ResNet 的template,将网络分为stem、body 、head,搜寻过程以body为主。而body分成4个stage,一开始输入的分辨率为224x224,每个stage的一开始都会降分辨率为一半。在可控参数部分,每个stage各有4个自由度:block数量 (b)、block宽度 (w)、bottleneck ratio (b)、group convolution的宽度 (g),总共16个自由度。
依照论文定义的分析方法,每次搜寻都会sample出N=500个合理的模型,并且使用EDF分析其优劣。因此design space从起始的AnyNetX_A依序推论到AnyNetX_E [补充 5],而这之中发现的重点为:
- Bottleneck ratio与group convolution的宽度在stage间共用分析出来的结果几乎一样,因此推论在stage间共用参数不影响结果。
- 宽度、block数 (深度) 随着stage递增在分析上明显提升效果,因此推论这是好的设计方向。
经过了简化推导,AnyNetX剩下6个自由度的design space,即为RegNetX。6个维度包含:模型深度 d 、bottleneck ratio b 、group convolution的数量g、网络宽度增加的目标斜率w_a、宽度增加的区间倍率w_m 、以及初始宽度 w_0 。
宽度增加的区间倍率 (width multiplier) 与网络宽度增加的目标斜率 (width slope) 听起来有够拗口,其实是我自己以意义来翻译。因为即使看原文也容易摸不着头绪,实际意义大概是这样:目标斜率是一个固定的数值定义每个 block的宽度要如何增长,而区间倍率则是一个方便取整数的倍率,可以操作让每个 block 的宽度不要跳的那麽乱,也可以在每个 stage内将重複的 block 设计为一样的宽度。
根据分析一些热门的网络架构,论文进一步限制RegNetX的design space:bottleneck ratio b = 1、block深度12 ≤ d ≤ 28 、宽度增加的基本倍率w_m ≥ 2 。为了进一步优化model的inference latency,RegNetX额外限制了参数量与activation数:假设FLOPs数为f,限制activation数#act ≤ 6.5 sqrt(f) ,限制参数量#param ≤ 3.0+5.5*f 。
那麽人为找出来的网络,可以与NAS找出来的一较高下吗?
6 Handcraft vs NAS
我认为现阶段的NAS的许多设定 (比如说search space) 还是靠着人的智慧在设定,这代表NAS还是必须先借镜许多handcraft的insight。另一方面,人类也会试图从NAS找出来的架构中得到一些insight。因此,NAS与handcraft目前可以说是相辅相成的。
NAS的优势在于找出对于任务最优势的架构,然而极强的目的性也带来了泛化性的不确定 (会不会找出over-fitting的架构) 。这也是为什么EfficientNet论文除了证明其架构在ImageNet上的强大,还额外花了一些篇幅展示他的transfer到其他classification dataset的能力。不过,即使transfer到其他同dataset可行,transfer到其他任务或许又是另一个问题。
事实上, EfficientNet在其他视觉任务中,不论是 object detection或是 semantic segmentation中已经展现了强大的能力 [10],泛化能力乍看无懈可击,不过这个评比是建立在 "同量级的 FLOPs" 最优先的基准下。
NAS的另一个问题就是可解释性比较差。比如说RegNet在sample并演化架构的过程中发现了渐渐增加的网络宽度是好的设计,然而EfficientNet一开始就来了一个宽度从32到16的压缩。虽然EfficentNet结果就是如此优秀,这样的一个难解释的设计却也增加了理解与修改的困扰。
不过说句老实话,这些缺点都有些吹毛求疵,NAS就是一个最佳化的结果,在于拥有运算资源的情况下,可以大幅减少人力实验的苦工,优势自然是明显的。人为设计的模型则是在提供insights方面显得卓越,毕竟作为一个研究人员,仅仅知晓是无法创造未来的。
“Any fool can know. The point is to understand.” ― Albert Einstein
至于 EfficientNet与 RegNet孰优孰劣,大概也没有个绝对。从论文数据来看,低运算量的模型还是 EfficientNet有优势,但由于 EfficientNet的 depthwise convolution与 activation数量对GPU运算较不友善,在有 GPU的情况 RegNet的运算速度可以比同样 FLOPs数的 EfficientNet快上数倍。
好了~这篇文章就先到这边。老话一句,Deep Learning领域每年都会有大量高质量的论文产出,说真的要跟紧不是一件容易的事。所以我的观点可能也会存在瑕疵,若有发现什么错误或值得讨论的地方,欢迎回覆文章一起讨论 :)
Reference
[1] Deep residual learning for image recognition. [CVPR 2016]
[2] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. [arXiv 2017]
[3] MobileNetV2: Inverted Residuals and Linear Bottlenecks [CVPR 2018]
[4] Feature Pyramid Networks for Object Detection [CVPR 2017]
[5] Batch normalization: Accelerating deep network training by reducing internal covariate shift. [ICMC 2015]
[6] Wide residual networks. [BMVC 2016]
[7] EfficientDet: Scalable and Efficient Object Detection [ICML 2019]
[8] MnasNet: Platform-aware neural architecture search for mobile [CVPR 2019]
[9] Designing Network Design Spaces [CVPR 2020]
[10] EfficientDet: Scalable and Efficient Object Detection [ECCV 2020]
[11] Squeeze-and-Excitation Networks [CVPR 2018]
更多内容请关注公众号:AI约读社,期待与您的相遇!
